通俗易懂带你看懂时间序列分解模型?高深也不过如此
Posted 数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通俗易懂带你看懂时间序列分解模型?高深也不过如此相关的知识,希望对你有一定的参考价值。
观察趋势,或许是我们在日常分析中最常见的需求。但遗憾的是,许多管理者或者业务分析人员,对着高高低低的折线图(时间序列数据)不知道怎么“看”。本节将介绍一种通俗易懂的时间序列分解方法,帮助大家从时间序列的波动中挖掘信息。另外,时间序列数据经过分解之后,可以对未来的数值进行一定程度的预测。
5.5.1 怎样观察时间序列数据
别小看一个简简单单的时间序列的折线图,怎么看这个图,可是大有文章。简单归纳如下。
1.X轴和Y轴
任何图表观察都要从图表元素开始,时间序列图也不会例外。通过观察两个坐标轴,能知道数据的时间范围有多长、颗粒度有多细(小时、天、周、月等)、指标的大小如何(最大值、最小值、单位等)。别忘了其他图表元素。
2.起点和终点
观察时间序列的起点和终点,在不观察细节的情况下,就能大体知道总体趋势是怎么走的。如图5-32所示,起点与终点数值差不多,那么我们知道,不管3月~11月间指标变化多么波澜壮阔,至少一头一尾说明忙活了半年多是在原地踏步。
图5-32 如何观察时间序列
3.观察极值
极值就是序列中比较大的值和比较小的值,当然包括最大值和最小值。极值的观察是确定数据阶段的重要依据。
4.转折点
转折点往往有两类。一类是绝对数值的转折点,一般就是指最大值和最小值。另一类是波动信息的转折点。例如,在该点前后的波动幅度差别显著,或者在该点前后波动周期有差别,或者在该点前后数据的正负值出现变化等。
5.周期性
需要观察数据的涨跌是不是有规律可循。在实际业务中,很多数据是会有周期性的,尤其是周末和周中,会有明显的不同。这种不同有时出现在数值的高低上(打车数一般周一早上和周五晚较高,周末较低),有时出现在数据的结构上(外卖订单数量在工作日和周末差别不大,但在送达地点和送达时间上差别巨大)。
6.波动性
在某些阶段,数值波动剧烈;某些阶段则平稳。这也是在观察中需要注意的信息。从统计学的角度分析,方差大的阶段,往往涵盖的信息较多,需要更加关注。
7.与参考线的对比
参考线有许多,例如均值线、均值加减标准差线、KPI目标线、移动平均线等。每种参考线都有分析意义,但需要注意顺序,建议先对比均值线,然后是移动平均线,之后才是各种自定义的参考线。
通过上述7点的观察,我们能了解一个时间序列的变化趋势、周期和变动阶段。有了对这三部分的认知,我们就可以进入下一步,将时间序列中隐藏的信息分解出来。
5.5.2 何为时间序列分解
时间序列数据,即数据指标按时间维度统计形成的序列。这种数据在我们的日常报表中非常常见。观察这类数据的出发点有两个:一是长期追踪,一旦指标出现上涨和下跌,能直观地观察到,进而去调查原因;二是判断趋势,通过指标的波动,判断指标在未来的走势。第一点相对简单,看到指标变化后从不同维度不断下钻,总能找到原因。第二点则要从时间序列的波动中看出门道,不是光盯着数据看就可以的,最常见的逻辑就是“将时间序列波动的信息进行分解”。
通过某些方法,将数据分解成可预测部分和不规则变动(随机波动)部分,可预测部分占比比不规则变动大很多,那么就具备了预测未来的条件。如图5-33所示,时间序列可以分为长期趋势(trend)、季节变动(seasonal)、循环变动(cycling)和随机波动(irregular)四个部分。四个部分的组成方式可分为加法模型、乘法模型和混合模型三类。加法模型可表示为:D=T+S+C+I;乘法模型表示为:D=T×S×C×I;混合模型就是公式中既有加号也有乘号。
