批处理已死,Kafka 当道
Posted MacTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了批处理已死,Kafka 当道相关的知识,希望对你有一定的参考价值。
题图:by kacozi from Instagram
本文源自 Confluent 的 CTO 和联合创始人 Neha Narkhede 在旧金山 QCon 上的一次演讲,描述了 Kafka 对实时流计算的支持。关于流计算,我之前写过一篇文章「」,大家可以参考。
什么是 Kafka?Apache Kafka 是 LinkedIn 开源的分布式消息系统,在 LinkedIn 目前每天处理几十万亿条的消息,并且已经部署到了世界范围内成千上万的组织之中,包括财富 500 强的公司。基本上成了一种工业标准。
在旧金山 QCon 会议上,Neha Narkhede 曾做了「ETL 已死,而实时流长存」的演讲,并讨论了企业级数据处理领域所面临的挑战。该演讲的核心是开源的 Apache Kafka,这个流处理平台能够提供灵活且统一的框架,支持数据转换和处理的现代需求。
Narkhede 在演讲中首先阐述了在过去的十年间,数据和数据系统的重要变化。该领域的传统功能包括用来存储的关系数据库(OLTP)和用来分析的数据仓库(OLAP)。具体来说就是,来自关系型数据库或其他 NoSql 数据以批处理的方式加载到数据仓库中进行分析,批处理运行的周期可能是每天一次或两次。这种数据集成过程通常称为抽取 - 转换 - 加载(extract-transform-load,ETL)。事实上我们以前做企业软件开发的时候大都是这么做的,转换包括数据格式转换和数据清洗、修复等。
最近的一些数据发展趋势推动传统的 ETL 架构发生了巨大的变化:
1、单服务器的数据库正在被各种分布式数据平台所取代。
2、除了事务性数据之外,现在有了类型更多的数据源,比如日志、传感器、指标数据等,其实就是各种不同类型的大数据。
3、流数据得到了普遍性增长,相对传统的批处理,对速度和频率的要求更高更快。
这些趋势所造成的后果就是传统的数据集成方式最终看起来像一团乱麻,比如组合使用各种自定义脚本、ESB、MQ 以及像 Hadoop 这样的批处理技术。
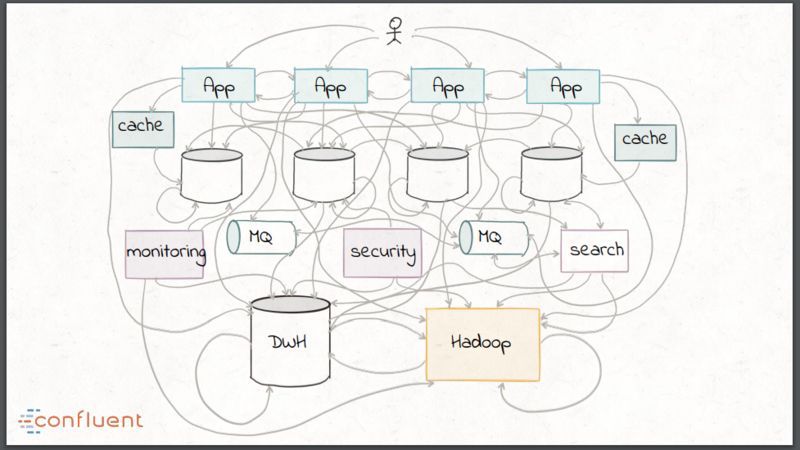
在数据处理和分析领域,传统 ETL 有什么缺点呢?
1、数据的清洗和管理需要手工操作并且易于出错;
2、ETL 的操作成本很高,一般比较慢,并且是时间和资源密集型的;
3、ETL 所构建的范围非常有限,只关注于以批处理的方式连接数据库和数据仓库。
在实时 ETL 方面,早期采用的方式是 EAI 方式,使用 ESB 和 MQ 实现数据集成,虽然这是有效的实时处理,但这些技术通常很难规模性扩展。这给传统的数据集成带来了两难的选择:实时但不可扩展,或者可扩展但采用的是批处理方案,不能实时。
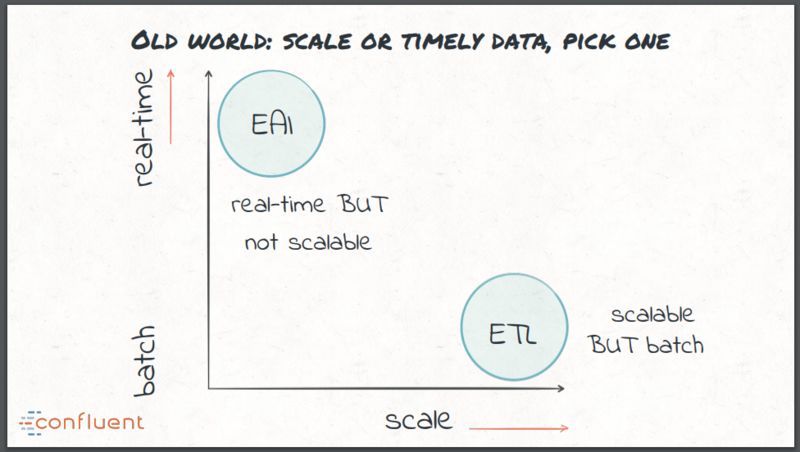
现代流处理对数据集成有什么新需求呢?
