Storm+Kafka实现流式大数据实时日志分析
Posted 日志帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm+Kafka实现流式大数据实时日志分析相关的知识,希望对你有一定的参考价值。
【写前面】
关于日志帮
日志管理工具爱好者交流平台,分享日志管理相关知识,普及日志管理理念。发布日志管理领域的技术趋势,评测分享日志管理领域的开源及商业化产品。
作为一名安全从业人员,挖掘威胁情报可以有效拦截黑客的攻击。日志是记录黑客攻击流程的重要依据,从日志中及时发现攻击态势可以解决很多安全问题。此内容为两个月熟悉了简单的实时日志分析系统的搭建。
分享这篇文章的原因:
第一是与大家分享大数据日志实时分析,从中挖掘威胁情报;
第二是自己对近期的研究课题进行总结、温习。
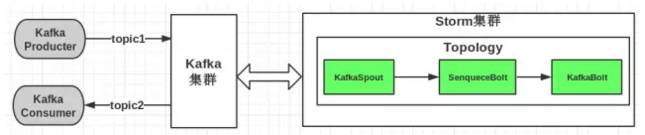
对于大数据分析我所了解的有Hadoop、ELK、Spark,但是本篇文章我要介绍的不是前三者,而是Storm流式处理框架和Kafka分布式消息系统的集成应用。流程图如下:
上述图片描述了Storm和Kafka集成应用系统的工作流程,Hadoop等大数据处理都是对本地存储或者云端存储的大数据进行批量分析,流式实时效果非常不佳,对服务器资源的消耗巨大,但是Storm有效的解决了这个问题。
举几个小例子:
阿里巴巴---Storm来做一些实时的日志统计,从日志中抽取有用的信息;每天的日志量在200w到15亿之间,最大达到2T。
爱奇艺---使用Storm对用户视频点击实时统计,为广告视频推送等提供数据基础
Twitter---实时分析各个页面点击量,根据计算结果为用户行为画像,实时推送准确的消息
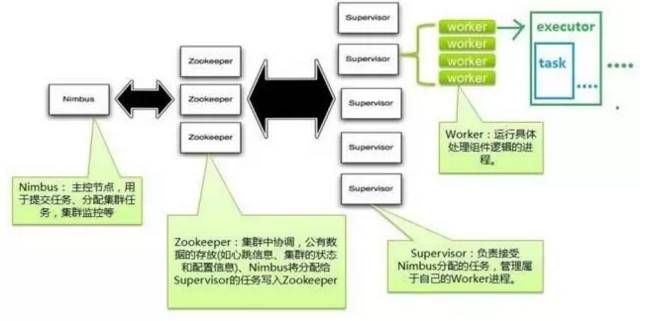
Storm的工作机制
上图中我们可以看到Storm组件主要由四部分组成:
Nimbus作为中央管控(资源分配以及任务调度)
Supervisor负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程
Worker运行具体处理组件逻辑的进程Zookeeper组件负责集群协调。
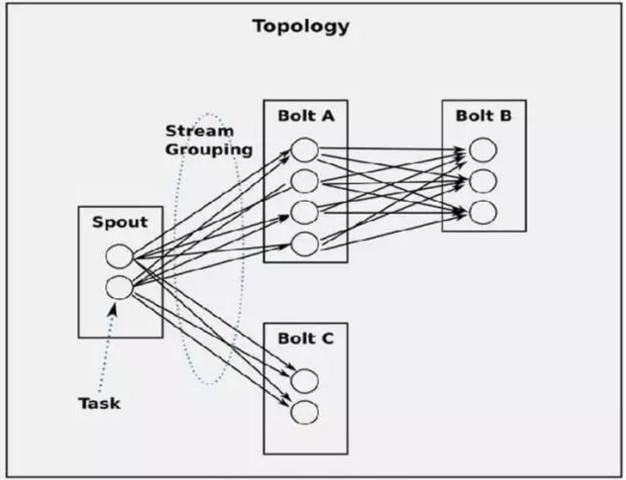
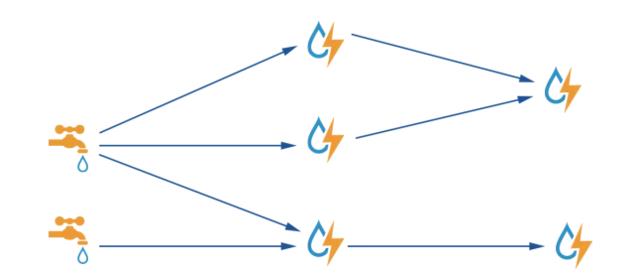
在这个框架中需要我们自己编程实现的就是给Storm提交拓扑,这个拓扑的作用如下图:
对于上述拓扑的提交代码请看第四部分的详细介绍。
