超详细!一文详解 SparkStreaming 如何整合 Kafka !附代码可实践
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详细!一文详解 SparkStreaming 如何整合 Kafka !附代码可实践相关的知识,希望对你有一定的参考价值。

来源 | Alice菌
责编 | Carol
封图 | CSDN 下载于视觉中国
出品 | CSDN(ID:CSDNnews)
相信很多小伙伴已经接触过 SparkStreaming 了,理论就不讲太多了,今天的内容主要是为大家带来的是 SparkStreaming 整合 Kafka 的教程。
文中含代码,感兴趣的朋友可以复制动手试试!

Kafka回顾
正式开始之前,先让我们来对Kafka回顾一波。
-
核心概念图解
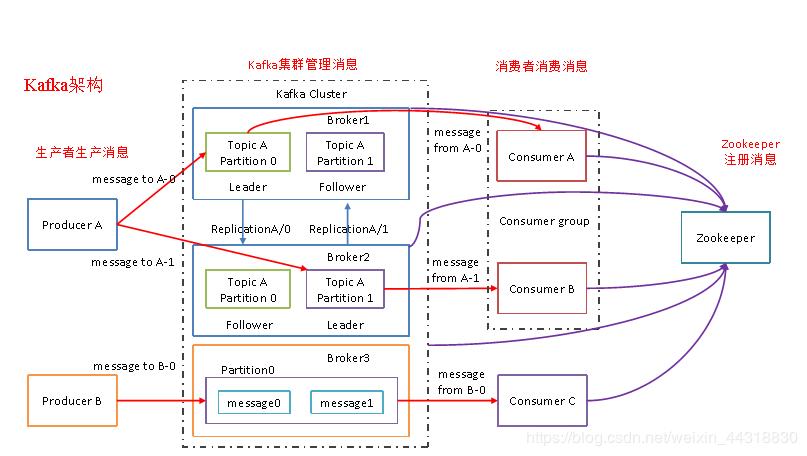
-
常用命令
/export/servers/kafka/bin/kafka-server-start.sh -daemon
/export/servers/kafka/config/server.properties
/export/servers/kafka/bin/kafka-server-stop.sh
/export/servers/kafka/bin/kafka-topics.sh --list --zookeeper node01:2181
/export/servers/kafka/bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 3 --partitions 3 --topic test
/export/servers/kafka/bin/kafka-topics.sh --describe --zookeeper node01:2181 --topic test
/export/servers/kafka/bin/kafka-topics.sh --zookeeper node01:2181 --delete --topic test
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list node01:9092 --topic spark_kafka
/export/servers/kafka/bin/kafka-console-consumer.sh --zookeeper node01:2181 --topic spark_kafka--from-beginning
/export/servers/kafka/bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic spark_kafka --from-beginning

整合kafka两种模式说明
-
KafkaUtils.createDstream(开发中不用,了解即可,但是面试可能会问)。 -
Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦 -
Receiver哪台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低! -
Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护。 -
spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致 -
所以不管从何种角度来说,Receiver模式都不适合在开发中使用了,已经淘汰了
-
KafkaUtils.createDirectStream(开发中使用,要求掌握) -
Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高了并行能力
-
Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况
-
当然也可以自己手动维护,把offset存在mysql、redis中
-
所以基于Direct模式可以在开发中使用,且借助Direct模式的特点+手动操作可以保证数据的Exactly once 精准一次
-
Receiver接收方式
-
多个Receiver接受数据效率高,但有丢失数据的风险 -
开启日志(WAL)可防止数据丢失,但写两遍数据效率低。 -
Zookeeper维护offset有重复消费数据可能。 -
使用高层次的API
-
Direct直连方式
-
不使用Receiver,直接到kafka分区中读取数据 -
不使用日志(WAL)机制 -
Spark自己维护offset -
使用低层次的API
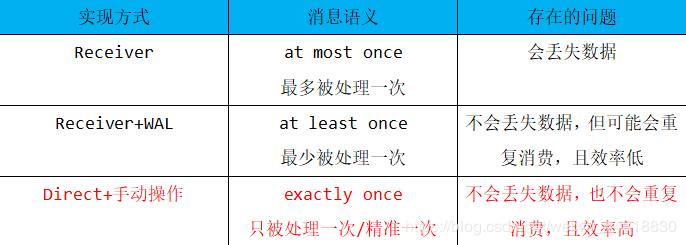 注意:
注意:

