Kafka基本知识整理
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka基本知识整理相关的知识,希望对你有一定的参考价值。
首先Kafka是一个分布式消息队列中间件,Apache顶级项目,https://kafka.apache.org/ 高性能、持久化、多副本备份、横向扩展。
生产者Producer往队列里发送消息,消费者Consumer从队列里消费消息,然后进行业务逻辑。应用场景主要有:解耦、削峰(缓冲)、异步处理、排队、分布式事务控制等等。
Kafka对外使用Topic(主题)的概念,生产者往Topic里写消息,消费者从Topic中消费读消息。
为了实现水平扩展,一个Topic实际是由多个Partition(分区)组成的,遇到瓶颈时,可以通过增加Partition的数量来进行横向扩容。
单个Parition内是保证消息有序。持久化时,每收到一条消息,Kafka就是在对应的日志文件Append写,所以性能非常高。
Kafka Data Flow 消息流转图
上图中,消息生产者Producers往Brokers里面的指定Topic中写消息,消息消费者Consumers从Brokers里面消费指定Topic的消息,然后进行业务处理。
在实际的部署架构中,Broker、Topic、Partition这些元数据保存在ZooKeeper中,Kafka的监控、消息路由(分区)由ZooKeeper控制。0.8版本的OffSet也由ZooKeeper控制。
一、消息生产/发送过程
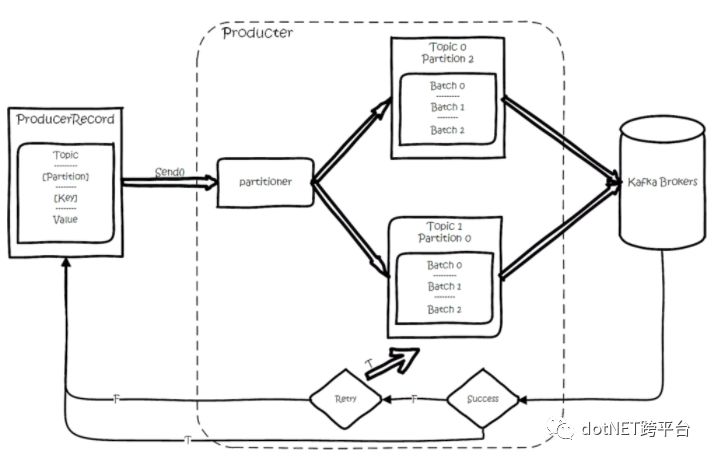
Kafka创建Message、发送时要指定对应的Topic和Value(消息体),Key(分区键)和Partition(分区)是可选参数。
调用Producer的Send()方法后,消息先进行序列化(消息序列化器可自定义实现:例如:Protobuf),然后按照Topic和Partition,临时放到内存中指定的发送队列中。达到阈值后,然后批量发送。
发送时,当Partition没设置时,如果设置了Key-分区键(例如:单据类型),按照Key进行Hash取模,保证相同的Key发送到指定的分区Partition。如果未设置分区键Key,使用Round-Robin轮询随机选分区Partition。
二、分区Partition的高可用和选举机制
分区有副本的概念,保证消息不丢失。当存在多副本的情况下,会尽量把多个副本,分配到不同的broker上。
Kafka会为Partition选出一个Leader Broker(通过ZooKeeper),之后所有该Partition的请求,实际操作的都是Leader,然后再同步到其他的Follower。
当一个Kafka Broker宕机后,所有Leader在该Broker上的Partition都会重新选举,在剩余的Follower中选出一个Leader,继续提供服务。
正如上面所讲:Kafka使用ZooKeeper在多个Broker中选出一个Controller,用于Partition分配和Leader选举。以下是Partition的分配机制:
将所有Broker(假设共n个Broker)和待分配的Partition排序
将第i个Partition分配到第(i mod n)个Broker上 (这个就是leader)
将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
Controller会在ZooKeeper的/brokers/ids节点上注册Watch,一旦有broker宕机,它就能知道。
当Broker宕机后,Controller就会给受到影响的Partition选出新Leader。
Controller从ZooKeeper的/brokers/topics/[topic]/partitions/[partition]/state中,读取对应Partition的ISR(in-sync replica已同步的副本)列表,选一个出来做Leader。
选出Leader后,更新ZooKeeper的存储,然后发送LeaderAndISRRequest给受影响的Broker进行通知。
如果ISR列表是空,那么会根据配置,随便选一个replica做Leader,或者干脆这个partition就是宕机了。
如果ISR列表的有机器,但是也宕机了,那么还可以等ISR的机器活过来。
多副本同步:
服务端这边的处理是Follower从Leader批量拉取数据来同步。但是具体的可靠性,是由生产者来决定的。
生产者生产消息的时候,通过request.required.acks参数来设置数据的可靠性。

在acks=-1的时候,如果ISR少于min.insync.replicas指定的数目,那么就会返回不可用。
这里ISR列表中的机器是会变化的,根据配置replica.lag.time.max.ms,多久没同步,就会从ISR列表中剔除。以前还有根据落后多少条消息就踢出ISR,在1.0版本后就去掉了,因为这个值很难取,在高峰的时候很容易出现节点不断的进出ISR列表。
从ISA中选出leader后,follower会从把自己日志中上一个高水位后面的记录去掉,然后去和leader拿新的数据。因为新的leader选出来后,follower上面的数据,可能比新leader多,所以要截取。这里高水位的意思,对于partition和leader,就是所有ISR中都有的最新一条记录。消费者最多只能读到高水位;
从leader的角度来说高水位的更新会延迟一轮,例如写入了一条新消息,ISR中的broker都fetch到了,但是ISR中的broker只有在下一轮的fetch中才能告诉leader。
也正是由于这个高水位延迟一轮,在一些情况下,kafka会出现丢数据和主备数据不一致的情况,0.11开始,使用leader epoch来代替高水位。
以上是关于Kafka基本知识整理的主要内容,如果未能解决你的问题,请参考以下文章