应该选择RabbitMQ还是Kafka?
Posted 架构文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了应该选择RabbitMQ还是Kafka?相关的知识,希望对你有一定的参考价值。
点击蓝色“架构文摘”关注我哟
加个“星标”,每天上午 09:25,干货推送!
原文:https://medium.com/better-programming/rabbitmq-vs-kafka-1ef22a041793
作为一个有丰富经验的微服务系统架构师,经常有人问我,应该选择 RabbitMQ 还是 Kafka?。
基于某些原因, 许多开发者会把这两种技术当做等价的来看待。的确,在一些案例场景下选择 RabbitMQ 还是 Kafka 没什么差别,但是这两种技术在底层实现方面是有许多差异的。
不同的场景需要不同的解决方案,选错一个方案能够严重的影响你对软件的设计,开发和维护的能力。
这篇文章会先介绍一下基本的异步消息模式,然后再介绍一下 RabbitMQ 和 Kafka 以及他们的内部结构信息。第二部分(未完成)主要介绍这两种技术的主要不同点以及他们各自的优缺点,最后我们会说明一下怎样选择这两种技术。
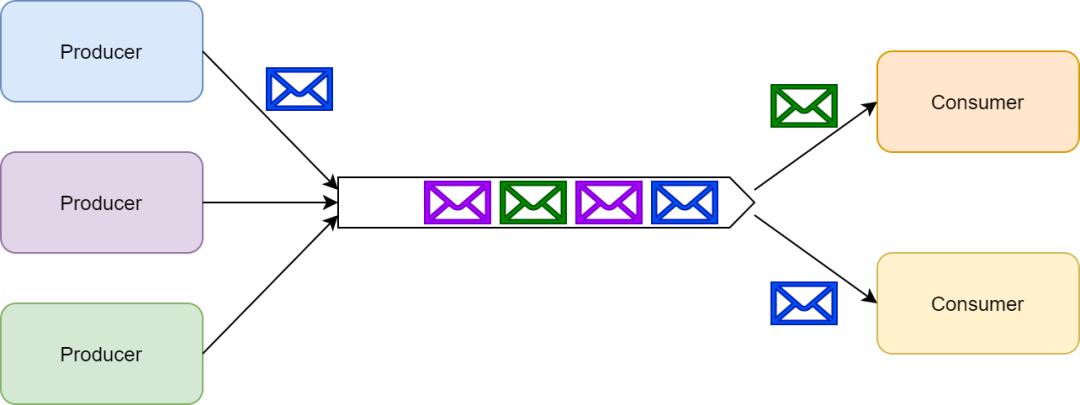
异步消息可以作为解耦消息的生产和处理的一种解决方案。提到消息系统,我们通常会想到两种主要的消息模式——消息队列和发布/订阅模式。
利用消息队列可以解耦生产者和消费者。多个生产者可以向同一个消息队列发送消息。
