Key为nulll时Kafka如何选择分区(Partition)
Posted 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Key为nulll时Kafka如何选择分区(Partition)相关的知识,希望对你有一定的参考价值。
如下面图片不清晰,请访问https://www.iteblog.com/archives/1619.html,或点击下面阅读原文进行阅读。
我们往Kafka发送消息时一般都是将消息封装到KeyedMessage类中:
Kafka会根据传进来的key计算其分区ID。但是这个Key可以不传,根据Kafka的官方文档描述:如果key为null,那么Producer将会把这条消息发送给随机的一个Partition。
If the key is null, then the Producer will assign the message to a random Partition.
这句话从字面上理解是每条消息只要没有设置key(null),那么这条消息就会随机发送给一个Partition。但是代码实现是这么做的么(肯定不是,否则就没有这篇文章)?我们来看看Kafka是如何计算Partition ID的:

从上面的代码可以看出,如果key == null,则从sendPartitionPerTopicCache(sendPartitionPerTopicCache的类型是HashMap.empty[String, Int])中获取分区ID,如果找到了就直接用这个分区ID;否则随机去选择一个partitionId,并将partitionId存放到sendPartitionPerTopicCache中去。而且sendPartitionPerTopicCache是每隔topic.metadata.refresh.interval.ms时间才会清空的:
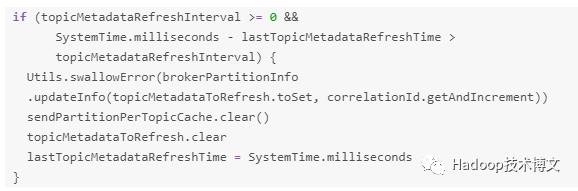
也就是说在key为null的情况下,Kafka并不是每条消息都随机选择一个Partition;而是每隔topic.metadata.refresh.interval.ms才会随机选择一次!别被文档所骗啊!
不过LinkedIn工程师Guozhang Wang解释到:本来producer在key为null的情况下每条消息都随机选择一个Partition,但后面改成这种伪随机的以此来减少服务器端的sockets数。
Originally the producer behavior under null-key is "random" random, but
later changed to this "periodic" random to reduce the number of sockets on
the server side: imagine if you have n brokers and m producers where m >>>
n, with random random distribution each server will need to maintain a
socket with each of the m producers.We realized that this change IS misleading and we have changed back to
random random in the new producer released in 0.8.2.
在Kafka new producer上如果Key为null则每条消息都会选择不同的Partition:
可以看出这是一种round-robin模式选择分区ID的。
0、回复 电子书 获取 所有可下载的电子书
1、
2、
3、
4、
5、
6、
7、
8、
9、
10、
以上是关于Key为nulll时Kafka如何选择分区(Partition)的主要内容,如果未能解决你的问题,请参考以下文章