下面我来阐述Storm拓扑+Kafka分布消息队列的实现,开源框架Pyleus,能够让Python处理大量数据。
简单引入Storm基本概念:
Tuple是Storm拓扑中的数据单元,流入和流出Storm组件
Spouts是将tuple导入拓扑的组件. 通常,spout消耗来自外部源的数据,如Kafka或Kinesis,然后将记录标记元组
Bolts订阅一个或多个其他spouts和bolts的输出流,做一些处理,然后标记为自己的元组。
Stream Grouping定义了元组的传送方式。
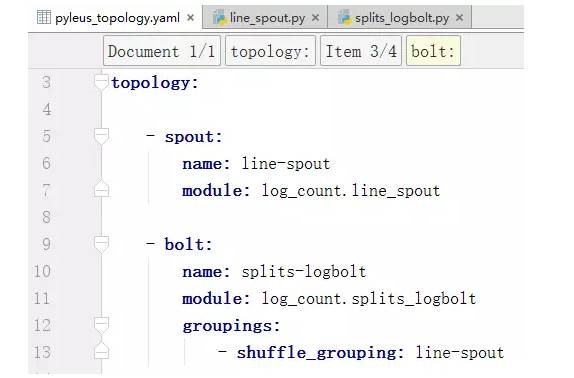
Pyleus定义拓扑的文件书写格式如下:
拓扑告诉了Strom框架的工作流程首先是Spout.py文件,其次是进入第一个Bolt.py文件,在进入第二个、第三个以此类推。
对于Storm可以处理的数据量很大,归功于它实时流动式的数据处理模式,而且对于大数据的处理效率非常高,例如,一个小时内需要实时处理1T的日志量,我们可以首先用10个Bolt来处理,接下来这10个Bolt中的每一个都会继续传递给另外两个Bolt来处理,这样最后分配给每个服务器的数据处理量就只剩下512MB。当然,还可以交给更多的Bolt来解决,那么每个服务器的处理数据量几乎接近1KB,所以对于实时大数据的处理交给Storm是非常迅速的。
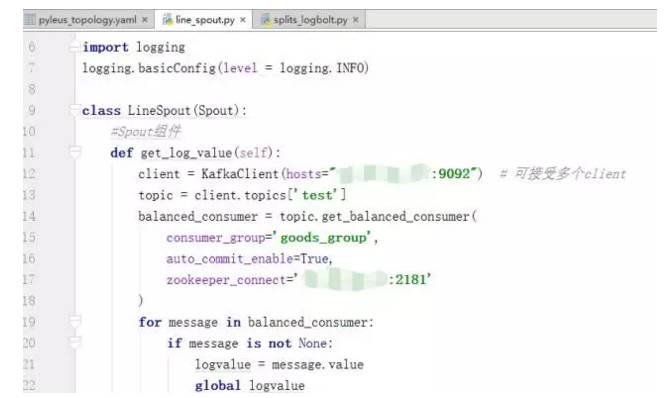
下面的代码描述了从Kafka中读取消息,定义为Spout的详细过程:
Spout连接Kafka消息队列, 我们知道storm的作用主要是进行流式计算,对于源源不断的均匀数据流流入处理是非常有效的,而现实生活中大部分场景并不是均匀的数据流,而是时而多时而少的数据流入,这种情况下显然用批量处理是不合适的,如果使用storm做实时计算的话可能因为数据拥堵而导致服务器挂掉,应对这种情况,使用kafka作为消息队列是非常合适的选择,kafka可以将不均匀的数据转换成均匀的消息流,从而和storm比较完善的结合,这样才可以实现稳定的流式计算。
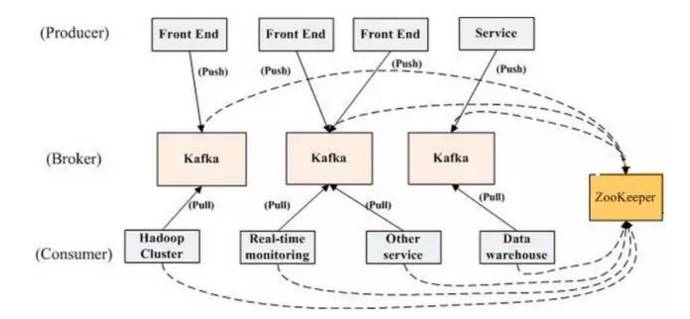
Kafka原理图
Producer向Kafka队列中推送消息,而消费者Consumer从队列中取出。
最后,我为大家分享一个Hadoop和Storm对比图,加深理解
日志帮
日志管理工具爱好者交流平台
更多日志分析文章
长按二维码,让你时刻掌握行业动态
↓↓↓ 点击"阅读原文" 【查看往期内容】
以上是关于Storm+Kafka实现流式大数据实时日志分析的主要内容,如果未能解决你的问题,请参考以下文章