正经文章Kafka与Spark Streaming的联姻
Posted 朱小厮的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正经文章Kafka与Spark Streaming的联姻相关的知识,希望对你有一定的参考价值。
技术干货文章第一时间送达!
Kafka与Spark虽然没有很直接的必然关系,但是实际应用中却经常以couple的形式存在。如果你的Kafka的爱好者,流式计算框架Spark、Flink等也不得不去了解;如果你是Spark的爱好者,Kafka又或许是必不可少的一部分。在之前的《》和《》两篇文章中,我们了解了Spark的基本面貌,这里主要来讲述一下Kafka与Spark Streaming的结合,如果大家有兴趣,后面会放出一个系列的文章,包括Spark编程模型、Spark Streaming、Spark SQL、Structured Streaming以及Kafka与Structured Streaming的联姻。如果没有兴趣。。。嗯。。。请下方留言告知。。。
采用Spark Streaming流式处理Kafka中的数据,首先需要的是把数据从Kafka中接收过来,然后转换为Spark Streaming中的DStream。接收数据的方式一共有两种:利用接收器Receiver的方式接收数据、直接从Kafka中读取数据。
Receiver方式是通过KafkaUtils.createStream()方法来创建一个DStream对象,它不关注消费位移的处理,Receiver方式的结构如下图所示。但这种方式在Spark任务执行异常时会导致数据丢失的情况,如果要保证数据的可靠性,需要开启预写式日志,简称WAL(Write Ahead Logs),只有接收到的数据被持久化到WAL之后才会去更新Kafka中的消费位移。接收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,这些信息被用来从错误中恢复,并继续处理数据。
WAL的方式可以保证从Kafka中接收的数据不被丢失。但是在某些异常情况下,一些数据被可靠地保存到了WAL中,但是还没有来得及更新消费位移,这样会造成Kafka中的数据被Spark拉取了不止一次。同时在Receiver方式中,Spark中的RDD分区和Kafka的分区并不是相关的,因此增加Kafka中主题的分区数并不能增加Spark处理的并行度,而仅是增加接收器接收数据的并行度。
Direct方式是从Spark1.3开始引入的,它通过KafkaUtils.createDirectStream()方法创建一个DStream对象,Direct方式的结构如下图所示。该方式中Kafka的一个分区与Spark RDD对应,通过定期扫描所订阅Kafka每个主题的每个分区的最新偏移量以确定当前批处理数据偏移范围。与Receiver方式相比,Direct方式不需要维护一份WAL数据,由Spark Streaming程序自己控制位移的处理,通常通过检查点机制处理消费位移,这样可以保证Kafka中的数据只会被Spark拉取一次。
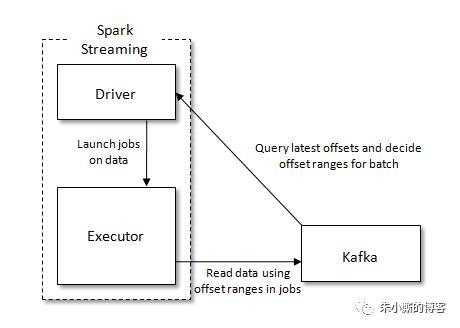
注意使用了Direct的方式并不就意味着就实现了精确一次的语义(Exactly Once Semantics),如果要达到精确一次的语义标准,还需要配合幂等性操作或者事务性操作。
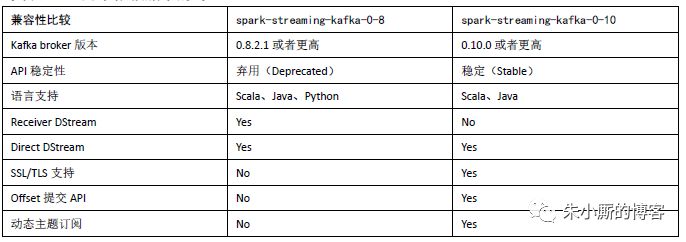
在Spark官网中关于Spark Streaming与Kafka集成给出了两个依赖版本,一个是基于Kafka 0.8之后的版本(spark-streaming-kafka-0-8),一个是基于Kafka 0.10及其之后的版本(spark-streaming-kafka-0-10)。spark-streaming-kafka-0-8版本Kafka与Spark Streaming集成有Receiver方式和Direct方式这两种接收数据的方式,不过spark-streaming-kafka-0-8从Spark 2.3.0开始被标注为“弃用”。而spark-streaming-kafka-0-10版本只提供Direct方式,同时底层使用的是新消费者客户端KafkaConsumer而不是之前的旧消费者客户端,因此通过KafkaUtils.createDirectStream()方法构建的DStream数据集是ConsumerRecord类型。下表中给出了两个版本的更多细节对比。
前面提及过本章节的内容是基于Spark 2.3.1的版本,因此下面的介绍中也只基于spark-streaming-kafka-0-10版本做相应的陈述,更何况spark-streaming-kafka-0-8版本已经被弃用。spark-streaming-kafka-0-10版本所需要的Maven依赖如下:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
下面我们使用一个简单的例子来演示一下Spark Streaming和Kafka的集成。在该示例中,每秒钟往Kafka写入一个0~9之间的随机数,通过Spark Streaming从Kafka中获取数据并对批次间隔内的数据实时计算它们的数值之和。 往Kafka中写入随机数的主要代码如下:
Random random = new Random();
while (true) {
int value = random.nextInt(10);
ProducerRecord<String, String> message =
new ProducerRecord<>(topic, value+"");
producer.send(message).get();
TimeUnit.SECONDS.sleep(1);
}
Spark Streaming程序的相关内容如下所示,代码中的批次间隔设置为2s。示例中的主题topic-spark中包含有4个分区。

第①和第②行代码在实例化SparkConf之后创建了StreamingContext。StreamingContext创建后需要实例化一个DStream,所以在第④行中通过KafkaUtils.createDirectStream()方法创建了一个。第⑤行只是简单的消费所读取到的ConsumerRecord,并执行简单的求和计算。
