首发Kafka设计模式初探
Posted 海数据实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了首发Kafka设计模式初探相关的知识,希望对你有一定的参考价值。
【导读】
本内容总结自TalkingData资深大数据研发工程师杨林强先生在2017年6月10日海数据技术沙龙第33期所分享的内容。
在Linkedin,Kafka用来处理活动流和运营数据处理管道。
1. 以时间复杂度为o(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
2. 高吞吐。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
3. 支持Kafka Server间的消息分区及分布式消息。
4. 同时支持离线数据处理和实时数据处理。
5. Scaleout:支持在线水平扩展。
解耦: 系统之间解耦
冗余: 有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失,插入-获取-删除
扩展性: 提高程序的扩展性
灵活性&峰值的处理能力: 在访问量剧增的情况下,应用仍然需要继续发挥作用)
可恢复性: 系统的一部分组件失效时,不会影响到整个系统。
顺序保证性
缓冲
异步通信
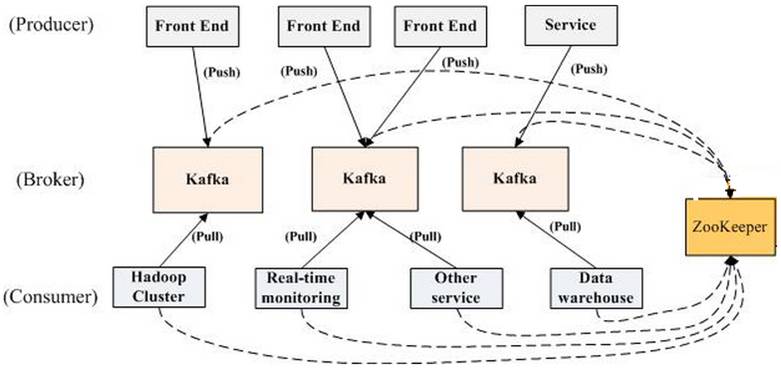
上图描述了一个Kafka集群中包含若干个Producer(如网页浏览量或者是服务器日志),若干个broker,若干个Consumer Group,以及一个Zookeeper集群,Kafka通过Zokkeper集群管理配置,选举leader,以及在Cosumer Group发生变化时进行rebalance,Produce使用push模式将消息发布到broker,Consumer并订阅使用pull模式从broker订阅并消费消息。
