事件驱动架构 全面了解Kafka和RabbitMQ选型 -两种不同的消息传递方式
Posted 超级架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了事件驱动架构 全面了解Kafka和RabbitMQ选型 -两种不同的消息传递方式相关的知识,希望对你有一定的参考价值。
在这一部分中,我们将探讨RabbitMQ和Apache Kafka以及它们的消息传递方法。每种技术在设计的每个方面都做出了截然不同的决定,每种方面都有优点和缺点。我们不会在这一部分得出任何有力的结论,而是将其视为技术的入门,以便我们可以深入探讨该系列的后续部分。
RabbitMQ
RabbitMQ是一个分布式消息队列系统。分布式,因为它通常作为节点集群运行,其中队列分布在节点上,并可选择复制以实现容错和高可用性。它原生地实现了AMQP 0.9.1,并通过插件提供其他协议,如STOMP,MQTT和HTTP。
RabbitMQ同时采用经典和新颖方式。从某种意义上来说,它是面向消息队列的经典,并且具有高度灵活的路由功能。正是这种路由功能才是其杀手级功能。构建快速,可扩展,可靠的分布式消息传递系统本身就是一项成就,但消息路由功能使其在众多消息传递技术中脱颖而出。
交换机(exchanges)和队列
超简化概述:
发布者向交换机(exchanges)发送消息
将消息路由到队列和其他交换机(exchanges)
RabbitMQ在收到消息时向发布者发送确认
消费者与RabbitMQ保持持久的TCP连接,并声明他们使用哪个队列
RabbitMQ将消息推送给消费者
消费者发送成功/失败的确认
成功使用后,消息将从队列中删除
隐藏在该列表中的是开发人员和管理员应该采取的大量决策,以获得他们想要的交付保证,性能特征等,我们将在本系列的后续部分中介绍所有这些决策。
我们来看看单个发布者,交换机(exchanges),队列和消费者:
Fig 1 - Single publisher and single consumer
如果您有多个同一消息的发布者怎么办?如果我们有多个消费者每个人都希望消费每条消息呢?
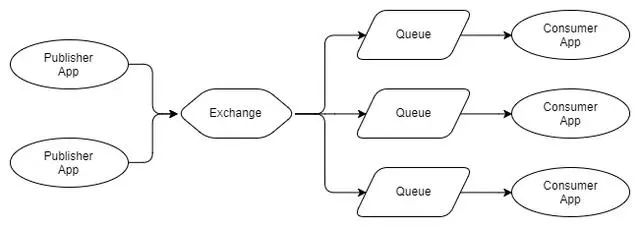
Fig 2 - Multiple publishers, multiple independent
如您所见,发布者将其消息发送到同一个交换机(exchanges),该交换机(exchanges)将每条消息路由到三个队列,每个队列都有一个消费者。使用RabbitMQ,队列使不同的消费者能够使用每条消息。与下图对比:
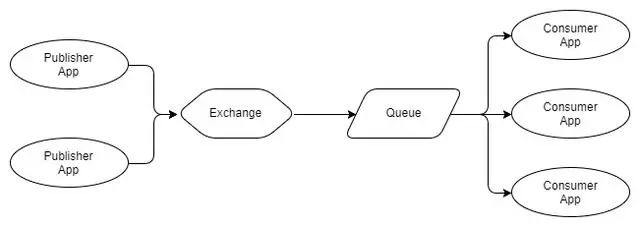
Fig 3 - Multiple publishers, one queue with multip
在图3中,我们有三个消费者都在单个队列中消费。这些是竞争的消费者,即他们竞争消费单个队列的消息。人们可以预期,平均而言,每个消费者将消耗该队列消息的三分之一。我们使用竞争消费者来扩展我们的消息处理,使用RabbitMQ它非常简单,只需按需添加或删除消费者。无论您拥有多少竞争消费者,RabbitMQ都将确保消息仅传递给单个消费者。
我们可以将图2和图3组合在一起,使多组竞争消费者,每组消费每条消息。
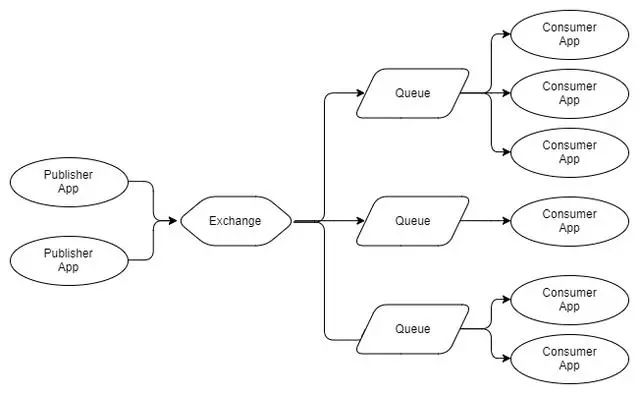
Fig 4 - Multiple publishers, multiple queues with
