CDH 中配置Kafka 的总结
Posted 全栈思想小栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CDH 中配置Kafka 的总结相关的知识,希望对你有一定的参考价值。
在使用 CDH 集成 Kafka 过程中,遇到了各种各样的问题,不管是线上还是线下,所以,偶尔有空,便梳理一下遇到的坑。
坑一 创建和删除topic
auto.create.topics.enable
是否允许自动创建topic。如果是true,则produce或者fetch 不存在的topic时,会自动创建这个topic。否则需要使用命令行创建topic
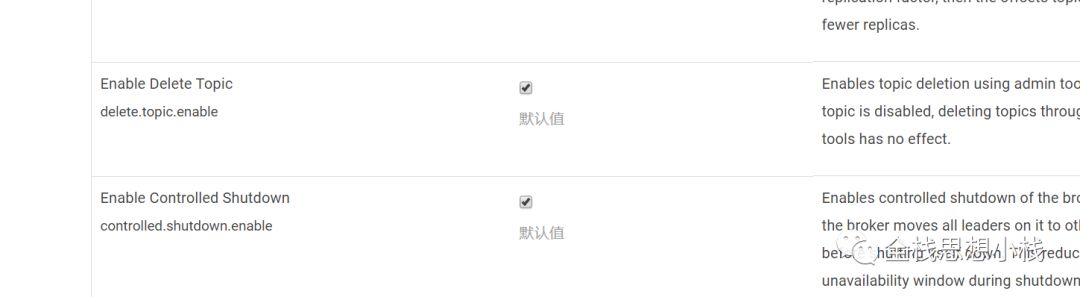
delete.topic.enable
是否允许删除topIc。不过 admin tool 则没有影响
坑二 kafka 主目录
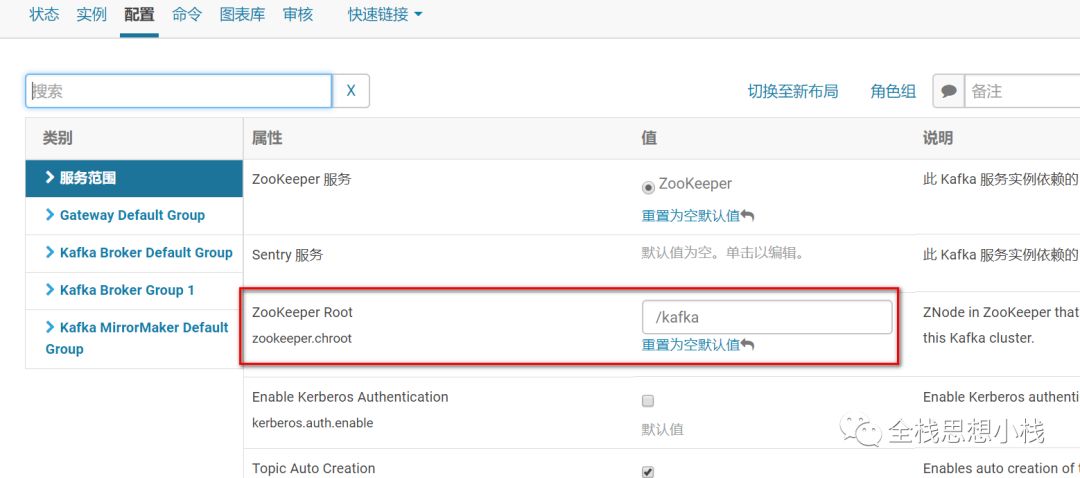
zookeeper.chroot
ZooKeeper也可以允许你指定一个"chroot"的路径,可以让Kafka集群将需要存储在ZooKeeper的数据存储到指定的路径下这可以让多个Kafka集群或其他应用程序公用同一个ZooKeeper集群。
原来的 connect string 由
hostname1:port1,hostname2:port2,hostname3:port3
变为
hostname1:port1,hostname2:port2,hostname3:port3/chroot/path