名词解释:
•Broker: Kafka集群包含一个或多个服务器,这种服务器被称为broker
•Topic: 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
•Partition: 物理上的概念,每个Topic包含一个或多个Partition.
•Producer: 消息生产者•Consumer: 消息消费者
•Consumer Group: 每个Consumer属于一个特定的Consumer Group
消息发送时都被发送到一个topic,而topic由一些Partition Logs(分区日志)组成。每个Partition的消息是有序的,生产的消息被不断最佳到Partition logs。
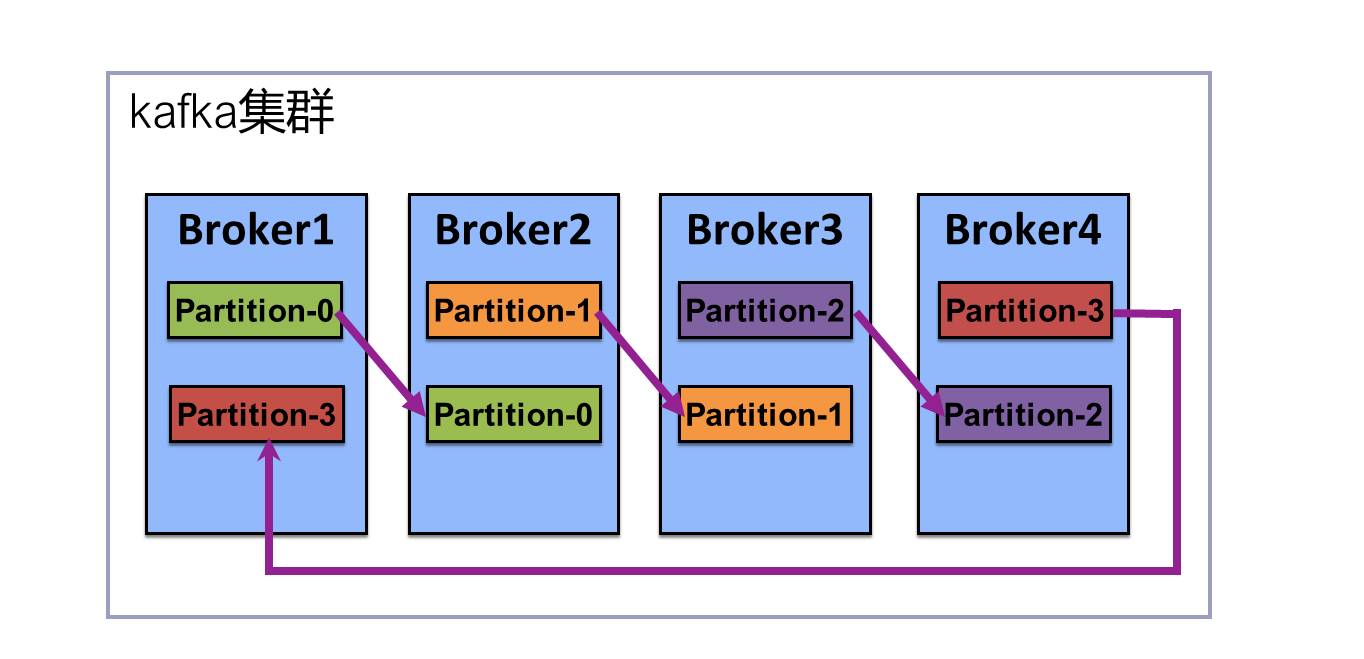

我们可以设置topic的partition:
1. 在配置文件中设置num.partitions属性,配置新建topic额partition数量。
2. 创建Topic时通过参数指定。
3. Topic创建之后通过Kafka提供工具修改。
分配Replica算法:
将Broker(size=n)和待分配的Partition排序
将dii个partition分配带第(i%n)个Broker上
将第i个Partition的第j个Replica分配到底((i+j)%n)上Broker上
Kafka Replication的数据流如下图:
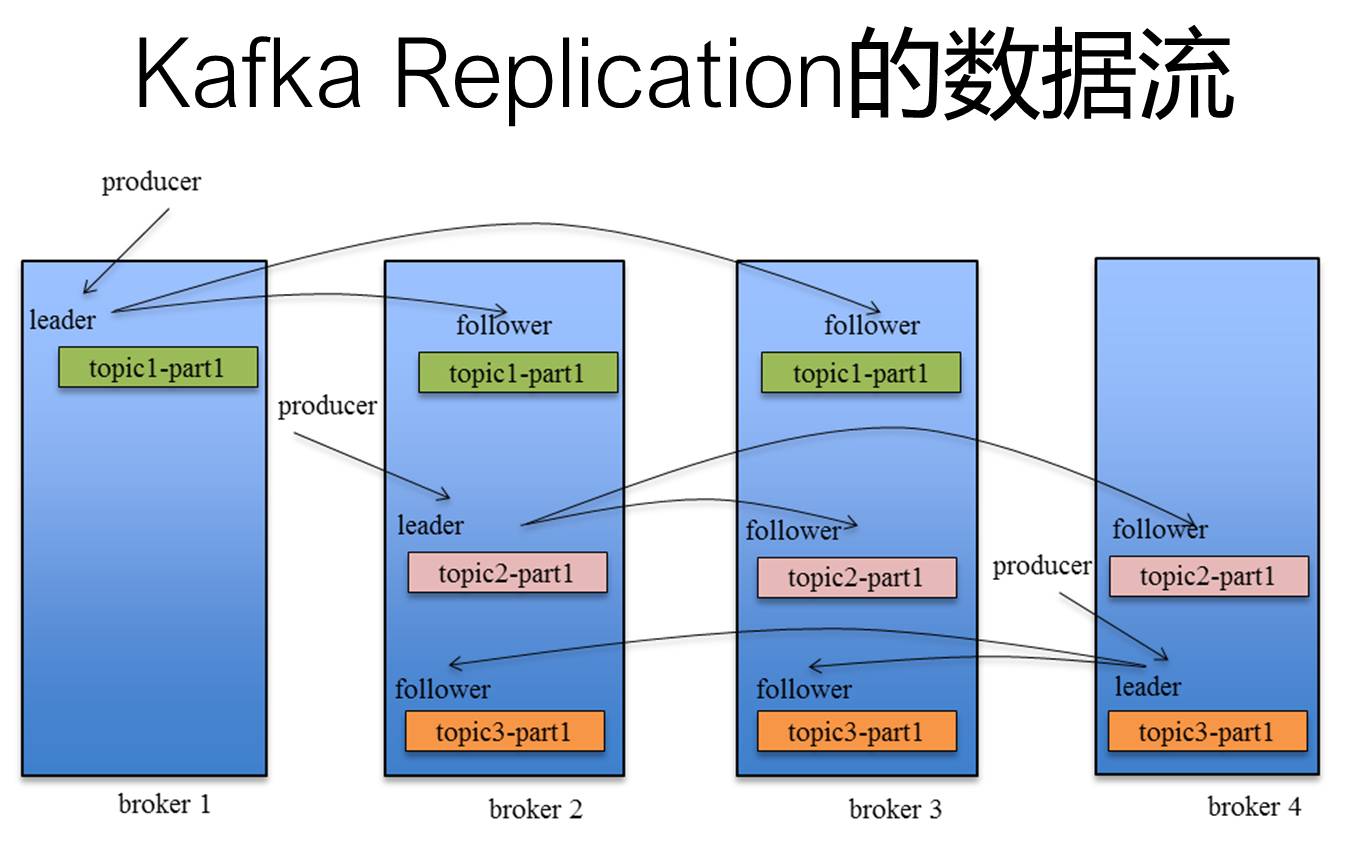
Kafka的Replication需要解决的问题:
1、每个Replication怎么传送消息?
