说说 Kafka 中的时间轮算法
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了说说 Kafka 中的时间轮算法相关的知识,希望对你有一定的参考价值。
链接:
https://my.oschina.net/anur/blog/2252539#h3_1
零、时间轮定义
简单说说时间轮吧,它是一个高效的延时队列,或者说定时器。实际上现在网上对于时间轮算法的解释很多,定义也很全,这里引用一下朱小厮博客里出现的定义:
参考下图,Kafka中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务TimerTask。

如果你理解了上面的定义,那么就不必往下看了。但如果你第一次看到和我一样懵比,并且有不少疑问,那么这篇博文将带你进一步了解时间轮,甚至理解时间轮算法。
如果有兴趣,可以去看看其他的定时器 你真的了解延时队列吗。博主认为,时间轮定时器最大的优点:
是任务的添加与移除,都是O(1)级的复杂度;
不会占用大量的资源;
只需要有一个线程去推进时间轮就可以工作了。
我们将对时间轮做层层推进的解析:
一、为什么使用环形队列
假设我们现在有一个很大的数组,专门用于存放延时任务。它的精度达到了毫秒级!那么我们的延迟任务实际上需要将定时的那个时间简单转换为毫秒即可,然后将定时任务存入其中:
比如说当前的时间是2018/10/24 19:43:45,那么就将任务存入Task[1540381425000],value则是定时任务的内容。
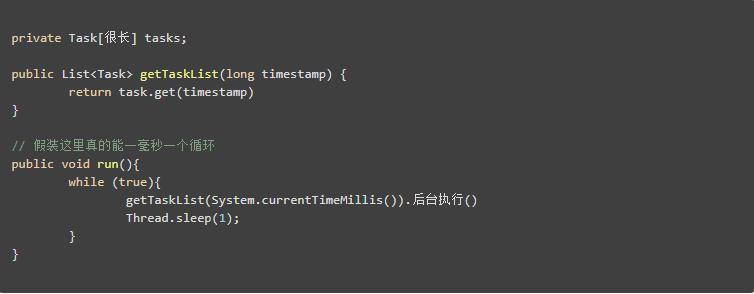
假如这个数组长度达到了亿亿级,我们确实可以这么干。 那如果将精度缩减到秒级呢?我们也需要一个百亿级长度的数组。
先不说内存够不够,显然你的定时器要这么大的内存显然很浪费。
当然如果我们自己写一个map,并保证它不存在hash冲突问题,那也是完全可行的。(我不确定我的想法是否正确,如果错误,请指出)
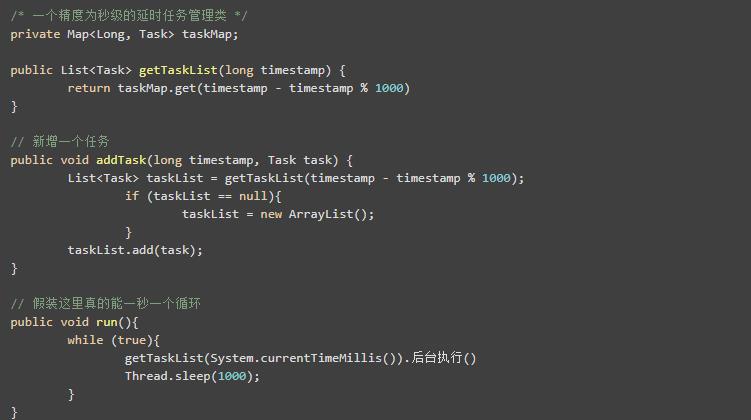
其实时间轮就是一个不存在hash冲突的数据结构
