如何在Rails应用程序中使用Kafka?
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在Rails应用程序中使用Kafka?相关的知识,希望对你有一定的参考价值。
有那么一段时间,我们的系统需要用到分布式流式处理和消息系统,而 Apache Kafka 似乎成了我们建立业务关键型应用程序的坚实基础。它可用于很多场景下,比如产品更新管道、订单跟踪、实时用户通知、商户账单等。
接下来的故事讲述了我们如何将 Kafka 引入到我们的 Rails 单体代码库中,内容包括技术细节、我们面临的挑战以及我们在此过程中所做的技术决策。
第一个问题是 Kafka 只提供了相对较底层的抽象。虽然这具有一定的优势,但同时也意味着客户端开发者需要面对更多的 API,需要处理更多的细节,实现一个 Kafka 客户端也因此变成了一项艰巨的任务。
作为一个基于 Ruby 的项目,我们尝试了各种使用 Ruby 开发的 Kafka 客户端,但总是碰到一些难以诊断的错误。 Ruby 缺乏并发原语,要写出一个高效的客户端并不容易。
我们通过多种方式来归避这些问题:通过独立服务来隐藏底层的复杂性,只为客户端提供最小化的 API 集合。这个服务可以使用 Ruby 以外的语言开发,所以我们就可以用上久经验证的 librdkafka,我们在其他的 Python 和 Go 应用程序中也使用过这个库。
于是,我们开发了 Rafka——位于 Kafka 前端的代理服务,并通过简单的语义和 API 把它暴露出来。它提供了合理的默认配置,为用户隐藏了很多繁杂的细节。我们选择了 Go 语言,因为它已经有一个健壮的基于 librdkafka 的 Kafka 客户端,并提供了必要的工具来实现我们需要的功能。
为了避免让客户端的开发变复杂,我们选择使用 Redis 协议的一个子集。我们所要做的只是在 Ruby 的 Redis 客户端之上添加一个层。
几天后,我们便有了一个使用 Ruby 开发的客户端,打包成一个名为 rafka-rb 的 gem,其中包含了消费者和生产者。
有了 Rafka 及其配套的 Ruby 客户端,我们的服务和 Rails 应用程序就可以轻松地从 Kafka 读取数据和往 Kafka 写入数据。
大部分开发人员的时间都花在了我们的 Rails 主应用程序上,因此,能够在应用程序内轻松使用 Kafka 消费者和生产者就变得非常重要。接下来就是让 Rails 开发人员直接用上 Kafka 消费者和生产者。
将生产者集成到现有的应用程序中其实很简单,因为即使需要使用多个主题,也只需要一个生产者。
因此,我们使用了单个生产者实例,并在应用程序初始化的时候创建它,整个代码库都使用这个实例:
# config/initializers/kafka_producer.rb
Skroutz.kafka_producer = Rafka::Producer.new(...)发送消息非常简单:
Skroutz.kafka_producer.produce("greetings", "Hello there!")使用消费者就有点不一样了,因为消费消息需要长时间运行。接下来,我们将看到如何在 Rails 代码库中通过 Rafka 来使用 Kafka 消费者。
文末提供了相关组件源代码的链接。
消费者是普通的 Ruby 对象,它们的类是在 Rails 应用程序中定义的。它们继承了 KafkaConsumer 抽象类,这个抽象类集成了用于统计的 statsd 和用于错误跟踪的 Sentry,在将来可能还会集成其他东西。它们的类名以“Consumer”作为后缀,相应的文件按照 Rails 惯例来命名。
典型的消费者看起来如下:
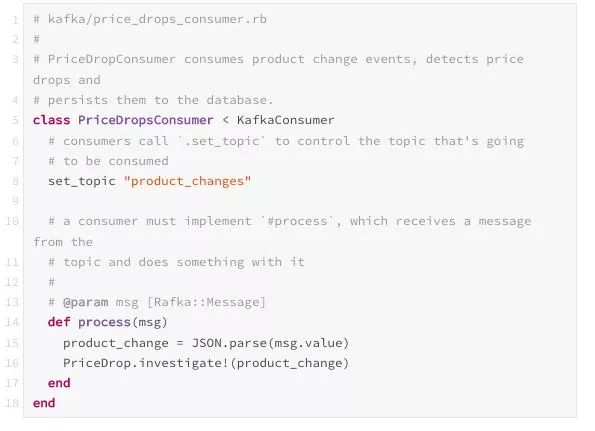
在这里,每个消费者都使用了 Rafka :: Consumer 实例。
在写好新的消费者之后,需要在配置文件中启用它:
- name: "price_drops"
scale: 2按照 Rails 惯例,消费者的名字来自类名。
关键是,所有消费者实例基本上都是独立的 Kafka 消费者,它们同属于一个消费者群组。
在部署时,Capistrano 会读取配置文件,并在服务器上创建适当的消费者实例。
这些就是开发和部署消费者所要做的事情。
下一个问题来了:如何将消费者作为长时间运行的进程?
