务本kafka
Posted 珞珈之戍
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了务本kafka相关的知识,希望对你有一定的参考价值。
01
Kafka简介

定义
kafka是一个分布式的流处理平台。可以运行在单台服务器上,也可以在多台服务器上部署形成集群。它提供了发布和订阅功能,使用者可以发送数据到Kafka中,也可以从Kafka中读取数据(以便进行后续的处理)。Kafka具有高吞吐、低延迟、高容错等特点。
基本概念
Producer:生产者,用来向Kafka中发送数据(record);
Consumer:消费者,用来读取Kafka中的数据(record);
Broker:在Kafka中指部署了Kafka实例的服务器节点;
Topic:发布的消息的类别,用来区分不同类型信息的主题。对于每一个Topic,Kafka集群维护这一个分区的log,每一个分区都是一个顺序的、不可变的消息队列,并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。就像下图中的示例:
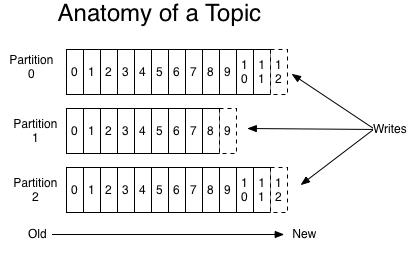
图1 topic模型
关键功能
(1)发布和订阅消息,类似于一个消息队列;
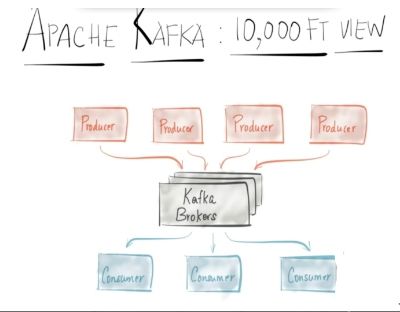
图2 Kafka发布订阅结构
producer向kafka中发送发送数据,充当发布者,consumer向kafka消费数据,充当订阅者。
(2)以容错、持久的方式存储数据;
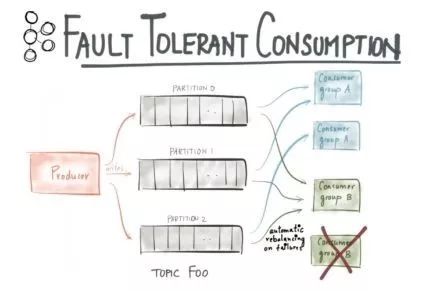
图3 Kafka容错处理
Kafka不决定如何消费数据,消费者自己决定何时,如何消费数据。Kafka里的数据是持久化的,每个数据都存在服务器硬盘里。
Kafka里的消费者支持fault tolerant。如果一个消费者挂掉,kafka会把任务放到其他消费者上。
(3)在消息流发生时处理他们;
也就是我们所说的流处理 kafka从0.10版本之后增加了kafka streams流处理功能。当直接使用Kafka consumer和producer API时,你如果想要实现比较复杂的逻辑,像聚合和join,就得在这些API的基础上自己实现如果用流处理框架,那么就添加了很多很多复杂性,对于调试、性能优化、监控,都带来很多困难。
