kafka 内部是怎么存储消息的
Posted spark技术分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka 内部是怎么存储消息的相关的知识,希望对你有一定的参考价值。
首发个人公众号 spark技术分享 , 同步个人网站 coolplayer.net ,未经本人同意,禁止一切转载
kafka 的基本存储单位是分区
一个分区是一个不可变有序消息存储序列,一个分区只能在一个 broker 上, 甚至只能存储在一个磁盘上。
kafka 使用日志保留策略来调整消息保存时间
你可以指定消息保留时间,无论消息是否被消费,一旦超过保留时间,消息就会被自动清理掉
kafka 分区又被分为多个段
kafka 根据保留策略,来检测需要被清理的日志,如果只有一个非常大的日志文件,是很消耗性能和容易出错的。
所以kafka 把一个分区的日志分为多个段,写消息的时候写入一个活跃的段,一旦这个段超过一定大小,就会新建一个新的段来写入。
一个段的文件名是这个段第一条消息的offset, 看下图,3个段的文件名为 segment 0, segment 1, segment 2。
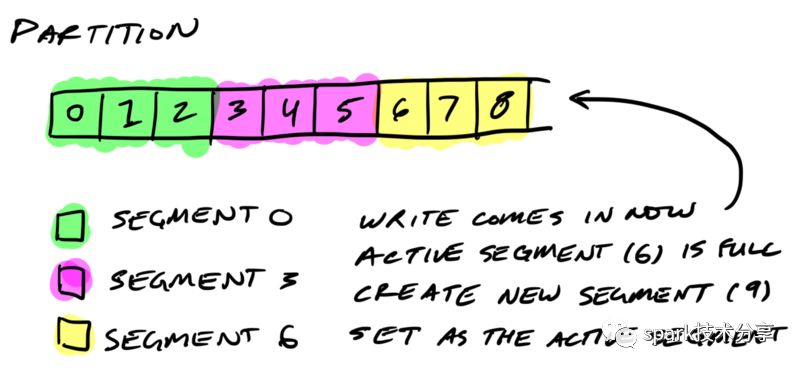
在无论磁盘上,一个分区对应一个目录,一个段对应一个index 文件和一个 log 文件。
$ tree kafka | head -n 6
kafka
├── events-1
│ ├── 00000000003064504069.index
│ ├── 00000000003064504069.log
│ ├── 00000000003065011416.index
│ ├── 00000000003065011416.log
实际消息是存储在一个段的 log 文件中,一条消息的物理结构如下

参数说明
8 byte offset : 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message
4 byte message size: message大小
4 byte CRC32: 用crc32校验message
1 byte “magic": 表示本次发布Kafka服务程序协议版本号
1 byte “attributes": 表示为独立版本、或标识压缩类型、或编码类型。
4 byte key length: 表示key的长度,当key为-1时,K byte key字段不填
K byte key: 可选
value bytes payload: 实际的消息数据
数据存储的格式,和 producer 发送日志的格式,以及 consumer 拉取日志的格式都是一致的,这一点保证了kafka 可以使用 zero copy, 因为从磁盘存储读取的数据可以直接走网络发送出去,中间不需要任何转换。
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /data/kafka/events-1/00000000003065011416.log | head -n 4
Dumping /data/kafka/appusers-1/00000000003065011416.log
Starting offset: 3065011416
offset: 3065011416 position: 0 isvalid: true payloadsize: 2820 magic: 1 compresscodec: NoCompressionCodec crc: 811055132 payload: {"name": "Travis", msg: "Hey, what's up?"}
offset: 3065011417 position: 1779 isvalid: true payloadsize: 2244 magic: 1 compresscodec: NoCompressionCodec crc: 151590202 payload: {"name": "Wale", msg: "Starving."}
一个段的索引文件,用来定位消息在 log 文件中的物理位置
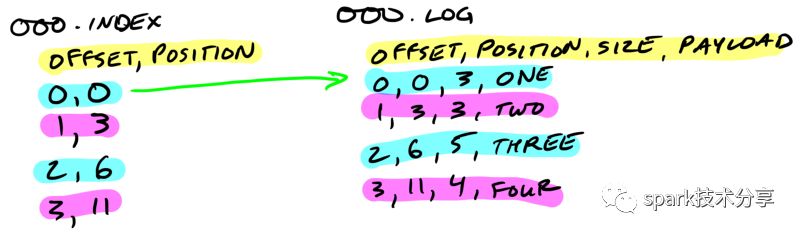
index 文件的索引都是 8 个字节, 4个字节用来存储 offset 的相对值, 4 个字节用来存储消息在log 文件中的物理位置,注意 4 个字节中存储的是 offset 的相对值,比如你的 index 文件启始 offset 是 10000000000000000000, 那么这 4 个字节中就用 1 和 2 来代表 10000000000000000001 和 10000000000000000002。
在partition中如何通过offset查找message
例如读取offset=368776的message,需要通过下面2个步骤查找。
第一步查找segment file

其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1.同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset **二分查找**文件列表,就可以快速定位到具体文件。
当offset=368776时定位到00000000000000368769.index|log

从上图可知这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
kafka 把多条消息压缩在一起
producer 把需要发送给broker 的消息作为一个 batch ,整体进行压缩,我们都知道 kafka 直接把这个压缩后的 文件存储起来,consumer 来消费的时候直接把这个压缩文件发送出去,性能极高。
分区是日志存储的基本单位
分区分为多个段
每个段包含一个index 文件和一个log 文件
index 文件用来索引定位log 文件中的消息
index 中的 offset 是相对值
kafka 磁盘存储的数据 和 producer 发送的数据,以及 consumer 拉取到的数据是一样的,中间过程不经过任务转换和处理
欢迎关注 spark技术分享
以上是关于kafka 内部是怎么存储消息的的主要内容,如果未能解决你的问题,请参考以下文章