抛开其他疑问,我们看看手腕上的手表(如果没有去找个钟表,或者想象一个),是不是无论当前是什么时间,总能用我们的表盘去表示它(忽略精度)

就拿秒表来说,它总是落在 0 - 59 秒,每走一圈,又会重新开始。
用伪代码模拟一下我们这个秒表:
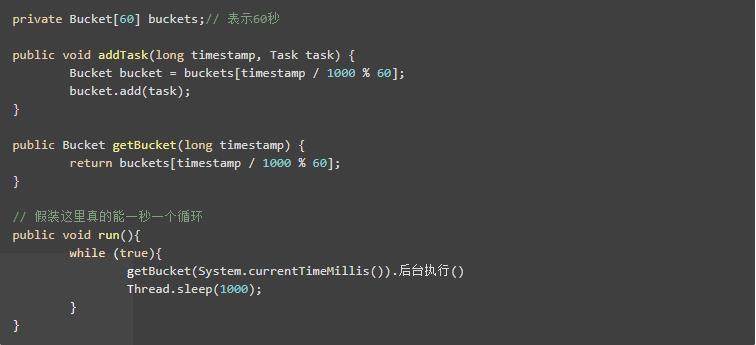
这样,我们的时间总能落在0 - 59任意一个bucket上,就如同我们的秒钟总是落在0 - 59刻度上一样,这便是时间轮的环形队列。
二、表示的时间有限
但是细心的小伙伴也会发现这么一个问题:如果只能表示60秒内的定时任务应该怎么存储与取出,那是不是太有局限性了?如果想要加入一小时后的延迟任务,该怎么办?
其实还是可以看一看钟表,对于只有三个指针的表(一般的表)来说,最大能表示12个小时,超过了12小时这个范围,时间就会产生歧义。如果我们加多几个指针呢?比如说我们有秒针,分针,时针,上下午针,天针,月针,年针...... 那不就能表示很长很长的一段时间了?而且,它并不需要占用很大的内存。
比如说秒针我们可以用一个长度为60的数组来表示,分针也同样可以用一个长度为60的数组来表示,时针可以用一个长度为24的数组来表示。那么表示一天内的所有时间,只需要三个数组即可。
动手来做吧,我们将这个数据结构称作时间轮,tickMs表示一个刻度,比如说上面说的一秒。wheelSize表示一圈有多少个刻度,即上面说的60。interval表示一圈能表示多少时间,即 tickMs * wheelSize = 60秒。
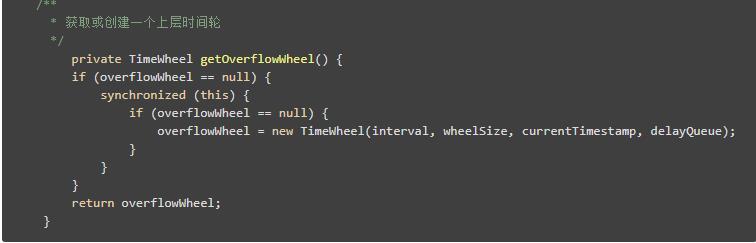
overflowWheel表示上一层的时间轮,比如说,对于秒钟来说,overflowWheel就表示分钟,以此类推。
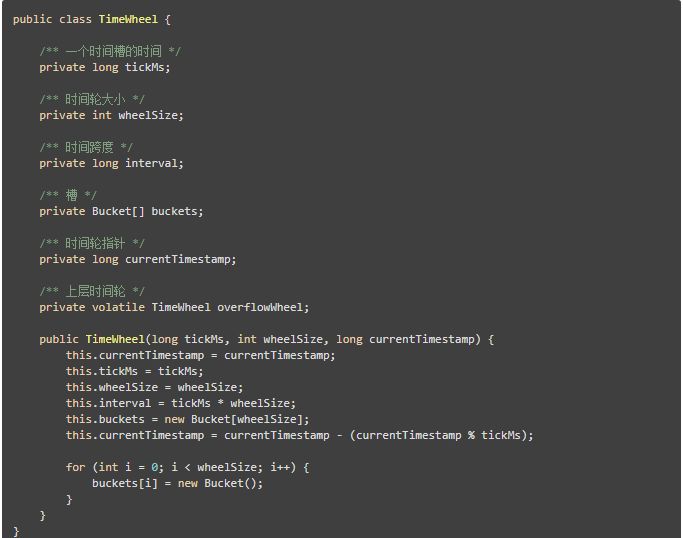
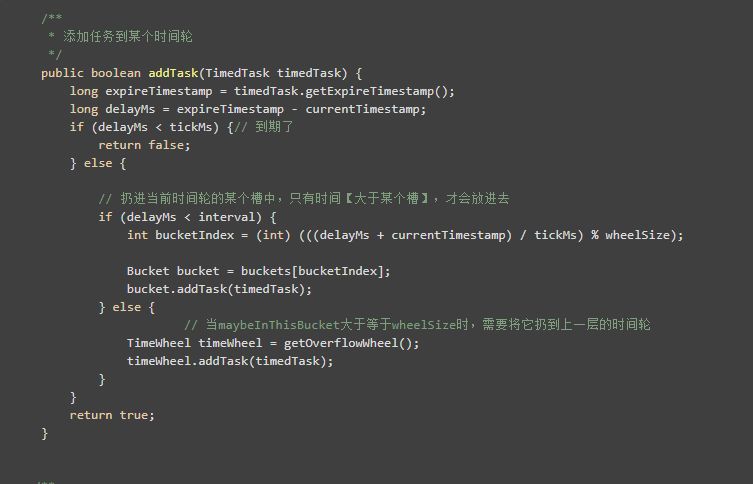
将任务添加到时间轮中十分简单,对于每个时间轮来说,比如说秒级时间轮,和分级时间轮,都有它自己的过期槽。也就是delayMs < tickMs的时候。
添加延时任务的时候一共就这几种情况:
1、时间到期