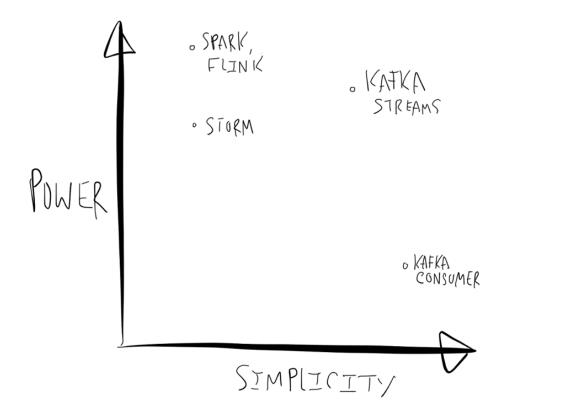
图4 流处理对比
kafka streams也不同于spark等流处理平台,kafka streams 主要是将数据进行处理后再次写入kafka中,而spark等平台则是写到数据库中。
02

Kafka架构
(1)kafka架构
Kafka的整体架构非常简单,是显式分布式架构,producer(前端应用)、broker(kafka)和consumer(数据库集群、消息推送服务)都可以有多个。数据从producer发送到broker,broker承担一个中间缓存和分发的作用。broker分发注册到系统中的consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。
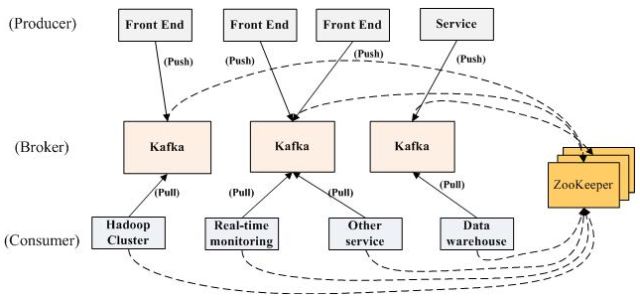
图5 kafka架构
(2)消息发送的流程
Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面。kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。Consumer从kafka集群pull数据,并控制获取消息的offset。
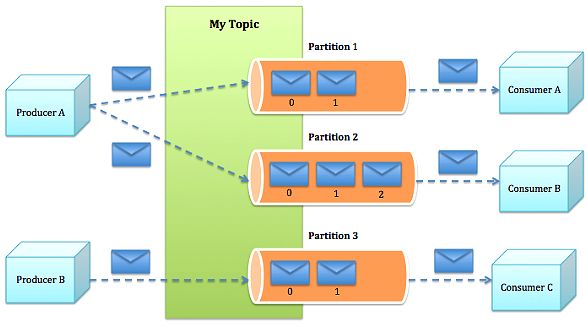
图6 消息发送的流程
03
Kafka高效设计
(1)消息顺序写入磁盘
我们知道现在的磁盘大多数都还是机械结构,如果将消息以随机写的方式存入磁盘,就会按柱面、磁头、扇区的方式进行(寻址过程),缓慢的机械运动(相对内存)会消耗大量时间,导致磁盘的写入速度只能达到内存写入速度的几百万分之一,为了规避随机写带来的时间消耗,KAFKA采取顺序写的方式存储数据。每个分区日志只能在尾部追加写入(append),而不允许随机“跳到”某个位置开始写入,故此实现了顺序写入。
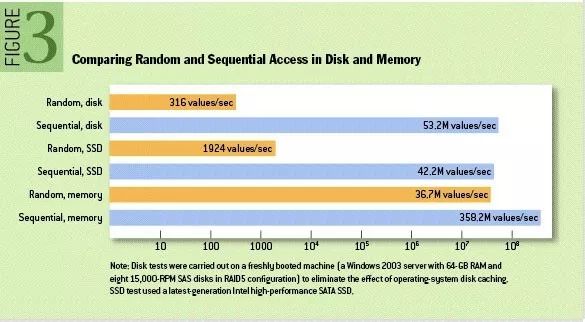
图7 顺序访问与随机访问的区别
在一个6*7200rmp RAID-5中,线性写速度可以达到300MB/S,而随机读写只能达到50KB/S。

图8 磁盘阵列上的写入速度
(2)零拷贝
如图9所示,这里有四次拷贝,两次系统调用,这是非常低效的做法。
