kafka 入门与实践
Posted 阿文Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka 入门与实践相关的知识,希望对你有一定的参考价值。
什么是 kafka
kafka 是 Apache 基金会下的一个开源软件,它的主要作用是用于提供分布式流处理以及消息队列服务。
其官网 https://kafka.apache.org/
最早是由 Linkedln 公司使用 scala 语言编写。
特性
解耦:作为MQ,助力微服务(传统MQ更合适)。
冗余:提供数据冗余,高可用。
扩展性:简化应用扩展。
灵活性:访问量剧增时应用仍可发挥作用,减轻后端压力。
顺序保证:保证一个分区内消息的有序性。
缓冲:数据密度较大的在线处理中缓冲数据,如物联网,网站监控等。
高速写入:磁盘顺序写,而非随机写。
高可靠性:通过zk做分布式一致性,同步到任意多块磁盘上,故障自动切换选主,自愈。
高容量:通过横向扩展,LinkedIn每日通过Kafka存储的新增数据高达175TB,8000亿条消息。
应用场景
消息队列:场景和常见MQ相似。
行为跟踪:页面浏览、搜索等,实时记录到topic中,订阅者可用来实时监控或放到hadoop/离线仓库处理。
元数据监控:作为操作记录的监控模块,记录操作信息,类似运维性质的数据监控(审计)。
日志收集:收集服务器日志,交由文件服务器或hdfs处理。
流处理:接收流数据,提供给流式计算框架使用,多用于数据密度较大场景。
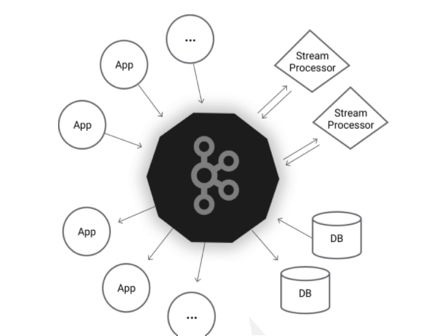
例如
分析用户行为,设计更好的广告位。
对用户搜索关键词进行统计,分析当前流行趋势。
监控用户行为,防止用户无限制抓取网站数据。
网站实时监控,获得实时性能数据,及时发出网站性能告警。
批量导入数据到hadoop/数据仓库,对数据离线分析,获取有价值的商业信息。
基本概念
Producer:消息和数据的生产者,数据向topic发布。
Consumer:消息和数据的消费者,订阅topic并处理消息。
Broker:Kafka集群中的服务器,producer->broker->consumer。
Topic:消息的分类。
Partition:topic物理上的分组,一个topic可有多个partition,partition为一个有序队列,每个 partition中的数据有序,每个消息会对应一个id(offset)。
Message:消息,通信基本单位。
流:一组从生产者移动到消费者的数据,kafka streams。
kafka 体系结构

Producer:消息的发布者
Consumer:消息的订阅者
Broker:中间的存储服务器
Producer
Producer将消息发布到指定的topic,同时producer可以决定消息归属于哪个partition,比如基于round-robin方式进行均匀分布。
可指定发布的分区,借助分区器+消息键实现消息均匀分布,可自定义分区器。
多个生产者可对应一个topic (如多个网页的监控对应一个topic)。
批量发送:Kafka producer的异步发送模式允许进行批量发送,先将消息缓存在内存中后一次性发出(对比redis pipeline),多用在流处理。
Broker
Broker进行数据的缓存代理,Kafka集群中的一台或者多台服务器统称为broker。
Broker可为消息设置偏移量。
为减少磁盘写入次数,broker会将消息暂时缓存起来,当消息的个数(或空间)达到上限时再flush到磁盘,减少I/O调用。
Broker 无状态,不保存订阅者的状态,订阅者自己保存。
Consumer
Consumer从topic订阅并处理消息。
每个Consumer属于一个consumer group,发送到topic到消息只会被每个group中的一个consumer消费。
一个topic中一个partition只会被group中一个consumer消费,但一个consumer可以同时消费多个partition中的消息。
Kafka只保证一个topic下一个partition中的消息被某个consumer消费时消息是有序的,RabbitMQ天然有序。
每个group中不同consumer间消费独立。
对于一个topic,一个group中consumer数目不能大于partition个数。
Consumer Group
对topic来说一个group就是一个”订阅者”,group作为一个整体对一个topic进行消费,不同group间独立订阅。
一个group内的consumer只能消费不同的partition。
Topic
topic可以认为是一类消息。
每个topic划分为多个pattition。
每个partiton在存储层面表现为append log,发布到partition的消息被追加到log文件结尾。
消息在log文件中的位置称为offset。
Partition
Partition是topic上的物理分组。
分区目的:将log分散到多个broker上,保证
消费效率。多个partition对应多个consumer,
增加并发消费能力。