但是,一个消息在被一个消息者处理的时候,这个消息在队列上会被锁住或者被移除并且其他消费者无法处理该消息。也就是说一个具体的消息只能由一个消费者消费。
需要额外注意的是,如果消费者处理一个消息失败了,消息系统一般会把这个消息放回队列,这样其他消费者可以继续处理。
消息队列除了提供解耦功能之外,它还能够对生产者和消费者进行独立的伸缩(scale),以及提供对错误处理的容错能力。
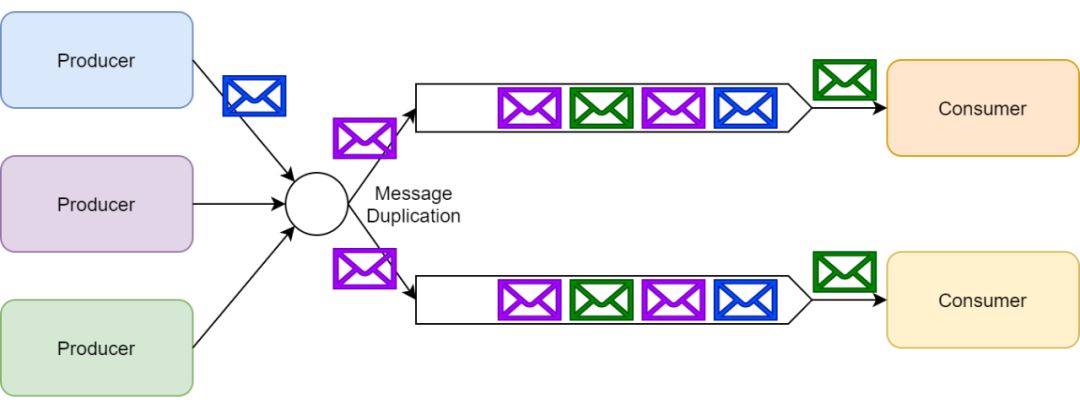
发布/订阅(pub/sub)模式中,单个消息可以被多个订阅者并发的获取和处理。
发布/订阅
例如,一个系统中产生的事件可以通过这种模式让发布者通知所有订阅者。在许多队列系统中常常用主题(topics)这个术语指代发布/订阅模式。
在 RabbitMQ 中,主题就是发布/订阅模式的一种具体实现(更准确点说是交换器(exchange)的一种),但是在这篇文章中,我会把主题和发布/订阅当做等价来看待。
一般来说,订阅有两种类型:
RabbitMQ 作为消息中间件的一种实现,常常被当作一种服务总线来使用。RabbitMQ 原生就支持上面提到的两种消息模式。
其他一些流行的消息中间件的实现有 ActiveMQ,ZeroMQ,Azure Service Bus 以及 Amazon Simple Queue Service(SQS)。
这些消息中间件的实现有许多共通的地方;这边文章中提到的许多概念大部分都适用于这些中间件。
RabbitMQ 支持典型的开箱即用的消息队列。开发者可以定义一个命名队列,然后发布者可以向这个命名队列中发送消息。最后消费者可以通过这个命名队列获取待处理的消息。