在向Producer发送ACK前需要保证多少个Replica已经收到该消息
怎么处理某个Replica不工作的情况?
怎么处理Failed Replca恢复回来的情况?
2、ACK前需要保证多少个备份?
Leader会跟踪与其保持同步的Replica列表,该列表称为ISR(即in-sync Replica),如果一个Follow落后太多(指Follower复制的消息落后于Leader后的条数超过预定值(replica.lag.max.messages=4000))或者Follower超过一定时间(replica.lag.time.max.ms=10000)未向Leader发送fetch请求,leader从ISR列表中将其移除。
Leader Election(选举)
在所有broker中选出一个controller
Controller在Zookeeper注册Watch
有Broker宕机,Controller读取该Broker上所有的Partition在zookeeper上的状态
选取ISR中的一个Replica作为leader
ISR列表中的Replica全挂,一个幸存的Replica作为leader
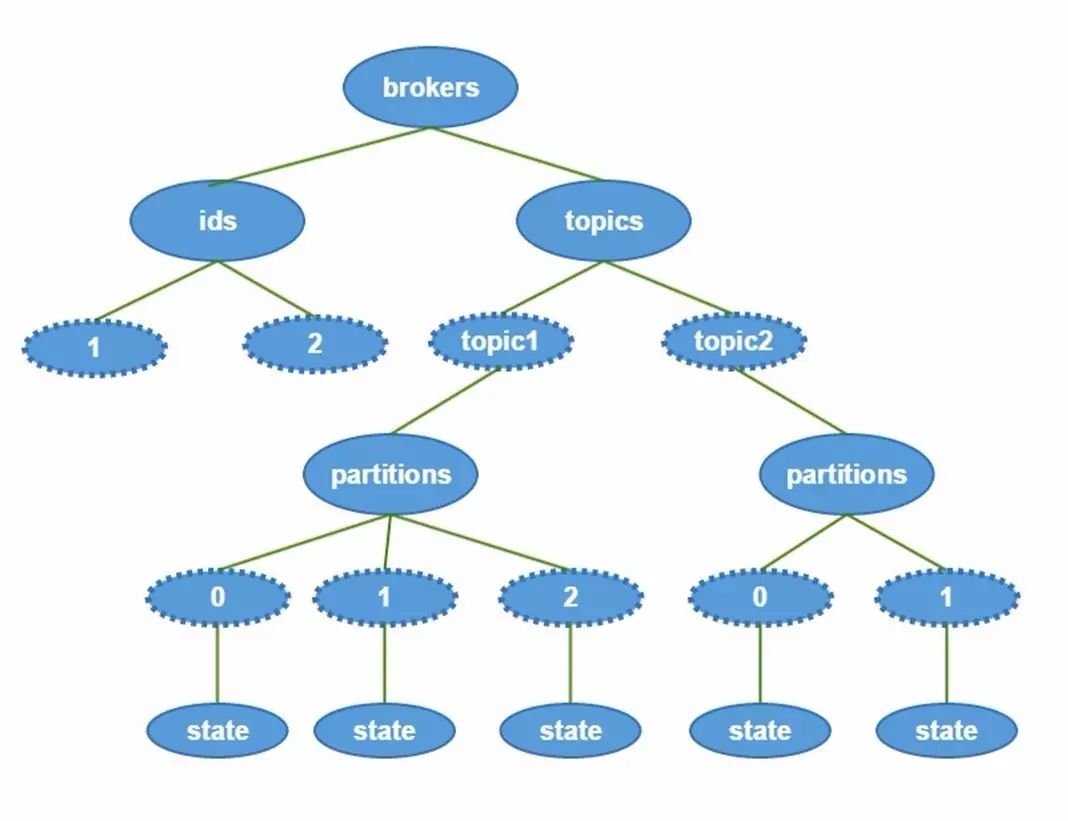
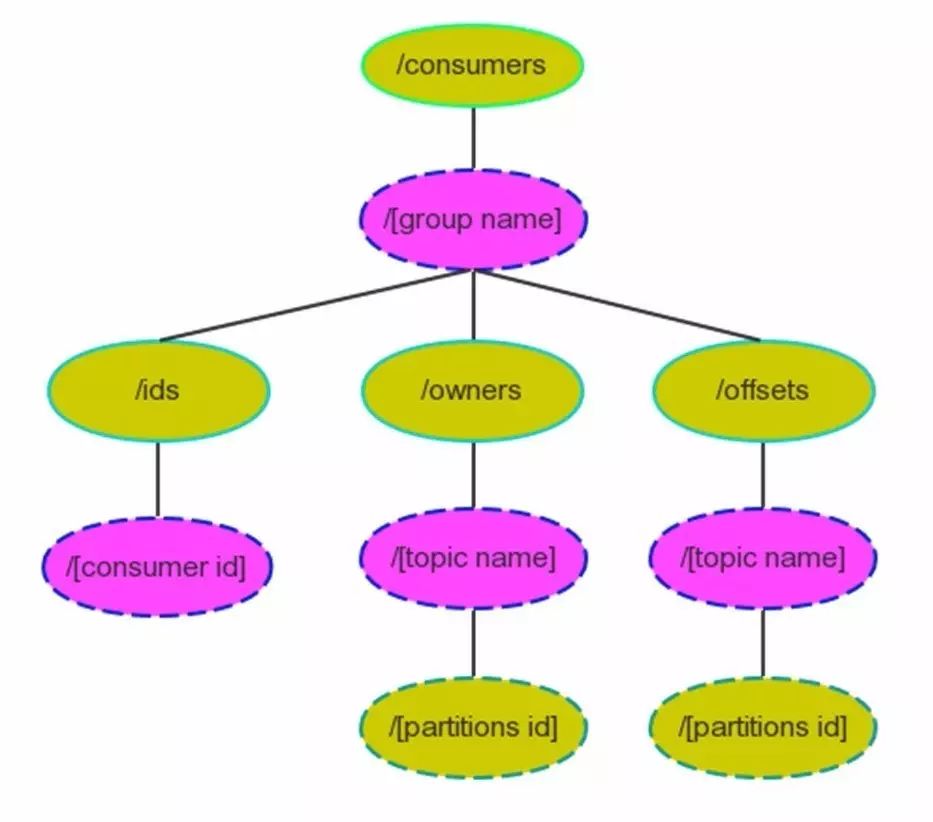
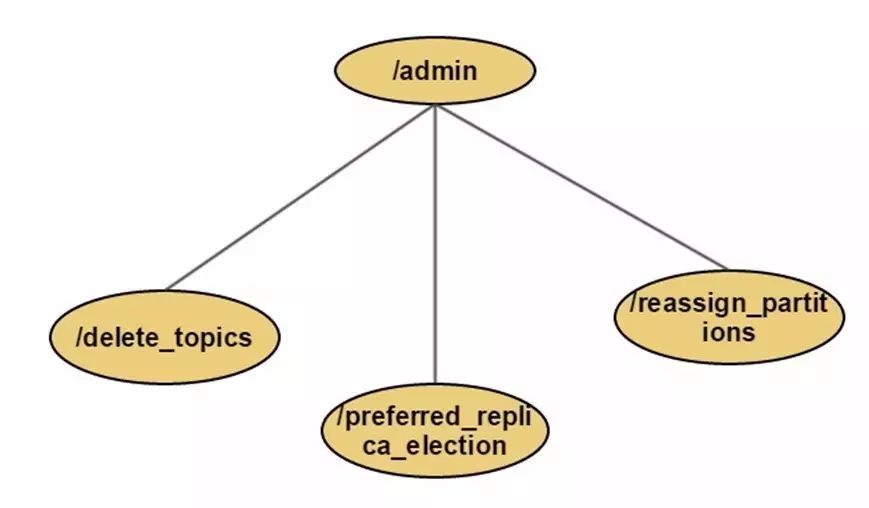
在zookeeper目录结构
Producer消息路由
消息均匀分布到不同partiiton
发布消息是可以通过key指定partition

Kafka deliveryguarantee(传送保证)
At most once消息可能丢失,绝不会重复传输At least one消息不会丢失,可能会重复传输