在实现了消费者之后,下一步就是运行它们。
我们使用了一个名为 KafkaConsumerWorker 的类,这个类封装了消费者对象,并让它们成为长时间运行的进程。下面给出了这个类的简化版代码:


KafkaConsumerWorker 不断调用底层消费者的 #process 方法来循环处理消息。它还提供了优雅的退出功能。它还将消费者与 systemd 集成在一起,用以提供健壮性、活跃度检查、可见性和监控能力。
在不需要直接与 KafkaConsumerWorker 发生交互的情况下进行开发或调试也很容易:
consumer = PriceDropsConsumer.new(...)
worker = KafkaConsumerWorker.new(consumer)
# start work loop
worker.work下一步是使用 systemd 启动 KafkaConsumerWorker。我们使用了一个简单的 systemd 服务文件:
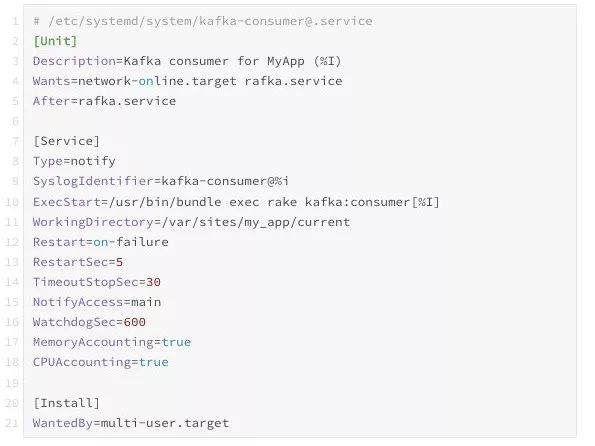
每个消费者实例使用包含消费者名称和实例编号(例如 price_drops:1)的字符串作为标识,该实例编号作为模板参数(%i 部分)传递给 systemd。这样我们就可以使用相同的服务文件生成不同的消费者实例。
将消费者与 systemd 集成意味着我们可以使用消费者内置的很多功能:
消费者管理命令(start、stop、restart、status)
在消费者发生异常时发出告警
可见性:每个消费者的状态(工作中、等待作业、已关闭)、其当前偏移量 / 主题 / 分区(使用 sd_notify(3))
自动重启失效的消费者
通过 systemd watchdog 计时器自动重启被挂起的消费者
简化的日志:我们只需将日志打到 stdout/stderr,systemd 负责处理其余部分
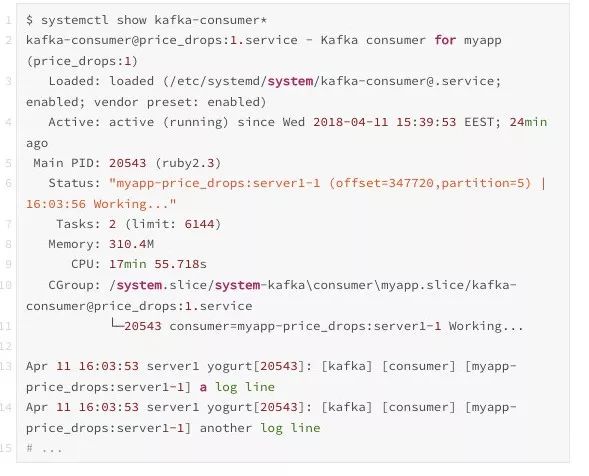
通过检查消费者实例,我们可以得到非常有用的信息输出,在出现问题时,这些信息可用于调试问题:
最后要解决的问题是,为了重启消费者,systemd 需要调用哪个命令。这个命令实际上是一个普通的 rake 任务,它将消费者设置为 worker 并运行它。
与其他组件类似,该任务的相关代码也放在 Rails 代码库中:

由于我们使用 Capistrano 进行部署,所以添加了一个 Capistrano 任务,负责停止和启动消费者。它的简化版本如下:

kafkactl 是一个包装脚本,负责执行必要的 systemctl 命令。
当有人部署应用程序时,Capistrano 会读取 YAML 配置文件并创建消费者:

在部署好消费者后,我们查看 Grafana 仪表盘,确保一切正常,同时我们也会查看 Slack,确保没有触发任何告警。