交换和队列之间的箭头称为绑定,我们将仔细研究本系列第2部分中的箭头。
担保
RabbitMQ提供“最多一次交付”和“至少一次交付”但不提供“完全一次交付”保证。我们将在本系列的第4部分中深入研究消息传递保证。
消息按照到达队列的顺序传递(毕竟是队列的定义)。当您拥有竞争消费者时,这并不能保证完成与完全相同顺序的消息处理匹配。这不是RabbitMQ的错,而是并行处理有序消息集的基本现实。通过使用Consistent Hashing Exchange可以解决此问题,您将在下一部分中看到模式和拓扑。
推和消费者预选
RabbitMQ将消息推送到流中的消费者。有一个Pull API,但它的性能很糟糕,因为每条消息需要一个请求/响应往返(注意,由于Shiva Kumar的评论,我更新了这一段)。
如果消息到达队列的速度快于消费者可以处理的速度,那么基于推送的系统可能会使消费者感到压力。因此,为了避免这种情况,每个消费者都可以配置预取限制(也称为QoS限制)。这基本上是消费者在任何时候都可以拥有的未确认消息的数量。当消费者开始落后时,这可以作为安全切断开关。
为什么推而不拉?首先,它对于低延迟非常有用。其次,理想情况下,当我们拥有单个队列的竞争消费者时,我们希望在它们之间均匀分配负载。如果每个消费者都会收到消息,那么根据他们拉动工作分布的数量,可能会变得非常不平衡。消息分布越不均匀,延迟越多,处理时消息顺序的丢失越多。因此,RabbitMQ的Pull API只允许一次提取一条消息,但这会严重影响性能。这些因素使RabbitMQ倾向于推动机制。这是RabbitMQ的缩放限制之一。通过将确认组合在一起可以改善它。
路由
交换基本上是到队列和/或其他交换的消息的路由器。为了使消息从交换机传送到队列或其他交换机,需要绑定。不同的交换需要不同的绑定。有四种类型的交换和相关绑定:
扇出(Fanout)。路由到具有绑定到交换的所有队列和交换。标准的pub子模型。
直接。根据发布者设置的消息随附的路由密钥路由消息。路由键是一个短字符串。直接交换将消息路由到具有与路由密钥完全匹配的绑定密钥的队列/交换机。
话题。根据路由密钥路由消息,但允许通配符匹配。
头。RabbitMQ允许将自定义标头添加到消息中。标头根据这些标头值交换路由消息。每个绑定包括完全匹配标头值。可以将多个值添加到具有匹配所需的ANY或ALL值的绑定。
一致的哈希。这是一个哈希路由密钥或邮件头并仅路由到一个队列的交换。当您需要使用扩展的消费者处理订单保证时,这非常有用。
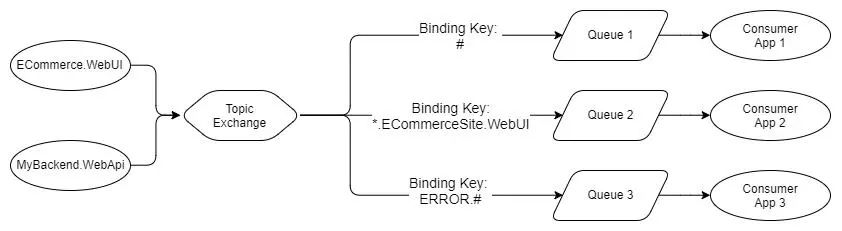
Fig 5. Topic exchange example
我们将在第2部分中更仔细地研究路由,但上面是主题交换的示例。发布者使用路由密钥格式LEVEL.AppName发布错误日志。
队列1将使用多字#通配符接收所有消息。
队列2将接收ECommerce.WebUI应用程序的任何日志级别。它使用覆盖日志级别的单字*通配符。
队列3将查看来自任何应用程序的所有ERROR级别消息。它使用多字#通配符来覆盖所有应用程序。
通过四种路由消息的方式,以及允许交换路由到其他交换,RabbitMQ提供了一组功能强大且灵活的消息传递模式。接下来我们将讨论死信交换,短暂交换和队列,您将开始看到RabbitMQ的强大功能。
死信交换机(Dead Letter Exchanges)
我们可以配置队列在以下条件下向交换机发送消息:
队列超过配置的消息数。