一个topic可以分为多个partition。
每个partition是一个有序队列。
Partition中每条消息对应一个id(offset)。
Message
Message:通信的基本单位。
每个partition存储一部分message。
每条消息包含三个属性:
Offset:long
MessageSize:int32
Data:具体消息内容
Offset
Offset为消息在log文件中的位置(逻辑值)。
offset唯一标记一个partition中的一条消息,可理解为message的标识id。
消费者可将Offset可保存在zk或broker或本地。
消息的处理机制
Kafka对消息的重复、顺序性没有严格要求。
Kafka提供at-least-once delivery机制,即consumer异常后,有些消息可能会被重复的delivery。
Kafka为每条消息进行CRC校验,用于错误检测,CRC不通过的消息会被丢弃。
事务
非事务:”读取->处理->写入”中读写异步,流处理场景。
事务功能主要是一个服务端和协议级的功能,任何支持它的客户端库都可以使用它。
Kafka并未实现严格的”读取->处理->写入”的原子过程。
事务的机制主要exactly once实现,即消息只被发送一次,但目前只能保证读取的事务性,消费者一侧并未实现严格的事务性,按kafka的使用场景看也没必要实现。
安装
安装 Java
yum -y install javaKafka下载
wget -c http://apache.claz.org/kafka/1.0.0/kafka_2.11-1.0.0.tgz解压
tar zxvf kafka_2.11-1.0.0.tgz启动zk:
bin/zookeeper-server-start.sh config/zookeeper.properties
启动kafka:
bin/kafka-server-start.sh config/server.properties创建topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic1 Created topic "topic1".查看topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181启动producer:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic1启动cousumer:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic1 --from-beginningProducer发消息。
多节点:复制单节点配置文件,修改broker.id、监听端口、log路径即可。
与其他 MQ 比较
RabbitMQ:老牌MQ,应用较多,如OpenStack组件之间的通信,支持协议多,重量级消息队列,对路由、负载均衡、数据持久化支持很好,但无法适应持续产生的数据流,大量数据堆积时性能急剧下降。
ZeroMQ:号称最快的消息队列系统,擅长高级/复杂的队列,但使用也复杂,代码侵入,不提供持久化,只是一个库,相当于一个加强版的socket,与MQ区别较大。
Redis:Redis也有MQ功能,数据量小,数据大于10KB时基本异常慢,数据量小时性能优于RabbitMQ。
使用
生成者
root@vpn:~# cat producer.py
#/usr/bin/python3.5
# coding:utf-8
from kafka import KafkaProducer
# 生产者
def producer_message(topic_name):
producer = KafkaProducer(bootstrap_servers=["c-5jgvwkxjgd.kafka.cn-east-1.internal:9092"])
for i in range(10000):
message_string = "msg%d" %i
response = producer.send(topic_name, message_string.encode('utf-8'))
producer.close()
producer_message('topic1')消费者
root@vpn:~# cat consumer.py
#/usr/bin/python3.5
# coding:utf-8
from kafka import KafkaConsumer
# 消费者
def consumer_message(topic_name):
consumer = KafkaConsumer(topic_name,bootstrap_servers=["c-5jgvwkxjgd.kafka.cn-east-1.internal:9092"])
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
consumer_message('topic1')以上是关于kafka 入门与实践的主要内容,如果未能解决你的问题,请参考以下文章