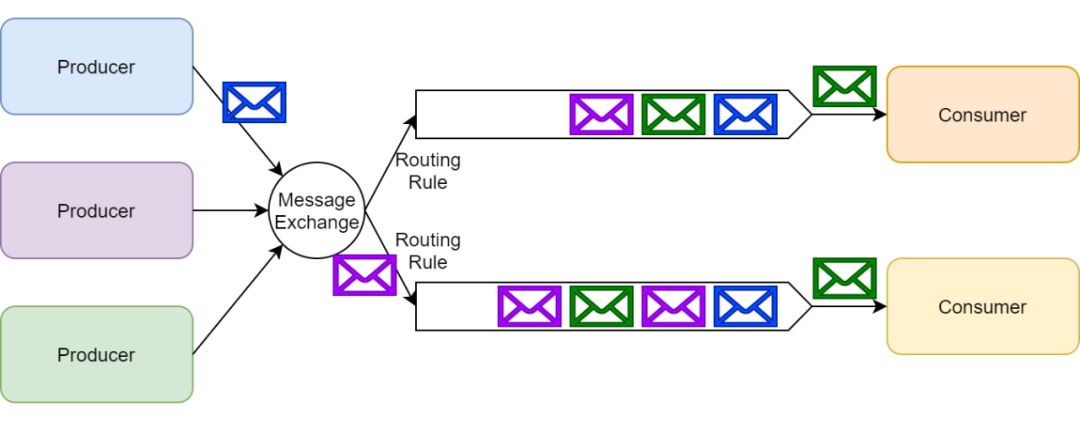
RabbitMQ 使用消息交换器来实现发布/订阅模式。发布者可以把消息发布到消息交换器上而不用知道这些消息都有哪些订阅者。
每一个订阅了交换器的消费者都会创建一个队列;然后消息交换器会把生产的消息放入队列以供消费者消费。消息交换器也可以基于各种路由规则为一些订阅者过滤消息。
需要重点注意的是 RabbitMQ 支持临时和持久两种订阅类型。消费者可以调用 RabbitMQ 的 API 来选择他们想要的订阅类型。
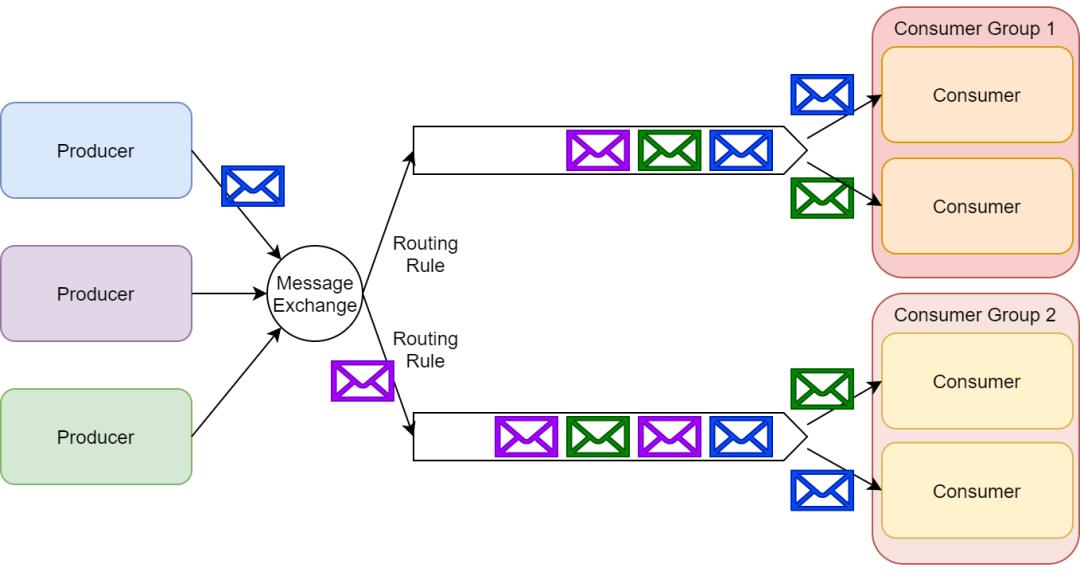
根据 RabbitMQ 的架构设计,我们也可以创建一种混合方法——订阅者以组队的方式然后在组内以竞争关系作为消费者去处理某个具体队列上的消息,这种由订阅者构成的组我们称为消费者组。
按照这种方式,我们实现了发布/订阅模式,同时也能够很好的伸缩(scale-up)订阅者去处理收到的消息。
Apache Kafka 不是消息中间件的一种实现。相反,它只是一种分布式流式系统。
不同于基于队列和交换器的 RabbitMQ,Kafka 的存储层是使用分区事务日志来实现的。
Kafka 也提供流式 API 用于实时的流处理以及连接器 API 用来更容易的和各种数据源集成;当然,这些已经超出了本篇文章的讨论范围。
云厂商为 Kafka 存储层提供了可选的方案,比如 Azure Event Hubsy 以及 AWS Kinesis Data Streams 等。
对于 Kafka 流式处理能力,还有一些特定的云方案和开源方案,不过,话说回来,它们也超出了本篇的范围。