队列超出配置的字节数。
消息生存时间(TTL)已过期。发布者可以设置消息的生命周期,队列也可以有消息TTL。哪个更短适用。
我们创建一个绑定到死信交换的队列,这些消息将存储在那里直到采取行动。在另一篇文章中,我描述了我已经实现的拓扑,其中所有死信的消息都发送到中央清算所,支持团队可以在此决定采取何种措施。
与许多RabbitMQ功能一样,死信交换提供了最初未考虑的额外模式。我们可以使用消息TTL和死信交换来实现延迟队列和重试队列,包括指数退避。请参阅我之前的帖子。
短暂的交流和队列(Ephemeral Exchanges and Queues)
可以动态创建交换和队列,并赋予自动删除特征。经过一段时间后,他们可以自我毁灭。这允许诸如用于基于消息的RPC的ephermal回复队列之类的模式。
插件
您要安装的第一个插件是Management Plug-In,它提供HTTP服务器,Web UI和REST API。它非常易于安装,并为您提供易于使用的UI,以帮助您启动和运行。通过REST API进行脚本部署也非常简单。
其他一些插件包括:
一致的哈希交换,Sharding Exchange等
像STOMP和MQTT这样的协议
网络钩子
额外的交换类型
SMTP集成
RabbitMQ还有很多东西,但这是一本很好的入门书,让您了解RabbitMQ可以做些什么。现在我们来看看Kafka,它采用了完全不同的消息传递方法,并且具有惊人的功能。
Apache Kafka
Kafka是一个分布式复制的提交日志。Kafka没有队列的概念,因为它主要用作消息系统,所以最初可能看起来很奇怪。长期以来,队列一直是消息传递系统的代名词。让我们分解一下“分布式,复制的提交日志”:
分布式,因为Kafka被部署为节点集群,用于容错和扩展
复制,因为消息通常跨多个节点(服务器)复制。
提交日志因为消息存储在分区中,所以只追加称为主题的日志。这种日志概念是Kafka的主要杀手特征。
了解日志(主题)及其分区是理解Kafka的关键。那么分区日志与一组队列有什么不同呢?让我们想象一下吧。
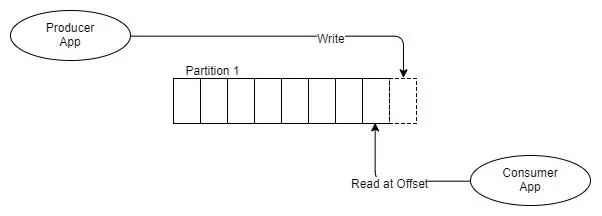
Fig 6 One producer, one partition, one consumer
Kafka不是将消息放入FIFO队列并跟踪像RabbitMQ那样在队列中跟踪该消息的状态,而是将其附加到日志中,就是这样。无论消耗一次还是一千次,该消息都会保留。它根据数据保留策略(通常是窗口时间段)删除。那么主题如何被消费?每个消费者跟踪它在日志中的位置,它有一个指向消耗的最后消息的指针,该指针称为偏移量。消费者通过客户端库维护此偏移量,并且根据Kafka的版本,偏移量存储在ZooKeeper或Kafka本身中。ZooKeeper是一种分布式共识技术,被许多分布式系统用于领导者选举等领域。Kafka依靠ZooKeeper来管理集群的状态。
这个日志模型的惊人之处在于它立即消除了消息传递状态的大量复杂性,更重要的是消费者,它允许它们倒回并返回并消耗先前偏移量的消息。例如,假设您部署了一个计算发票的服务,该发票消耗了客户预订。该服务有一个错误,并在24小时内错误地计算所有发票。最好使用RabbitMQ,您需要以某种方式重新发布这些预订,并仅发送给发票服务。但是对于Kafka,您只需将该消费者的偏移量移回24小时。
因此,让我们看一下具有单个分区和两个消费者的主题的情况,每个消费者都需要消费每条消息。从现在开始,我已经开始为消费者贴上标签,因为它不是那么清晰(如RabbitMQ图),它们是独立的,也是竞争对手的消费者。