比如说有一个任务要在 16:29:07 执行,从秒级时间轮中来看,当我们的当前时间走到16:29:06的时候,则表示这个任务已经过期了。因为它的delayMs = 1000ms,小于了我们的秒级时间轮的tickMs(1000ms)。
比如说有一个任务要在 16:41:25 执行,从分级时间轮中来看,当我们的当前时间走到 16:41的时候(分级时间轮没有秒针!它的最小精度是分钟(一定要理解这一点)),则表示这个任务已经到期,因为它的delayMs = 25000ms,小于了我们的分级时间轮的tickMs(60000ms)。
2、时间未到期,且delayMs小于interval
对于秒级时间轮来说,就是延迟时间小于60s,那么肯定能找到一个秒钟槽扔进去。
3、时间未到期,且delayMs大于interval
对于妙级时间轮来说,就是延迟时间大于等于60s,这时候就需要借助上层时间轮的力量了,很简单的代码实现,就是拿到上层时间轮,然后类似递归一样,把它扔进去。
比如说一个有一个延时为一年后的定时任务,就会在这个递归中不断创建更上层的时间轮,直到找到满足delayMs小于interval的那个时间轮。
这里为了不把代码写的那么复杂,我们每一层时间轮的刻度都一样,也就是秒级时间轮表示60秒,上面则表示60分钟,再上面则表示60小时,再上层则表示60个60小时,再上层则表示60个60个60小时 = 216000小时。
也就是如果将最底层时间轮的tickMs(精度)设置为1000ms。wheelSize设置为60。那么只需要5层时间轮,可表示的时间跨度已经长达24年(216000小时)。
当然我们的时间轮还需要一个指针的推进机制,总不能让时间永远停留在当前吧?推进的时候,同时类似递归,去推进一下上一层的时间轮。
注意:要强调一点的是,我们这个时间轮更像是电子表,它不存在时间的中间状态,也就是精度这个概念一定要理解好。比如说,对于秒级时间轮来说,它的精度只能保证到1秒,小于1秒的,都会当成是已到期
对于分级时间轮来说,它的精度只能保证到1分,小于1分的,都会当成是已到期

三、对于高层时间轮来说,精度越来越不准,会不会有影响?
上面说到,分级时间轮,精度只有分钟级,总不能延迟1秒的定时任务和延迟59秒的定时任务同时执行吧?