Exactly once每条消息肯定会传输一次且传输一次,这也是用户想要的。
delivery guarantee(传送保证)
默认是At least once
设置Producer异步发送实现At most once
Producer可以用主键幂等性实现Exactly once
Produce请求被认为完成时的确认值request.required.acks=0
0:不等待broker的确认信息,最小延迟
1:leader已经接受了数据的确认信息,Replca异步拉取消息,比较折衷
-1:ISR列表中的所有Replica都返回确认消息
Min.insync.replicas=1至少有1个Replica返回成功,否则product异常
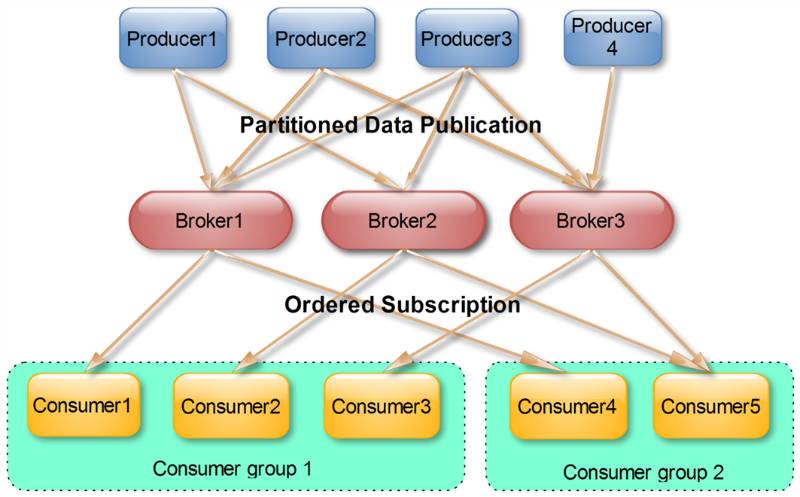
这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。用Consumer Group还可以将Consumer进行自由的分组而不需要多次发送消息到不同的Topic。
Consumer消费原则
同意Topic的一条消息智能被同一个Consumer Group内的一个Consumer消费
多个Consumer Group可消费同一条消息。
Consumer的delivery guarantee(传送保证)
• 读完消息先commit再处理消息, 设置autocommit
• 读完消息先处理再commit
• high level API,offset存于Zookeeper中
• low level API的offset由自己维护
High LevelConsumer Rebalance
Consumer Rebalance的算法
将目标Topic下的所有Partirtion排序,存于PT