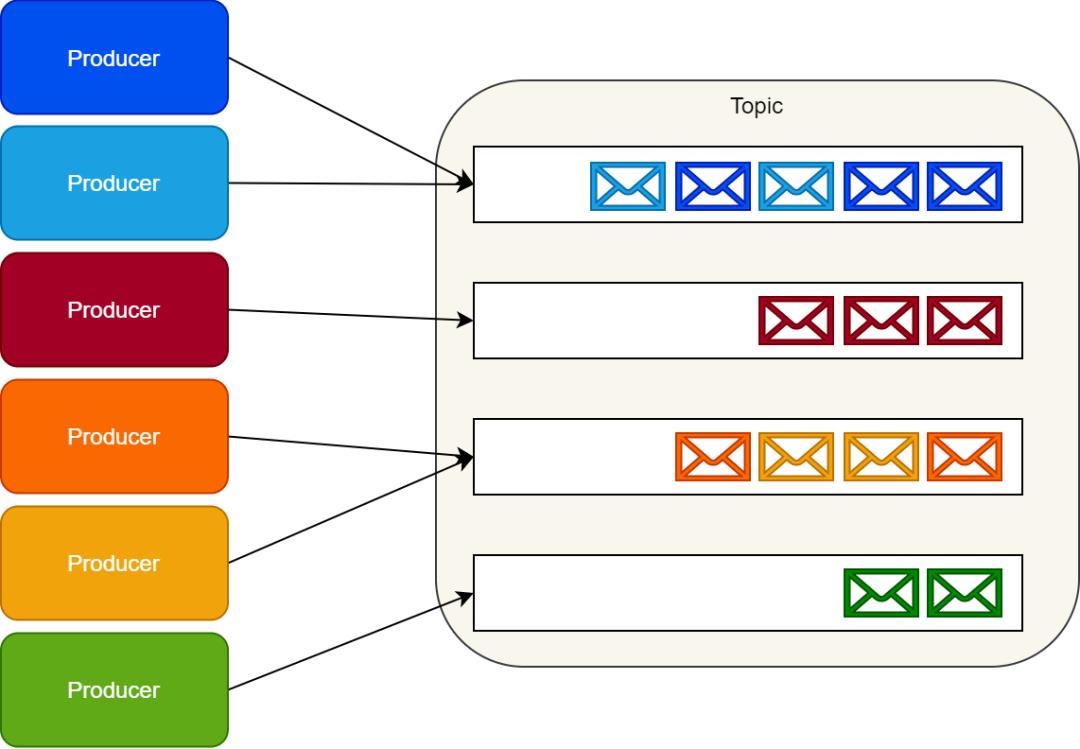
Kafka 没有实现队列这种东西。相应的,Kafka 按照类别存储记录集,并且把这种类别称为主题。
Kafka 为每个主题维护一个消息分区日志。每个分区都是由有序的不可变的记录序列组成,并且消息都是连续的被追加在尾部。
当消息到达时,Kafka 就会把他们追加到分区尾部。默认情况下,Kafka 使用轮询分区器(partitioner)把消息一致的分配到多个分区上。
Kafka 可以改变创建消息逻辑流的行为。例如,在一个多租户的应用中,我们可以根据每个消息中的租户 ID 创建消息流。
IoT 场景中,我们可以在常数级别下根据生产者的身份信息(identity)将其映射到一个具体的分区上。
确保来自相同逻辑流上的消息映射到相同分区上,这就保证了消息能够按照顺序提供给消费者。
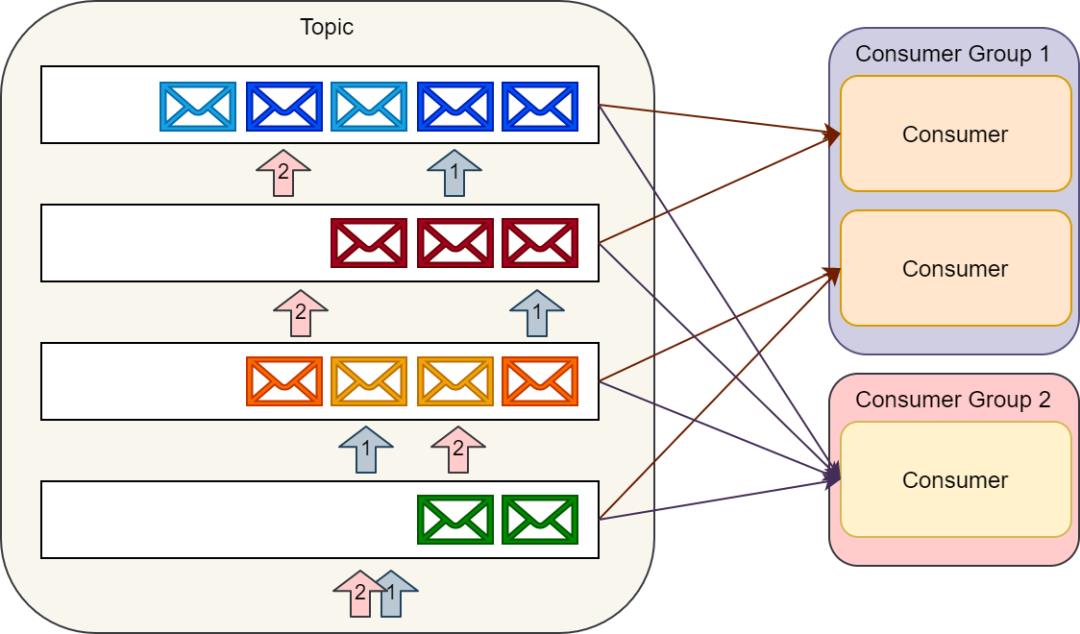
消费者通过维护分区的偏移(或者说索引)来顺序的读出消息,然后消费消息。
单个消费者可以消费多个不同的主题,并且消费者的数量可以伸缩到可获取的最大分区数量。
所以在创建主题的时候,我们要认真的考虑一下在创建的主题上预期的消息吞吐量。消费同一个主题的多个消费者构成的组称为消费者组。
通过 Kafka 提供的 API 可以处理同一消费者组中多个消费者之间的分区平衡以及消费者当前分区偏移的存储。
Kafka 的实现很好地契合发布/订阅模式。
生产者可以向一个具体的主题发送消息,然后多个消费者组可以消费相同的消息。
每一个消费者组都可以独立的伸缩去处理相应的负载。