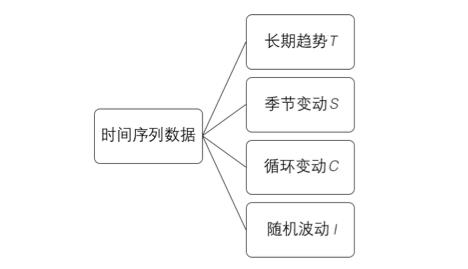
图5-33 时间序列的分解模型
我们以最容易理解的加法模型举例。先对T、S、C和I四个部分做简单的阐述。
1.T
数据中对时间的变化相对稳定的一部分因素。往往是长期稳定的上涨或下跌。这个数据一般可以通过移动平均或者线性回归等方法进行拟合,因此它是可预测的部分。
2.S
传统的时间序列分解方法一般用在长期的宏观经济指标中,因此颗粒度是季度,所以会呈季节性变动。在数据运营的场景中,季节数据跨度太长,几乎没有使用的必要性。所以将季节变动引申为“周期性波动”,而且是显性的周期性波动,例如业务指标在一周内会有周末和工作日的差别,在一个月中会有月初和月末的差别。周期性波动因素取决于数据处在周期中的位置,通过固定位置的历史数据(取均值或者其他数学变换),也能对未来的某个位置的周期性因素进行估计,因此它也是可预测的部分。
3.C
循环变动和季节变动其实很像,也有周期性因素在。但循环变动的周期是隐性的,往往要先将显性的周期性波动排除后,再观察剩下的数据部分是否有循环波动的因素,若有,也能通过同比计算等方法将其提出,因此也是可预测的。
4.I
既然是随机波动,自然是不可预测的。
时间序列分解的成功与否,取决于两个因素:一是数据序列本身是隐藏着规律的,不可预测的部分只是其中的一小部分;二是分解的方法要合适,尤其是周期的判断要准确。因此,这个方法非常考验使用者的经验和直觉。
5.5.3 时间序列分解的步骤解析
以川术公司很长一段时期的活跃用户数量为例,阐明时间序列分解的过程。由于教科书中的数据过于理想化,偏离现实太远,因此我们用脱敏的现实数据反映真实的过程,读者要注意分解的套路。
1.用移动平均数分离出显性的周期性波动
拿到数据后,第一步就是清洗数据,将异常值剔除。在本例中,我们将2016年10月1日~10月7日的数据删除了,因为国庆节期间的数据与其他时段的数据不可比。第二步,根据现实的业务周期(活跃用户数在周末会减少,工作日会增加),按周期的长度求移动平均数。这样一来,所获得的移动平均数就是排除了业务周期波动影响和一部分随机波动的数据。如图5-34所示,活跃用户7日移动平均线实际上就包含了长期趋势、循环变动和一部分不规则变动,而活跃用户数(原始数据)与移动平均数的差值,就是业务周期效应和一部分不规则变动。
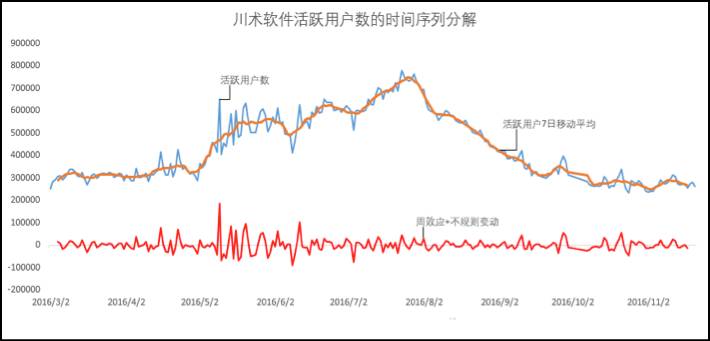
图5-34 时间序列分解步骤说明1
2.将业务周期效应和不规则变动进行区分
这部分的处理取决于周效应和不规则变动的量级。在实际场景中,若量比较大,建议计算每周中对应某一天的均值,即得到周一的均值、周二的均值等,这便是加法模型中的周效应。
图5-35所示为将原始数据减去移动平均数的差值分解为周效应和不规则变动后的结果。读者有没有想到,若周效应是稳定的且数量比较大,那么从“周效应+不规则变动”中分离出周效应后,剩下的不规则变动应该显著变小。但在本例中,分离后不规则变动和移动平均数的波动差距并不大。说明本例中的周效应并不稳定或者数量很小,这是现实数据中经常会遇到的情况。若是周效应和不规则变动的总和的数值不大,且较均匀地分布在横坐标轴的上下,就说明这一步的分解是不必要的。
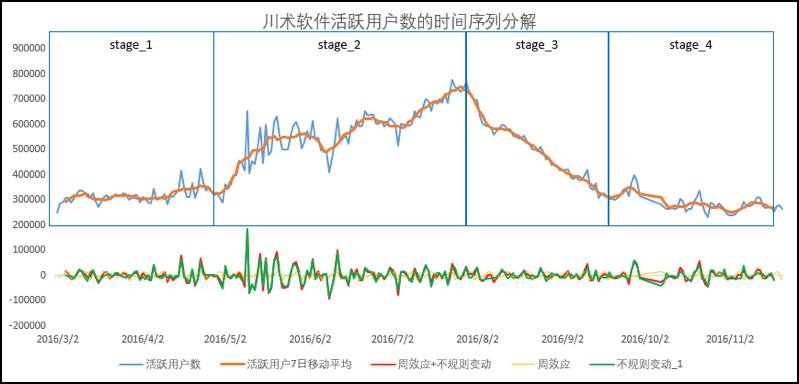
图5-35 时间序列分解步骤说明2
3.观察数据波动的拐点,将时间序列分段
在图5-35中,通过观察活跃用户的7日移动平均数,能够清晰地将数据波动分为4个阶段(虽然有BP、EFP等时间序列的断点检验方法,但往往肉眼观察更奏效)。这个步骤往往是教科书中忽略的,却在现实应用中十分重要。为什么要对移动平均后的数据分段呢?因为移动平均数包含了数据的长期趋势和循环变动。首先,长期趋势是会改变的,这种改变往往是运营策略的变化带来的,所以不能教条地假设长期趋势稳定不变。其次,在数据的不同阶段,循环的周期也会有所不同。在图5-35中,其实能很显著地观察到这两个信息。