我们的 Kafka/Rails 集成基础架构包含以下组件:
Rafka:具有简单语义和最小化 API 集合的 Kafka 代理服务
rafka-rb:Rafka 的 Ruby 客户端
KafkaConsumer:一个 Ruby 抽象类,具体的消费者实现类会继承这个类
KafkaConsumerWorker:一个 Ruby 类,用于将消费者作为长时间运行的进程
kafka:consumer:运行消费者实例的 rake 任务
kafka_consumers.yml:一个配置文件,用于控制哪些消费者应该在生产环境中运行以及使用多少个实例
kafka-consumer@.service:通过调用 rake 任务生成消费者的 systemd 服务文件
它们之间交互如下图所示:
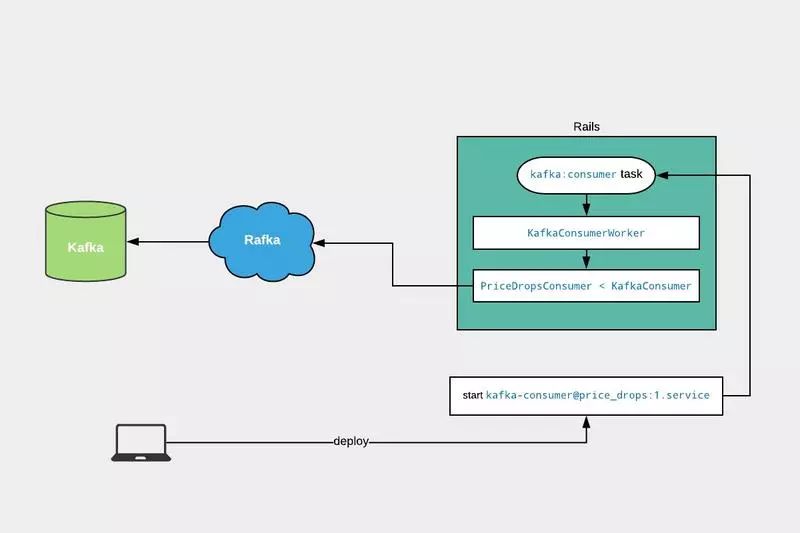
从图中可以看到,这些组件是正交分布的,无论是用于调试、测试还是原型设计,它们中的每一个都可以与其他组件的分开使用。
因为很多消费者需要执行关键任务,所以必须对它们进行充分的监控。
监控发生在各个层面,每个消费者都提供了如下特性:
当消费者失效时,Icinga 发出告警(通过 systemd)
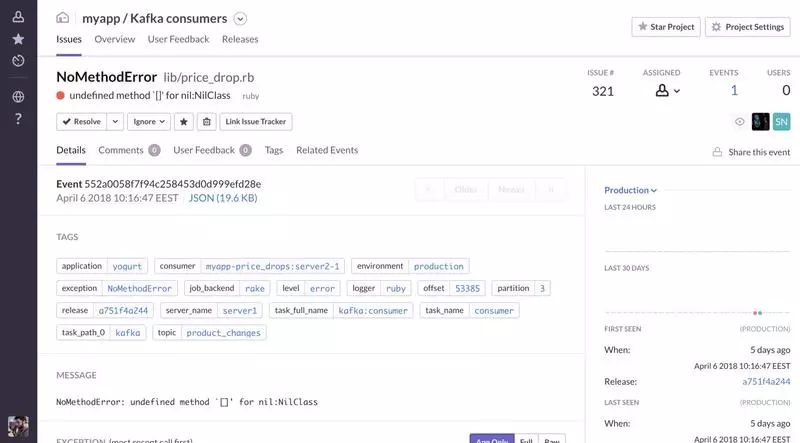
当发生异常时发出 Sentry 事件
统计:作业进程时间和消费者吞吐量(已处理消息数 / 秒)
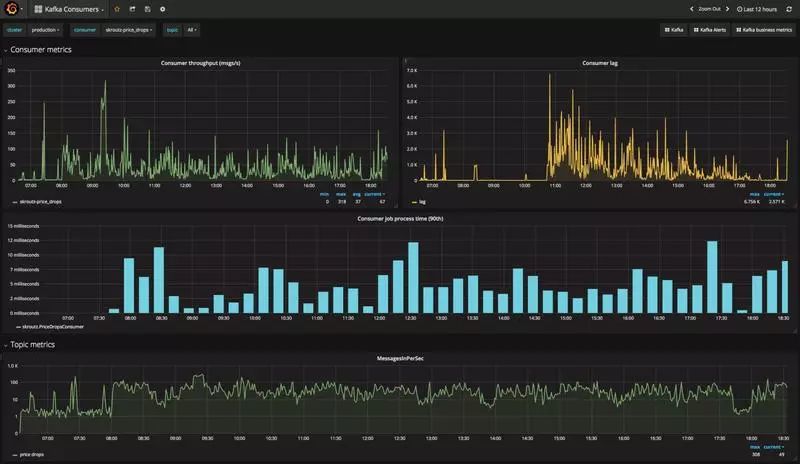
当消费者消费速度落后时(通过 Burrow 和 Grafana)
这些功能主要得益于我们使用了通用的消费者基础架构。
我们非常喜欢通过这种方式与 Kafka 进行交互,并且收到了非常积极的反馈。
通过几个简单的步骤就能开发和部署好消费者,这极大提升了开发团队的效率,而且,我们能够以一致和高效的方式基于 Kafka 开发应用程序。
将来,我们希望将本文中描述的所有组件开源出来,让其他组织也能从中受益。
最后,我们计划向 Rafka 和消费者 / 生产者基础架构中添加更多功能,包括:
批处理功能
多主题消费者
基于 KSQL 的原语(聚合、连接等)
消费者钩子(hook)
Rafka:https://github.com/skroutz/rafka
rafka-rb:https://github.com/skroutz/rafka-rb
Rails 消费者基础架构:https://github.com/skroutz/rails-kafka-consumers
原文链接可点击「阅读原文」
如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!
以上是关于如何在Rails应用程序中使用Kafka?的主要内容,如果未能解决你的问题,请参考以下文章