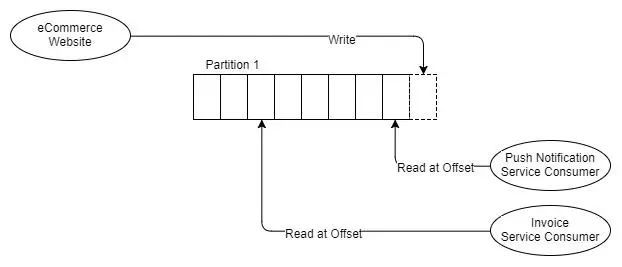
Fig 7 One producer, one partition, two independent
从图中可以看出,两个独立的消费者都使用相同的分区,但他们正在从不同的偏移中读取。也许发票服务处理消息所需的时间比推送通知服务要长,或者发票服务可能会停机一段时间并且赶上,或者可能存在错误并且其偏移量必须移回几个小时。
现在让我们说发票服务需要扩展到三个实例,因为它无法跟上消息速度。使用RabbitMQ,我们只需部署两个发票服务应用程序,这些应用程序将使用预订发票服务队列。但是Kafka不支持单个分区上的竞争消费者,Kafka的并行单元就是分区本身。因此,如果我们需要三个发票消费者,我们至少需要三个分区。所以现在我们有:
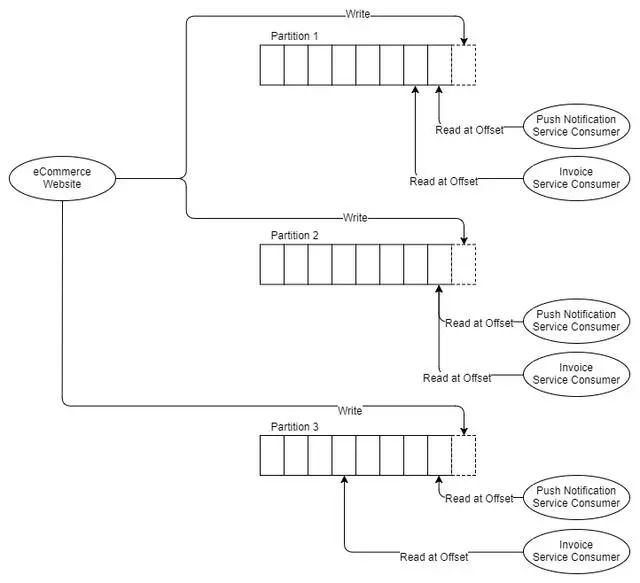
Fig 8 Three partitions and two sets of three consu
因此,这意味着您至少需要与最大规模的消费者一样多的分区。我们来谈谈分区。
分区和消费者组
每个分区都是一个单独的数据文件,可保证消息排序。这一点很重要:消息排序只能保证在一个分区内。这可能会在消息排序需求和性能需求之间引入一些紧张,因为并行单元也是分区。一个分区不能支持竞争消费者,因此我们的发票应用程序只能有一个实例消耗每个分区。
消息可以循环方式或通过散列函数路由到分区:散列(消息密钥)%分区数。使用散列函数有一些好处,因为我们可以设计消息密钥,使得同一实体的消息(例如预订)始终转到同一分区。这可以实现许多模式和消息排序保证。
消费者群体就像RabbitMQ的竞争消费者。组中的每个使用者都是同一应用程序的实例,并将处理主题中所有消息的子集。尽管RabbitMQ的竞争消费者都使用相同的队列,但消费者群体中的每个消费者都使用同一主题的不同分区。因此,在上面的示例中,发票服务的三个实例都属于同一个使用者组。
在这一点上,RabbitMQ看起来更加灵活,它保证了队列中的消息顺序,以及它应对不断变化的竞争消费者数量的无缝能力。使用Kafka,如何对日志进行分区非常重要。
Kafka从一开始就有一个微妙而重要的优势,即RabbitMQ后来添加的关于消息顺序和并行性的优点。RabbitMQ维护整个队列的全局顺序,但在并行处理该队列期间无法维护该顺序。Kafka无法提供该主题的全局排序,但它确实提供了分区级别的排序。因此,如果您只需要订购相关消息,那么Kafka提供有序消息传递和有序消息处理。想象一下,您有消息显示客户预订的最新状态,因此您希望始终按顺序(按时间顺序)处理该预订的消息。如果您按预订ID进行分区,那么给定预订的所有消息都将到达单个分区,我们会在其中进行消息排序。因此,您可以创建大量分区,使您的处理高度并行化,并获得消息排序所需的保证。
RabbitMQ中也存在此功能,它通过Consistent Hashing交换机以相同的方式在队列上分发消息。虽然Kafka强制执行此有序处理,因为每个使用者组只有一个使用者可以使用单个分区,并且当协调器节点为您完成所有工作以确保遵守此规则时,可以轻松实现。而在RabbitMQ中,您仍然可以让竞争消费者从一个“分区”队列中消费,并且您必须完成工作以确保不会发生这种情况。