有这个疑问的同学很好!实际上很好解决,只需再入时间轮即可。比如说,对于分钟级时间轮来说,delayMs为1秒和delayMs为59秒的都已经过期,我们将其取出,再扔进底层的时间轮不就可以了?
1秒的会被扔到秒级时间轮的下一个执行槽中,而59秒的会被扔到秒级时间轮的后59个时间槽中。
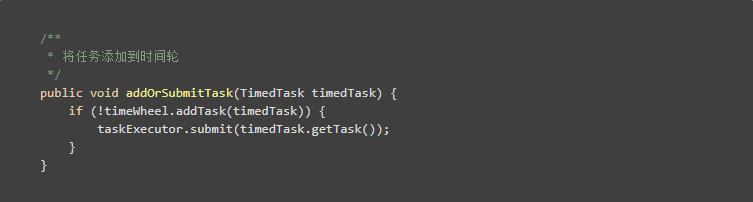
细心的同学会发现,我们的添加任务方法,返回的是一个bool

再倒回去好好看看,添加到最底层时间轮失败的(我们只能直接操作最底层的时间轮,不能直接操作上层的时间轮),是不是会直接返回flase?对于再入失败的任务,我们直接执行即可。
四、如何知道一个任务已经过期?
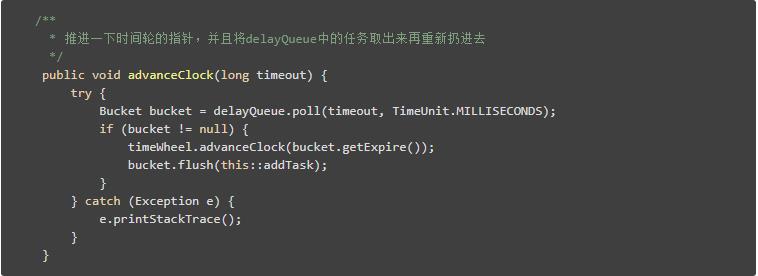
记得我们将任务存储在槽中嘛?比如说秒级时间轮中,有60个槽,那么一共有60个槽。如果时间轮共有两层,也仅仅只有120个槽。我们只需将槽扔进一个delayedQueue之中即可。
我们轮询地从delayedQueue取出已经过期的槽即可。(前面的所有代码,为了简单说明,并没有引入这个DelayQueue的概念,所以不用去上面翻了,并没有。博主觉得...已经看到这里了,应该很明白这个DelayQueue的意义了。)
其实简单来说,实际上定时任务单单使用DelayQueue来实现,也是可以的,但是一旦任务的数量多了起来,达到了百万级,千万级,针对这个delayQueue的增删,将非常的慢。
1、面向槽的delayQueue**
而对于时间轮来说,它只需要往delayQueue里面扔各种槽即可,比如我们的定时任务长短不一,最长的跨度到了24年,这个delayQueue也仅仅只有300个元素。
2、处理过期的槽**
而这个槽到期后,也就是被我们从delayQueue中poll出来后,我们只需要将槽中的所有任务循环一次,重新加到新的槽中(添加失败则直接执行)即可。
完整的时间轮GitHub,其实就是半抄半自己撸的Kafka时间轮简化版 Timer#main 中模拟了六百万个简单的延时任务,执行的效率很高 ~
开源中国征稿开始啦!
开源中国 www.oschina.net 是目前备受关注、具有强大影响力的开源技术社区,拥有超过 200 万的开源技术精英。我们传播开源的理念,推广开源项目,为 IT 开发者提供一个发现、使用、并交流开源技术的平台。
现在我们开始对外征稿啦!如果你有优秀的技术文章想要分享,热点的行业资讯需要报道等等,欢迎联系开源中国进行投稿。投稿详情及联系方式请参见:

以上是关于说说 Kafka 中的时间轮算法的主要内容,如果未能解决你的问题,请参考以下文章