由于消费者维护自己的分区偏移,所以他们可以选择持久订阅或者临时订阅,持久订阅在重启之后不会丢失偏移而临时订阅在重启之后会丢失偏移并且每次重启之后都会从分区中最新的记录开始读取。
但是这种实现方案不能完全等价的当做典型的消息队列模式看待。当然,我们可以创建一个主题,这个主题和拥有一个消费者的消费组进行关联。
这样我们就模拟出了一个典型的消息队列。不过这会有许多缺点,我们会在第二部分详细讨论。
值得特别注意的是,Kafka 是按照预先配置好的时间保留分区中的消息,而不是根据消费者是否消费了这些消息。
这种保留机制可以让消费者自由的重读之前的消息。另外,开发者也可以利用Kafka的存储层来实现诸如事件溯源和日志审计功能。
尽管有时候 RabbitMQ 和 Kafka 可以当做等价来看,但是他们的实现是非常不同的。
所以我们不能把他们当做同种类的工具来看待;一个是消息中间件,另一个是分布式流式系统。
作为解决方案架构师,我们要能够认识到它们之间的差异并且尽可能的考虑在给定场景中使用哪种类型的解决方案。
第二部分(未完成)会指出这些差异并且提供什么时候使用哪种方案的指导建议,后面会为大家更新。
如有收获,点个在看,诚挚感谢
以上是关于应该选择RabbitMQ还是Kafka?的主要内容,如果未能解决你的问题,请参考以下文章
选型必看:RabbitMQ 七战 Kafka,差异立现
注意了!Kafka与RabbitMQ千万不要乱用…
RabbitMQ与Kafka的技术差异以及使用注意点
也许你真的不懂RabbitMQ和Kafka的区别!!
选型必看:RabbitMQ 七战 Kafka,差异立现
Kafka还是RabbitMQ?