这里还有一个问题,当你改变分区数量时,订单Id 1000的那些消息现在转到另一个分区,因此订单Id 1000的消息存在于两个分区中。根据您处理邮件的方式,这会引起头疼。现在存在消息不按顺序处理的情况。
我们将在本系列的第4部分“消息传递语义和保证”部分中更详细地介绍此主题。
PUSH VS PULL
RabbitMQ使用推送模型,并通过消费者配置的预取限制来防止压倒性的消费者。这对于低延迟消息传递非常有用,并且适用于RabbitMQ基于队列的架构。另一方面,Kafka使用拉模型,消费者从给定的偏移量请求批量消息。当没有超出当前偏移量的消息时,为了避免紧密循环,Kafka允许进行长轮询。
由于其分区,拉模型对Kafka有意义。由于Kafka在没有竞争消费者的分区中保证消息顺序,我们可以利用消息批处理来实现更高效的消息传递,从而为我们提供更高的吞吐量。这对RabbitMQ没有多大意义,因为理想情况下我们希望尽可能快地分配一个消息,以确保工作均匀并行处理,并且消息处理接近它们到达队列的顺序。但是对于Kafka来说,分区是并行和消息排序的单位,所以这两个因素都不是我们关注的问题。
发布订阅
Kafka支持基本的pub sub,其中包含一些与日志相关的额外模式,它是一个日志并具有分区。生成器将消息附加到日志分区的末尾,并且消费者可以在分区中的任何位置放置它们的偏移量。
Fig 9. Consumers with different offsets
当存在多个分区和使用者组时,这种风格的图表不容易快速解释,因此对于Kafka的其余图表,我将使用以下样式:
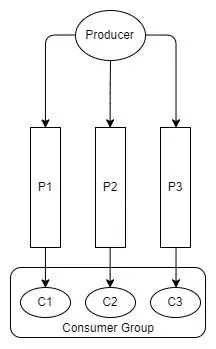
Fig 10. One producer, three partitions and one con
我们的消费者群体中没有与分区相同数量的消费者:
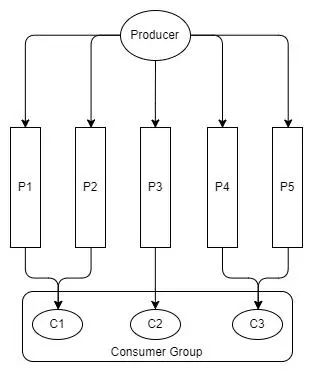
Fig 11. Sone consumers read from more than one par
一个消费者组中的消费者将协调分区的消耗,确保一个分区不被同一个消费者组的多个消费者使用。
同样,如果我们拥有的消费者多于分区,那么额外的消费者将保持闲置状态。
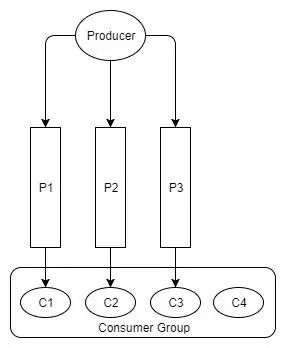
Fig 12. One idle consumer
添加和删除消费者后,消费者群体可能会变得不平衡。重新平衡会在分区中尽可能均匀地重新分配使用者。
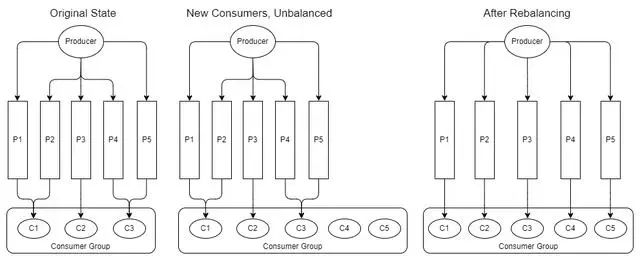
Fig 13. Addition of new consumers requires rebalan
在以下情况之后自动触发重新平衡:
消费者加入消费者群体
消费者离开消费者群体(它关闭或被视为死亡)
添加了新分区
重新平衡将导致短时间的额外延迟,同时消费者停止阅读批量消息并分配到不同的分区。消费者维护的任何内存状态现在都可能无效。Kafka的消费模式之一是能够将给定实体的所有消息(如给定的预订)指向同一个分区,从而导致同一个消费者。这称为数据局部性。在重新平衡任何内存中有关该数据的数据将是无用的,除非将消费者分配回同一分区。因此,维持国家的消费者需要在外部坚持下去。
日志压缩
标准数据保留策略是基于时间和空间的策略。存储到最后一周的消息或最多50GB,例如。但是存在另一种类型的数据保留策略 - 日志压缩。压缩日志时,结果是仅保留每个消息密钥的最新消息,其余消息将被删除。