从Kafka中消费数据,其本质是一个消费者,因此KafkaUtils.createDirectStream()方法也需要指定KafkaConsumer的相关配置。KafkaUtils.createDirectStream()方法的第一个参数我们好理解,方法中的第二个参数是LocationStrategies类型的,用来指定Spark执行器节点上KafkaConsumer的分区分配策略。LocationStrategies类型提供了3种策略:PerferBrokers策略,必须保证执行器节点和Kafka Broker拥有相同的host,即两者在相同的机器上,这样可以根据分区副本的leader节点来进行分区分配;PerferConsistent策略,该策略将所订阅主题的分区均匀地分配给所有可用的执行器,在绝大多数情况下,都使用这种策略,包括在本示例中也是使用的这种策略;PerferFixed策略,允许开发人员指定分区与host之间的映射关系。KafkaUtils. createDirectStream()方法中第三个参数是ConsumerStrategies类型的,用来指定Spark执行器节点的消费策略。与KafkaConsumer订阅主题的方式对应,这里也有3种策略:Subscribe、SubscribePattern和Assign,分别代表通过指定集合、通过正则表达式以及通过指定分区的方式来进行订阅。
示例程序最直观的功能就是在每个批次间隔内(2s)读出数据(每秒1个)来进行求和,程序输出的部分结果如下所示:
3
4
-------------------------------------------
Time: 1533613594000 ms
-------------------------------------------
7
前面提到了执行器有3种消费策略,但是在示例代码中只用到了Subscribe的策略。如果要使用SubscribePattern策略的话,可以将代码中的第④行代码修改为如下内容:
val stream = KafkaUtils.createDirectStream[String,String](
ssc, PreferConsistent,
SubscribePattern[String,String](Pattern.compile("topic-.*"),kafkaParams)
)
而如果要使用Assign策略的话,可以将代码中的第④行代码修改为如下内容:
val partitions = List(new TopicPartition(topic,0),
new TopicPartition(topic,1),
new TopicPartition(topic,2),
new TopicPartition(topic,3))
val stream = KafkaUtils.createDirectStream[String,String](
ssc, PreferConsistent,
Assign[String, String](partitions, kafkaParams))
Spark Streaming同时也支持从指定的位置处开始处理数据,前面所演示的3种消费策略都可以支持,只需添加对应的参数即可。这里我们就以Subscribe策略为例来演示一下具体用法,可以将下面的代码替换掉示例代码中的第④行代码,示例中的fromOffsets参数指定了每个分区的起始处理位置为5000:
val partitions = List(new TopicPartition(topic,0),
new TopicPartition(topic,1),
new TopicPartition(topic,2),
new TopicPartition(topic,3))
val fromOffsets = partitions.map(partition => {
partition -> 5000L
}).toMap
val stream = KafkaUtils.createDirectStream[String, String](
ssc, PreferConsistent,
Subscribe[String, String](List(topic), kafkaParams, fromOffsets))
示例代码中只是计算了批次间隔内的数据,这样只是简单的转换操作,如果需要使用滑动窗口操作,比如计算窗口间隔为20s,滑动间隔为2s的窗口内的数值之和,就可以将第⑤行代码修改为如下内容:
val value = stream.map(record=>{
Integer.valueOf(record.value())
}).reduceByWindow(_+_, _-_,Seconds(20),Seconds(2))
前面说过在Direct方式下,Spark Streaming会自己控制消费位移的处理,那么原本应该保存到Kafka中的消费位移就无法提供准确的信息了。但是在某些情况下,比如监控需求,我们又需要获取当前Spark Streaming正在处理的消费位移。Spark Streaming也考虑到了这种情况,我们可以通过下面的程序来获取消费位移:
stream.foreachRDD(rdd=>{
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreachPartition{iter=>
val o: OffsetRange = offsetRanges(TaskContext.get.partitionId)
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
}
})
注意需要将这段代码放在第④行之后,也就是需要在使用KafkaUtils.createDirectStream()方法创建完DStream之后第一个调用,虽然Kafka的分区与Spark RDD一一对应,但是在混洗类型的方法(比如reduceByKey())执行之后这种对应关系就会丢失。
如果你的应用更加适合于批处理作业,那么在Spark中你也可以使用KafkaUtils.createRDD()方法来创建一个指定处理范围的RDD。示例参考如下:
val offsetRanges = Array(
OffsetRange(topic,0,0,100),
OffsetRange(topic,1,0,100),
OffsetRange(topic,2,0,100),
OffsetRange(topic,3,0,100)
)
val rdd = KafkaUtils.createRDD(ssc,
JavaConversions.mapAsJavaMap(kafkaParams),
offsetRanges, PreferConsistent)
rdd.foreachPartition(records=>{
records.foreach(record=>{
println(record.topic()+":"+record.partition()+":"+ record.value())
})
})
示例中的OffsetRange类型表示给定主题和分区中特定消息序列的下限和上限。OffsetRange(topic,0,0,100) 这行代码中标识从topic主题的第0个分区中的偏移量0到偏移量100(不包括)的100条消息。
《》
《》
>>><<<
转载声明:本文转载自「朱小厮的博客」,搜索「hiddenzzh」关注。
以上是关于正经文章Kafka与Spark Streaming的联姻的主要内容,如果未能解决你的问题,请参考以下文章
013- Kafka应用之Kafka与Spark Streaming整合