Kafka 遇上 Spark Streaming
Posted 码省理工
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka 遇上 Spark Streaming相关的知识,希望对你有一定的参考价值。
站酷 | 插画
搭建流程略,主要讲一下如何更好的结合使用,看图说话。
Kafka 结合 Spark Streaming 实现在线的准实时流分析,除了保证数据源和数据接收的可靠性,还要保证元数据的 checkpoint 。
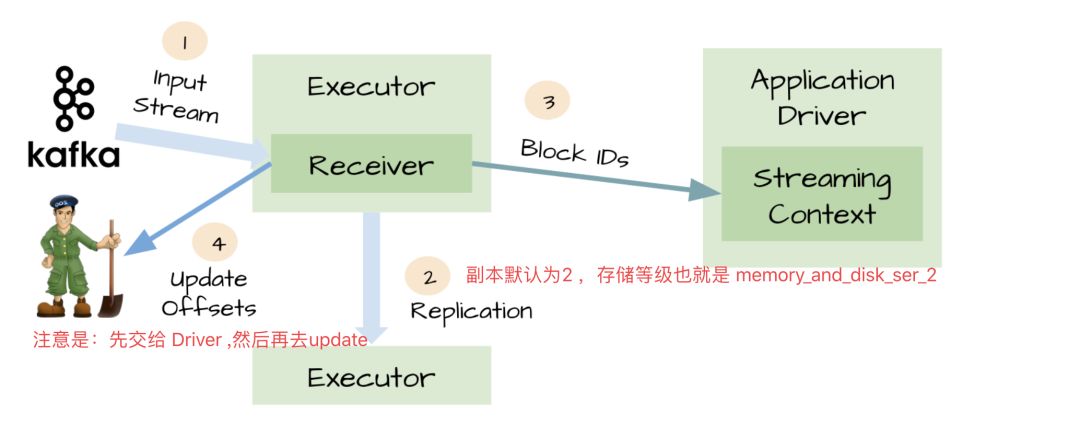
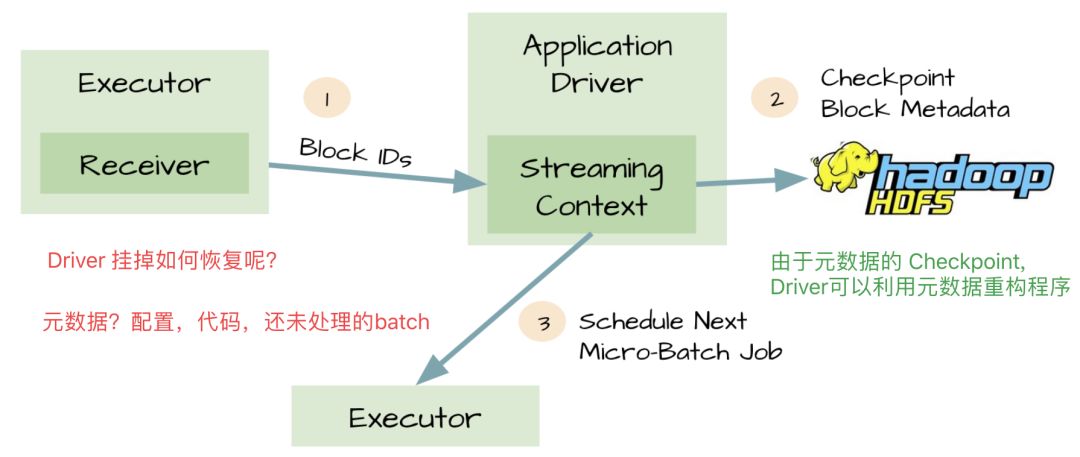
以上的方案,不能防止数据的丢失。
Executor 收到数据后开始执行任务了。但是这时候 Driver 挂掉了,相应的 Executor 进程也会被 kill 掉,数据就会丢失。
为了防止上面这种数据丢失,Spark Streaming 1.2开始引入了WAL机制。
启用了WAL机制,已经接收的数据被接收器写入到容错存储中,比如HDFS或者S3。由于采用了WAl机制,Driver可以从失败的点重新读取数据,即使Exectuor中内存的数据已经丢失了。在这个简单的方法下,Spark Streaming提供了一种即使是Driver挂掉也可以避免数据丢失的机制。
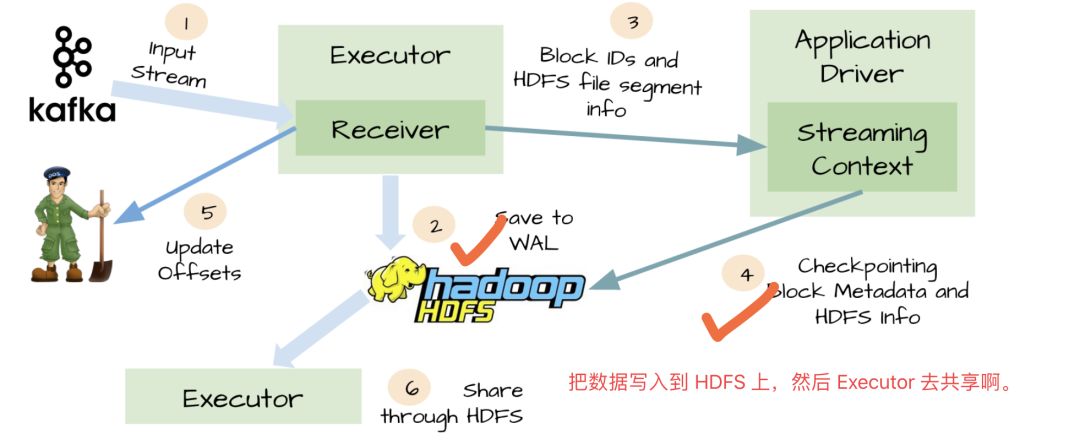
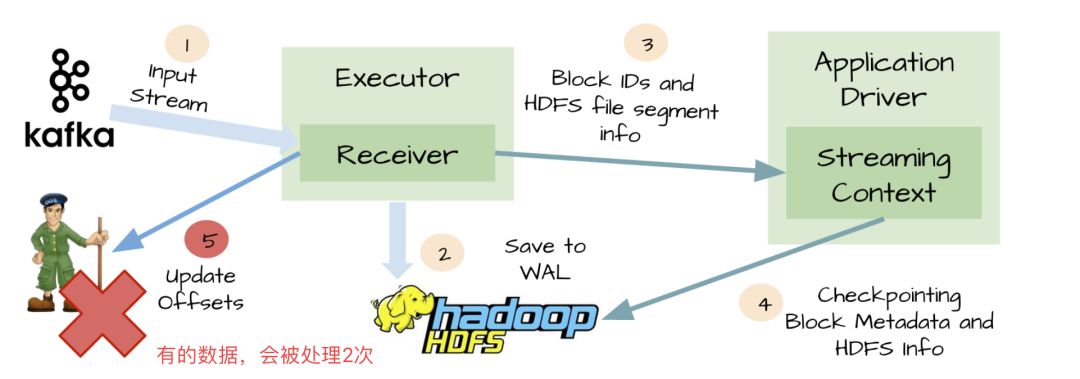
At-least-once语义
接收器接收到输入数据,并把它存储到WAL中;接收器在更新Zookeeper中Kafka的偏移量之前突然挂掉了;这是就会出现数据被处理 2 次的情况。
终极解决方案 Kafka Direct API
为了解决由WAL引入的性能损失,并且保证 exactly-once 语义,Spark Streaming 1.3中引入了名为Kafka direct API
好处:
不再需要接收器,Executor 直接从 Kafka 中采用 Sample Consumer API 消费数据。
不再需要WAL机制,我们仍然可以从失败恢复之后从Kafka中重新消费数据。
exactly-once语义得以保存,我们不再从WAL中读取重复的数据。
综合以上,direct 模式比receive模式的优点:
1、简化并行读取:如果要读取多个partition,不需要创建多个输入DStream,然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
2、高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
3、一次且仅一次的事务机制:基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。由于数据消费偏移量是保存在checkpoint中,因此,如果后续想使用kafka高级API消费数据,需要手动的更新zookeeper中的偏移量。
推荐阅读
如果对您有帮助,欢迎点赞、关注、转发。
以上是关于Kafka 遇上 Spark Streaming的主要内容,如果未能解决你的问题,请参考以下文章