1、能够处理大量且多样性的数据,毕竟我们是大数据时代了。
2、平台必须要从底层就支持实时处理,这会促进向以事件为中心的根本转变。事件是核心。
3、必须使用向前兼容的数据架构,必须能够支持添加新的应用,这些新的应用可能会以不同的方式来处理相同的数据。插件技术。
这些需求开始推动一个统一数据集成平台的出现,而不是一系列专门定制的工具。这个平台应该能够容错、能够并行、支持多种逻辑语义、提供有效的运维和监控并且允许进行模式切换和管理。这个平台就是 Kafka。Kafka 是七年前由 LinkedIn 开发的,能够作为组织中数据的中枢神经系统来运行,方式如下:
1、作为应用的实时、可扩展消息总线,不再需要其他 EAI 技术;
2、为所有的消息处理目的地提供现实状况来源的管道;
3、作为有状态流处理微服务的基础构建块。
Apache Kafka 为应用集成提供了一个可扩展的消息骨干网(backbone),能够跨多个数据中心。
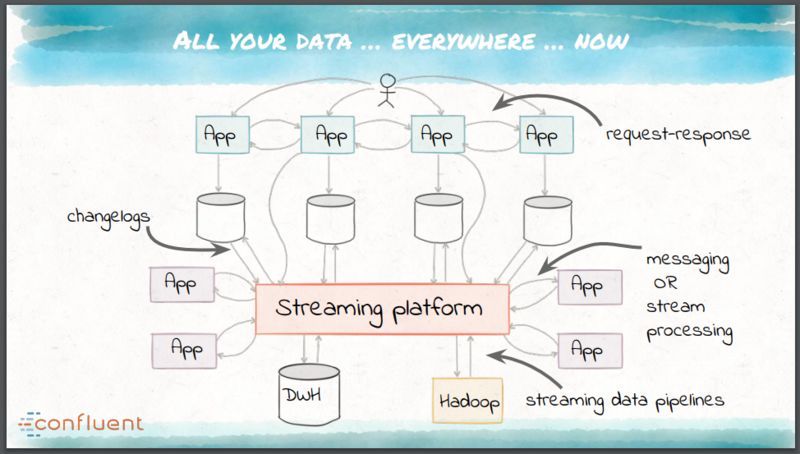
Kafka 的基础是 log 的理念,log 是只能往上追加(append),完全有序的数据结构。log 本身采用了发布 - 订阅(pubsub)的模式,发布者能够非常容易地把不可变的数据往 log 上追加,订阅者可以维护自己的指针,以便处理当前的信息。
Kafka 能够通过 Connect API 构建流数据管道,也就是 ETL 中的 E 和 L。Connect API 利用了 Kafka 的可扩展性,基于 Kafka 的容错模型提供了一种统一的方式监控所有的连接器。流处理和转换可以通过 Kafka Streams API 来实现,相当于 ETL 中的 T。使用 Kafka 作为流处理平台不需要再为每个目标定制抽取、转换和数据清洗的需求。来自源的数据经过抽取后可以作为结构化的事件放到平台中,然后通过流处理进行任意转换。
如图所示:
Narkhede 最后详细讨论了流处理的概念,也就是流数据的转换,并且提出了两个相互对立的愿景:实时的 MapReduce 和事件驱动的微服务。实时的 MapReduce 适用于分析用例并且需要中心化的集群和自定义的打包、部署和监控。Apache Storm、Spark Streaming 和 Apache Flink 实现了这种模式。Narkhede 认为事件驱动微服务的方式(通过 Kafka Streams API 来实现)让任何用例都能访问流处理,这只需添加一个嵌入式库到 Java 应用中并搭建一个 Kafka 集群即可。
Kafka Streams API 提供了一套方便的 DSL,具有像 join、map、filter 和 window 这样的操作符。
这是真正的每次一个事件(event-at-a-time)的流处理,没有任何「批处理」操作。它使用数据流(dataflow)风格的方式,基于事件的时间来处理后续到达的数据。Kafka Streams 内置了对本地状态的支持,并且支持快速的状态化和容错处理。它还支持流的重新处理,在更新应用、迁移数据或执行 A/B 测试的时候,都非常有用的。
Kafka 的 log 方式统一了批处理和流处理,log 可以通过批处理的方式进行消费,也能在每个元素抵达的时候进行检查以实现实时处理,从这个角度而言,Apache Kafka 提供了一种新的「ETL」处理方式,大家可以在工作实践中尝试应用。
如果你也在通过 ETL 处理数据,现在是时候研究一下 Kafka 了。
回复「幻灯片」,获取本文中提到的 keynote。
以上是关于批处理已死,Kafka 当道的主要内容,如果未能解决你的问题,请参考以下文章