让我们假设我们收到一条消息,其中包含用户预订的当前状态。每次更改预订时,都会根据预订的当前状态生成新事件。该主题可能包含一些预订的消息,这些消息表示自创建以来预订的状态。在主题被压缩之后,将仅保留与该预订相关的最新消息。
根据预订量和每次预订的大小,理论上可以将所有预订永久存储在主题中。通过定期压缩主题,我们确保每个预订只存储一条消息。
日志压缩可以实现一些不同的模式,我们将在第3部分中探讨。
有关消息排序的更多信息
我们已经讨论过,RabbitMQ和Kafka都可以扩展和维护消息排序,但是Kafka使它变得容易多了。使用RabbitMQ,我们必须使用Consistent Hashing Exchange并使用像ZooKeeper或Consul这样的分布式共识服务自己手动实现使用者组逻辑。
但RabbitMQ有一个有趣的功能,卡夫卡没有。RabbitMQ本身并不特别,但任何基于发布 - 订阅队列的消息传递系统。能力是这样的:基于队列的消息系统允许订户订购任意事件组。
让我们再深入了解一下。不同的应用程序无法共享队列,因为它们会竞争使用消息。他们需要自己的队列。这使应用程序可以自由地配置他们认为合适的队列。他们可以将多个主题中的多个事件类型路由到其队列中。这允许应用程序维护相关事件的顺序。它想要组合的事件可以针对每个应用程序进行不同的配置。
使用像Kafka这样的基于日志的消息传递系统是不可能的,因为日志是共享资源。多个应用程序从同一日志中读取。因此,将相关事件分组到单个主题中是在更广泛的系统架构级别做出的决策。
所以这里没有胜利者。RabbitMQ允许您维护任意事件集的相对排序,Kafka提供了一种维持大规模排序的简单方法。
更新:我已经构建了一个名为Rebalanser的库,它为RabbitMQ for .NET应用程序提供了使用者组逻辑。查看它上面的帖子和GitHub repo。如果人们表现出任何兴趣,那么我就会用其他语言制作版本。让我知道。
结论
RabbitMQ由于其提供的各种功能,提供了瑞士军刀的消息模式。凭借其强大的路由功能,它可以消除消费者在只需要一个子集时检索,反序列化和检查每条消息的需要。它易于使用,通过简单地添加和删除消费者来完成扩展和缩小。它的插件架构允许它支持其他协议并添加新功能,例如Consistent散列交换,这是一个重要的补充。
卡夫卡的分布式日志与消费者抵消使得时间旅行成为可能。它能够将相同密钥的消息按顺序路由到同一个消费者,从而实现高度并行化的有序处理。Kafka的日志压缩和数据保留允许RabbitMQ无法提供的新模式。最后是的,Kafka可以比RabbitMQ进一步扩展,但是我们大多数人都处理一个可以轻松处理的消息量。
在下一部分中,我们将使用RabbitMQ仔细研究消息传递模式和拓扑。
| 微信公众号 | 微信公众号【首席架构师智库】 |  |
| 微信小号 | 希望加入的群:企业架构,云计算,大数据,数据科学,物联网,人工智能,安全,全栈开发,DevOps,数字化,产品转型。 | |
| 视频号 | 首席架构师智库 | |
| 知识星球 | 向大咖提问,近距离接触,或者获得私密资料分享。 | |
| 微信圈子 | 志趣相投的同好交流。 | |
| 喜马拉雅 | 路上或者车上了解最新黑科技资讯,架构心得。 | |
| 知识星球 | 认识更多朋友,职场和技术闲聊。 |
以上是关于事件驱动架构 全面了解Kafka和RabbitMQ选型 -两种不同的消息传递方式的主要内容,如果未能解决你的问题,请参考以下文章