对某Consumer Group下所有Consumer排序,存于CG,第i个Consumer记为Ci
N=size(PT)/size(CG),向上取整
解除Ci对原来分配的Partition的消费权(i从0开始)
将第i∗N到(i+1)∗N−1个Partition分配给Ci
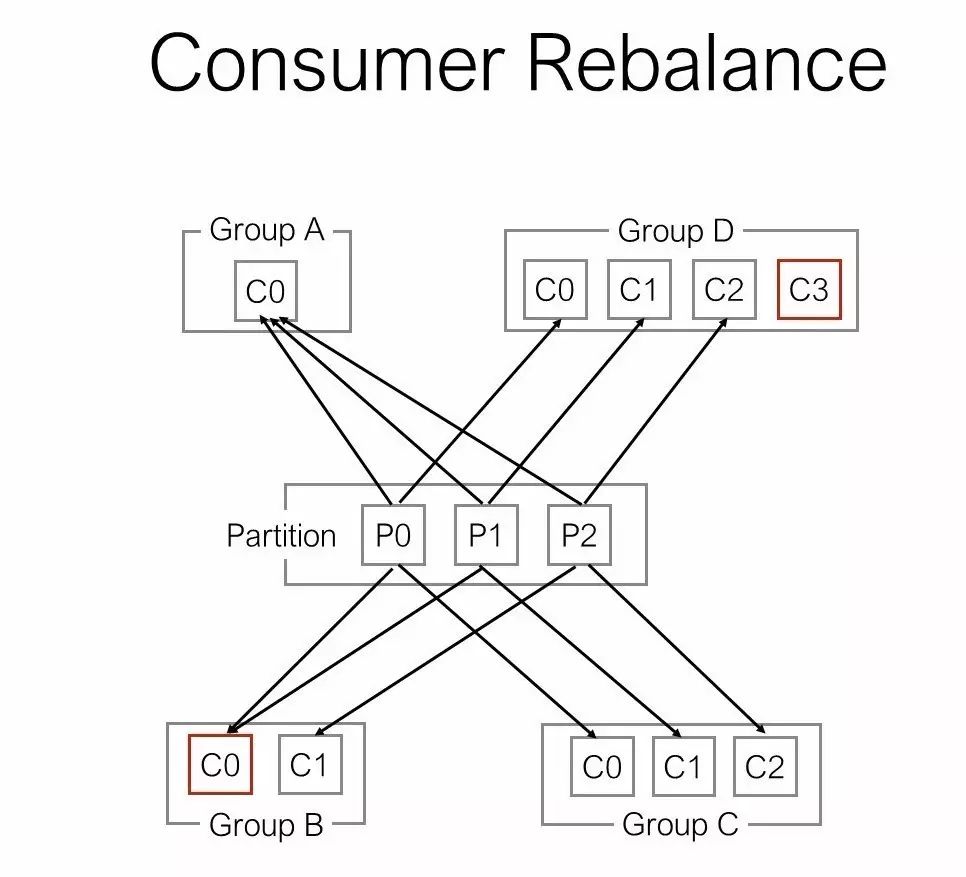
目前,最新版(0.8.2.1)Kafka的ConsumerRebalance的控制策略是由每一个Consumer通过在Zookeeper上注册Watch完成的。
每个Consumer被创建时会触发 ConsumerGroup的Rebalance,具体启动流程如下:
High Level Consumer启动时将其ID注册到其Consumer Group下,在Zookeeper上的路径为/consumers/[consumer group]/ids/[consumer id]
在/consumers/[consumer group]/ids上注册Watch
在/brokers/ids上注册Watch
如果Consumer通过Topic Filter创建消息流,则它会同时在/brokers/topics上也创建Watch
强制自己在其Consumer Group内启动Rebalance流程
Consumer Rebalance的触发条件
Consumer增加或删除会触发Comsumer Group的Rebalance
Broker的增加或减少都会触发Consumer Rebalance

问答交流
1.业务下是如何知道所有消息顺序的消费?
有两种方法,第一种方法是单个partition,第二种方法是Producer,如第二种方法,在producer消息路由中,对某数据有顺序性要求,A,B,C三个关键字的消息是顺序性的,先取hasCode(),再取余,A的数据顺序地都落在一个partition里面,B的数据顺序地都落在一个partition里面,C的数据顺序地都落在一个partition里面,不同partition不能保证消息顺序效性。