坑三 Kafka 版本的选择
查看 parcel
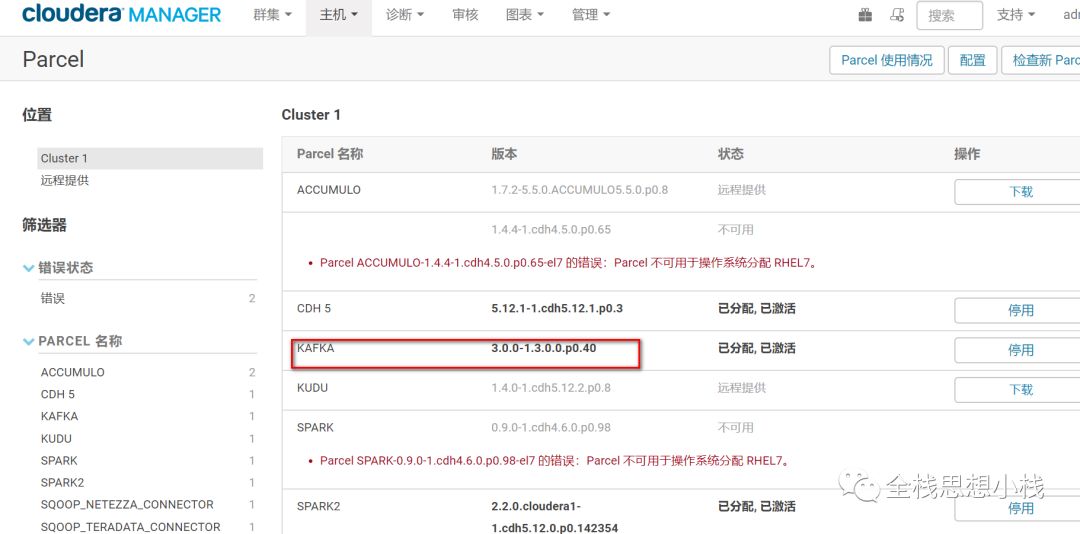
原以为这个就是Kafka的使用版本 1.3.0 。。。
和 Spark 集成的时候,则要选择相应的版本,在这里
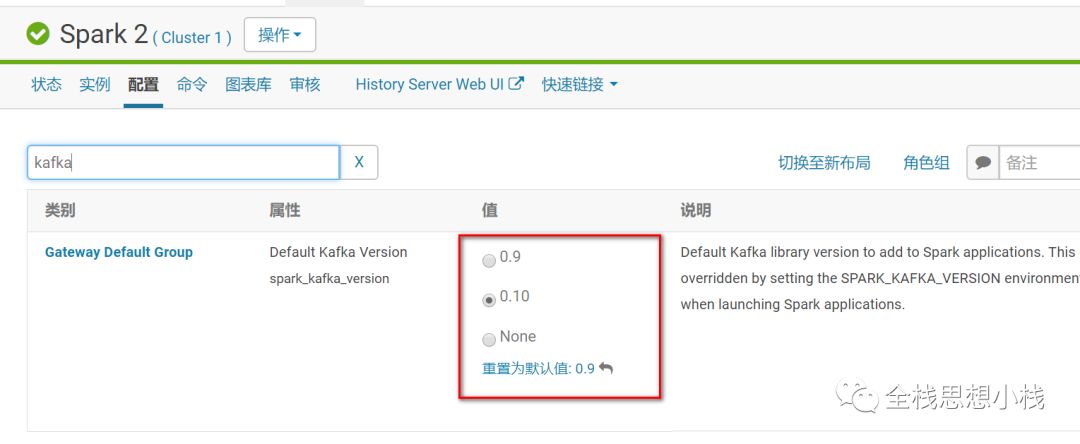
坑四 Kafka 节点Ip 的绑定
如果用内网域名绑定 Kafka , 显然 其它未设置 映射的机器 是不能解析的。比如
Error connecting to node 53 at cdh5.anji-plus.com:9092: java.io.IOException: Can't resolve address: cdh5.anji-plus.com:9092
如果用原生的Kafka , 往往有这些配置比如
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://your.host.name:9092
那么对应的 CDH 中的配置是什么呢?
找了老半天,原来是这个
绑定到Ip 便设置好了,测试环境也没发现,主要是机器少,到了AWS 才发现,原来还隐藏了一个这样的坑。
总结
Kafka 遇到的 坑基本就是这些,以后遇到新的坑再来更新。
其实,坑并不可怕,只要分析其中的问题,根据原理机制,总会有对应的解决办法,问题多,方法也多。
以上是关于CDH 中配置Kafka 的总结的主要内容,如果未能解决你的问题,请参考以下文章