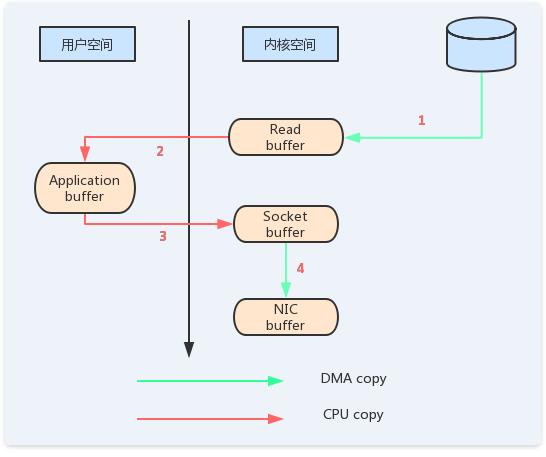
图9 四次拷贝流程
如果使用sendfile,只需要一次拷贝就行:允许操作系统将数据直接从页缓存发送到网络上。所以在这个优化的路径中,只有最后一步将数据拷贝到网卡缓存中是需要的。
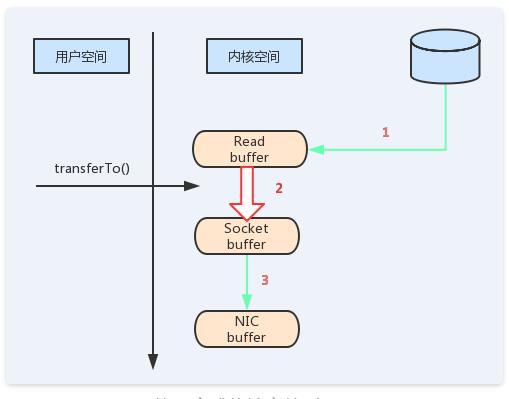
图10 零拷贝流程
04
Kafka解决的问题
第一阶段
首次搭建应用网络如下:
(1)Web应用部署在云服务器上,为个人电脑或移动用户提供访问服务。
(2)SQL数据库为Web应用提供数据持久化和数据查询。
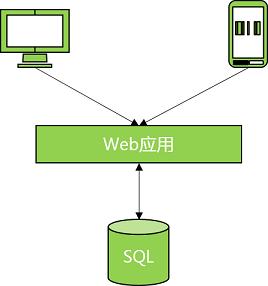
图11 简单应用网络架构
第二阶段
基于业务的迅速发展,网络扩容如下:
(1)增加缓存服务,从而降低SQL数据库的荷载。
(2)搜集日志保存至Hadoop做离线处理,从而更加理解用户行为。
(3)数据汇总至数据仓库,从而获取交互式报表。
(4)加入实时模块和外部数据交互等等。
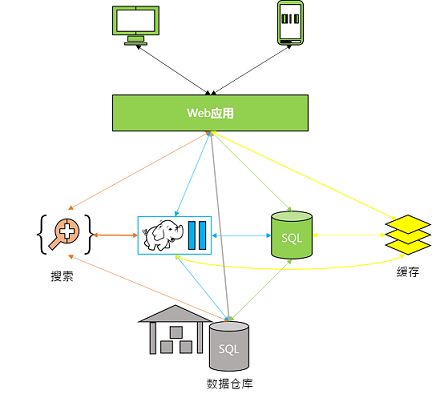
图12 网络扩容后的架构
产生的问题:
(1)不同系统之间的数据同步
(2)系统扩展问题
第三阶段
新增Kafka模块提供消息队列,Web应用数据只需向队列中添加数据,网络中的各组件从队列中依次读取数据并自行处理,网络扩容带来的问题迎刃而解,而且降低了系统组网复杂度;降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka承担高速数据总线的作用。
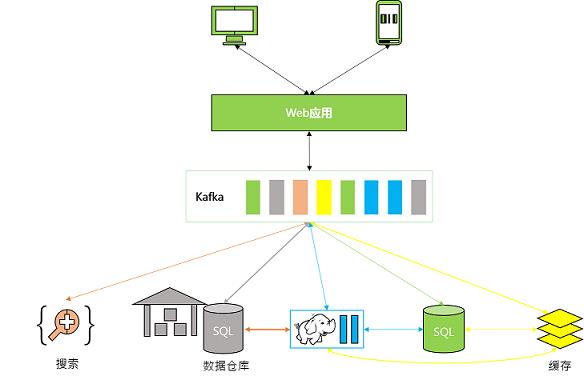
图13 使用kafka后的网络架构
05
总结
总的来说,kafka作为一个消息队列的优质实现,提供了一个高吞吐量、高可靠性、持久性高、分布式的提交日志,解决了两个方向的关键需求:一是大系统下各个部分的解耦,二是请求与响应不对称情况下的削峰。
审稿:XX
编辑:熙茵
以上是关于务本kafka的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之KafkaKafka APIKafka监控Flume对接KafkaKafka面试题
大数据技术之KafkaKafka APIKafka监控Flume对接KafkaKafka面试题