2.TalkingData公司使用kafka跑数据的情况?
公司的数据跑一天的时间,单台服务器上的数据量是40T,group上磁盘的数据是400T,公司有十几个group,只动了一个topic,里面还有很多topic,迁移或扩容partition的时候把老的数据迁过来,在0.8版的时候迁移很慢。消息落后,同步不及时的时候是不会切换过去的,实时同步达到一致才能做切换,写的比较快,量比较大的时候实时性保证起来还是比较快的。看是要性能还是数据的一致性,有的时候采取折中的方案。
3.业务上用到kafka的时候遇到什么坑?怎么解决?
数据可能会丢,因为量的原因,刚开始的时候设计ACK,每一个broker出现问题,假死了,kafka partition切换leader,partitiion的副本是2,leader没有跟上,leader挂了,会选取副本的leader,副本的数据和leader数据没有保持一致,就是丢了几条,没有及时同步,ack设置成-1就可以避免这个问题,保障写消息队列的时候所有的patitioner副本都写成功了,我们认为写成功了,才认为消息写成功,为了提高效率,设置成0。

【嘉宾介绍】
杨林强先生,资深java工程师,对kafka和elastic search有深入的研究。曾在 折800技术部java架构组任职。现负责talkingdata数据分析线研究探索实时流 数据的处理。
本文为海数据社区原创作品,未经授权不得转载,转载请与海数据小秘书联系
长按扫描上方“海数据学院”二维码获取更多资讯
以上是关于首发Kafka设计模式初探的主要内容,如果未能解决你的问题,请参考以下文章