如何将业务数据实时集成到Kafka?
Posted HVRSoftware
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何将业务数据实时集成到Kafka?相关的知识,希望对你有一定的参考价值。
一般提到Kafka很多人会浮现出2个词, 大数据和流计算。 作为由Apache软件基金会开发的一个开源流处理平台,Kafka是一种高吞吐量的分布式发布订阅消息系统,目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
通过Kafka发布和处理的消息大多数情况下采用的数据格式是JSON或者AVRO, 但实际上Kafka可以支持任意格式消息, 只要消息的订阅者程序能够解读和处理即可。 之所以JSON会这么普遍应用, 主要是由于其是一种轻量级的数据交换格式,采用完全独立于编程语言的文本格式来存储和表示数据。 简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
HVR将数据集成到Kafka的时候, 默认采用的也是JSON格式, 并且在定义Kafka的时候,还可以跟数据源特征,自动创建对应的主题。 例如下面的例子里,默认的主题名称为{hvr_tbl_name}, 表示每个不同的表名对应发布到Kafka上对应名称的主题里。 用户也可以很方便的对主题名加上其它变量或者前后缀, 便于数据的发布和消费。
作为集群, Kafka的每个节点都有一个broker(缓存代理), kafka中支持消息持久化的,生产者生产消息后,Kafka不会直接把消息传递给消费者,而是先要在broker中进行存储,持久化是保存在Kafka的日志文件中。broker是无状态的, Kafka采用基于时间的SLA, 消息保存一段时间后(通常为7天)会被删除。 HVR在配置Kafka目标是, 可以配置多个broker。
当把生产系统数据库中的业务变化数据实时集成到Kafka的时候, 由于数据的存储和消费的机制不同,源库上所做的update/delete操作,并不能在Kafka上实现, 所以通常采用时间戳的机制, 对每个message添加操作类型(hvr_op)和时间戳(hvr_cap_tstamp), 为了唯一标记message,还可以加上统一的序列号(hvr_integ_key)。 这样即使由于系统故障或者服务重启,导致一些数据重复发布到Kafka中, 订阅者也可以根据这个序列号判断是否已经处理过, 重而防止数据重复或者丢失。
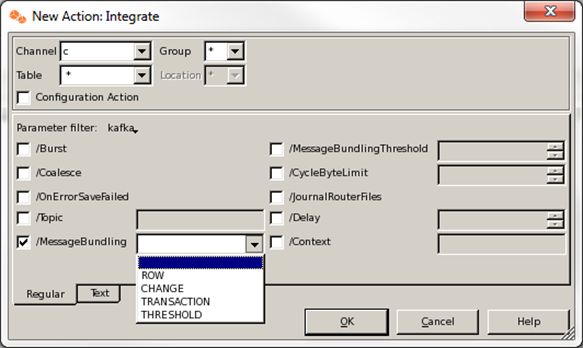
发布到Kafka的数据, HVR可以采用不同的Bundle策略(如上图所示)。
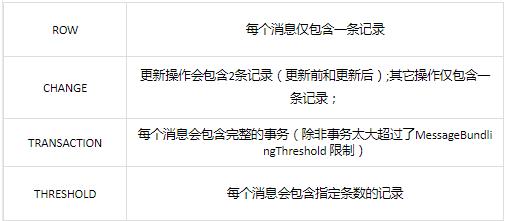
此外, HVR预置了6种不同的JSON格式:

不同的格式和bundling策略, 会有不同的性能体现:(下面是一个小型测试环境下的比较)
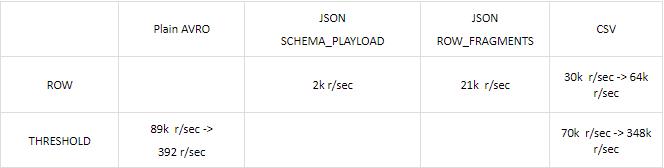
由上面可以看出, 由于Schema_Playload能够给出最为详尽数据格式描述(schema,table和column名称), 导致其message长度大大超过Row_Fragments, 所以性能上会差很多; 而Threshold方式由于一个消息里包含多条记录信息, 数据吞吐量又会大大优于Row的方式。
下面我们就来看看我最近一次做的测试情况:
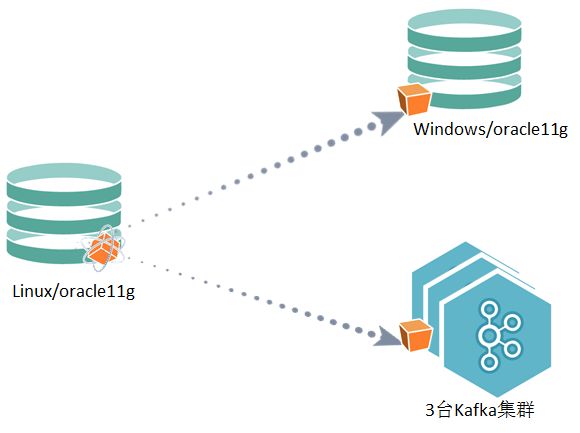
数据从一台linux上的oracle11g(12core,16G内存)实时复制到一台windows上的oracle11g(32core,64G)和一个3节点的Kafka集群(16core,128G)。
基本配置如下图:
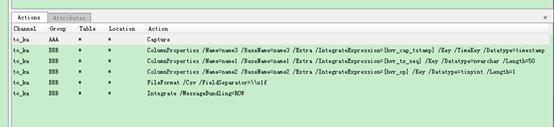
其中对每行记录添加了3个字段(hvr_op, hvr_cap_tstamp,hvr_tx_seq),用于标记捕获记录的操作类型,时间戳和事务号。 bundling方式为ROW, 也就是每个消息仅包含一条记录。消息格式按照客户要求采用了CSV格式。
压力测试,我们选择了一个有33个字段, 数据类型都是varchar2(4000)的表, 数据从生产上取出批量插入30万条记录。 此时所有复制作业处于暂停状态;
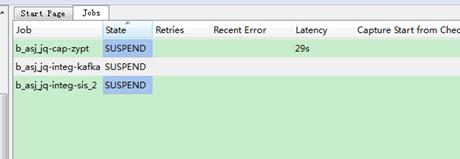
待插入完成后, 启动复制作业,观察其性能。
捕获端日志显示
写入端日志显示
结果说明:捕获速度1.1万/秒,写入速度从时间间隔上看出大概3.3万/秒写入Kafka。网络传输过程的压缩率高达99.8%。
其它功能方面通过测试还验证了以下功能
源端创建表
Kafka上自动同步
源端表上增加新的列
Kafka上自动同步
源端表示删除已有的列
Kafka上自动同步
源端表上修改列的长度或者数据类型
不影响Kafka的复制
只复制指定的列
支持
特殊数据类型支持
测试并通过了blob,clob,long,varry,timestamp,nchar,nvarchar2等类型。 其中blob字段使用的是照片数据, 转换为base64编码后发布到Kafka里。
稳定性方面:
我们通过测试对一个拥有253个字段, 绝大多数字段类型为varchar2(4000)表模拟业务操作(30倍负荷)的场景, 稳定运行了一整晚;
测试过程观察HVR占用450M内存, 单个core的49.9%负载。
模拟HVR进程失败
通过kill命令杀进程的方式, 模拟。 HVR自动恢复作业,数据完全正确;
往期文章推荐:
以上是关于如何将业务数据实时集成到Kafka?的主要内容,如果未能解决你的问题,请参考以下文章