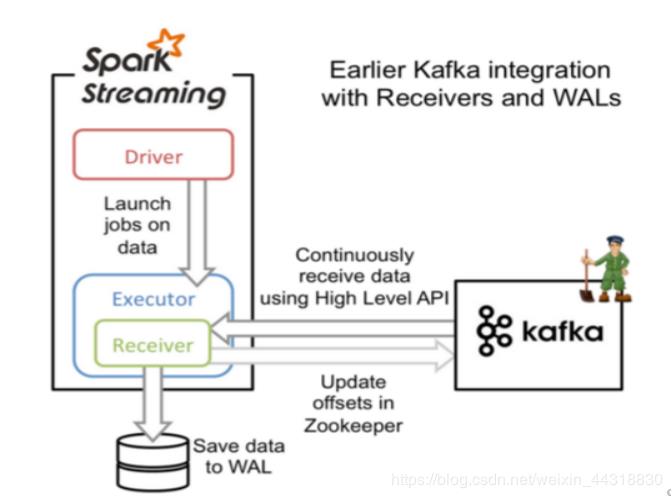
-
准备工作
zkServer.sh start
kafka-server-start.sh /export/servers/kafka/config/server.properties
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 3 --topic spark_kafka
kafka-console-producer.sh --broker-list node01:9092 --topic spark_kafka
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.2.0</version>
</dependency>
-
API
val receiverDStream: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map(x => {
val stream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
stream
})
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.immutable
object SparkKafka {
def main(args: Array[String]): Unit = {
//1.创建StreamingContext
val config: SparkConf =
new SparkConf().setAppName("SparkStream").setMaster("local[*]")
.set("spark.streaming.receiver.writeAheadLog.enable", "true")
//开启WAL预写日志,保证数据源端可靠性
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./kafka")
//==============================================
//2.准备配置参数
val zkQuorum = "node01:2181,node02:2181,node03:2181"
val groupId = "spark"
val topics = Map("spark_kafka" -> 2)//2表示每一个topic对应分区都采用2个线程去消费,
//ssc的rdd分区和kafka的topic分区不一样,增加消费线程数,并不增加spark的并行处理数据数量
//3.通过receiver接收器获取kafka中topic数据,可以并行运行更多的接收器读取kafak topic中的数据,这里为3个
val receiverDStream: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map(x => {
val stream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
stream
})
//4.使用union方法,将所有receiver接受器产生的Dstream进行合并
val allDStream: DStream[(String, String)] = ssc.union(receiverDStream)
//5.获取topic的数据(String, String) 第1个String表示topic的名称,第2个String表示topic的数据
val data: DStream[String] = allDStream.map(_._2)
//==============================================
//6.WordCount
val words: DStream[String] = data.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
2.Direct
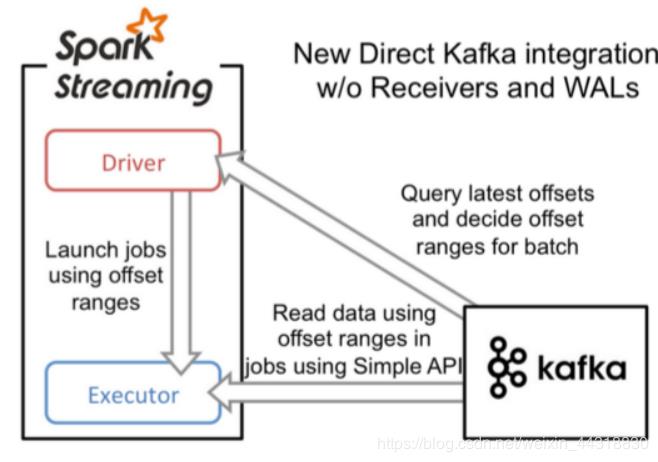
-
Direct的缺点是无法使用基于zookeeper的kafka监控工具 -
Direct相比基于Receiver方式有几个优点:
-
简化并行 不需要创建多个kafka输入流,然后union它们,sparkStreaming将会创建和kafka分区数一样的rdd的分区数,而且会从kafka中并行读取数据,spark中RDD的分区数和kafka中的分区数据是一一对应的关系。 -
高效 Receiver实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次,第一次是被kafka复制,另一次是写到WAL中。而Direct不使用WAL消除了这个问题。 -
恰好一次语义(Exactly-once-semantics) Receiver读取kafka数据是通过kafka高层次api把偏移量写入zookeeper中,虽然这种方法可以通过数据保存在WAL中保证数据不丢失,但是可能会因为sparkStreaming和ZK中保存的偏移量不一致而导致数据被消费了多次。
-
API
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkKafka2 {
def main(args: Array[String]): Unit = {
//1.创建StreamingContext
val config: SparkConf =
new SparkConf().setAppName("SparkStream").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./kafka")
//==============================================
//2.准备配置参数
val kafkaParams = Map("metadata.broker.list" -> "node01:9092,node02:9092,node03:9092", "group.id" -> "spark")
val topics = Set("spark_kafka")
val allDStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
//3.获取topic的数据
val data: DStream[String] = allDStream.map(_._2)
//==============================================
//WordCount
val words: DStream[String] = data.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}

spark-streaming-kafka-0-10
-
说明
-
pom.xml
<!--<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
</dependency>-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
-
API:
-
创建topic
/export/servers/kafka/bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 3 --partitions 3 --topic spark_kafka
-
启动生产者
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list node01:9092,node01:9092,node01:9092 --topic spark_kafka
-
代码演示
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkKafkaDemo {
def main(args: Array[String]): Unit = {
//1.创建StreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5表示5秒中对数据进行切分形成一个RDD
//准备连接Kafka的参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "SparkKafkaDemo",
//earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
//这里配置latest自动重置偏移量为最新的偏移量,即如果有偏移量从偏移量位置开始消费,没有偏移量从新来的数据开始消费
"auto.offset.reset" -> "latest",
//false表示关闭自动提交.由spark帮你提交到Checkpoint或程序员手动维护
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("spark_kafka")
//2.使用KafkaUtil连接Kafak获取数据
val recordDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,//位置策略,源码强烈推荐使用该策略,会让Spark的Executor和Kafka的Broker均匀对应
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))//消费策略,源码强烈推荐使用该策略
//3.获取VALUE数据
val lineDStream: DStream[String] = recordDStream.map(_.value())//_指的是ConsumerRecord
val wrodDStream: DStream[String] = lineDStream.flatMap(_.split(" ")) //_指的是发过来的value,即一行数据
val wordAndOneDStream: DStream[(String, Int)] = wrodDStream.map((_,1))
val result: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
result.print()
ssc.start()//开启
ssc.awaitTermination()//等待优雅停止
}
}

【END】
更多精彩推荐
开源激荡 30 年:从免费社区到价值数十亿美元公司
理解 AI 最伟大的成就之一:卷积神经网络的局限性
☞
☞
☞
以上是关于超详细!一文详解 SparkStreaming 如何整合 Kafka !附代码可实践的主要内容,如果未能解决你的问题,请参考以下文章