阶段1的活跃用户数是平稳的,而到了阶段2,活跃用户数的整体趋势向上爬升,但带有明显的涨跌周期。在阶段3,活跃用户数的趋势线性下降,且没有波动周期。在阶段4,活跃用户数的趋势又趋于平稳,且没有明显的周期波动。有了上面这段描述,将时间序列分段就非常有必要了。
4.利用线性回归,基于移动平均数计算长期趋势
这个步骤可以说是时间序列分解中最核心的一个环节。原始数据在剔除了业务周期波动和随机波动后,剩下了长期趋势和循环变动。长期趋势与时间的增加是有关系的(建模的原始假设),因此以时间为自变量(起点为0,之后每天都以1自增的序列),以活跃用户数的7日移动平均数为因变量,构建一个线性回归模型。由时间和回归模型计算得出的因变量的估计值,就是长期趋势T。
如图5-36中的虚线所示,我们将其分为四个阶段,对日期和活跃用户数的7日移动平均数建立了4个线性回归模型,求得了长期趋势。这个建模过程可以在Excel的单元格中完成。需要使用LINEST()和INDEX()两个函数。LINEST()函数用于获得按线性模型建模的结果,而INDEX()函数用于取出LINEST()所获得的结果中的具体的某个值,比如回归系数和截距。
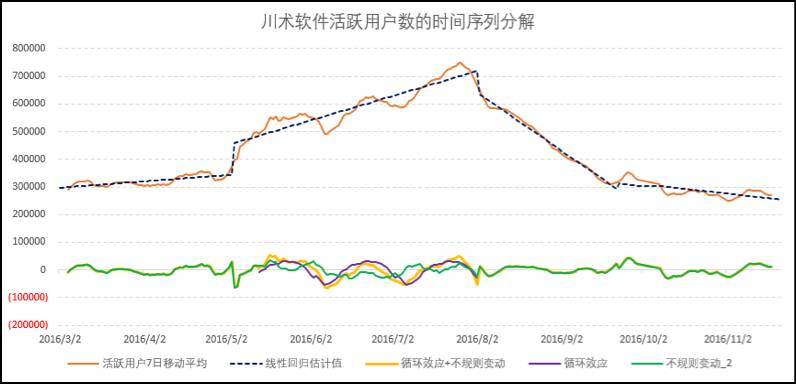
图5-36 时间序列分解步骤说明3
获得线性回归模型的回归系数(即b)=INDEX(LINEST($F$6:$F$66,$B$6:$B$66,TRUE,FALSE),1)
获得线性回归模型的截距(即a)=INDEX(LINEST($F$6:$F$66,$B$6:$B$66,TRUE,FALSE), 2)
具体函数中的参数意义可以参考Excel的帮助文档。
活跃用户的7日移动平均数减去线性回归的预测值(长期趋势)后,剩下的部分就是循环效应和一部分的随机波动(不规则变动)。需要注意的是,估计长期趋势(趋势拟合的方法)并不是只能采用线性回归。这取决于数据点的分布,有时要用指数回归,有时要用多项式回归。而且,在数据的不同阶段,使用的长期趋势估计方式也可以是不同的。
5.分离出循环效应和随机波动
这一步考验分析者的眼力。因为循环效应不是那么容易观察出来的。一个简单的观察办法是:看数据是否有规律地分布在0值之上和0值之下。若数据不规则地在0值上下跳动,则可以认定这是随机波动,不需要分离循环效应。若数据一段时间在0之上,一段时间在0之下,且持续的时间大致相同,那么就有必要分离循环效应。
如图5-36所示,在第二阶段存在明显的循环效应。我们认为,一个波峰加一个波谷所跨越的时间,就是循环的周期(这个规则适用于所有周期性数据的判断)。我们确定了30天的循环周期后,根据这段时间的数据,计算循环中各个位置的均值,即为循环效应。活跃用户数的7日移动平均数与线性回归值的差值,即“循环效应+不规则变动”,减去循环效应后(除了阶段2,其他阶段的循环效应认为是0),剩下的就是随机波动。
综合来说,时间序列数据的预测值就是长期趋势(线性回归估计值)+循环效应(循环周期各位置的均值)+周期效应(业务周期各位置的均值)。这就意味着,能通过时间长度和所在周期的位置给出一个未知时间点的预测值。
6.检验时间序列分解的效果
图5-37所示为活跃用户数的实际值和采用时间序列分解方法的预测值。预测是否有效的第一种手段就是图形法,观察预测值与实际值的契合程度。从本例看,两者契合得相当不错。
第二种方法是回归分析法。以预测值为自变量,实际值为因变量,建立一个线性回归模型,观察模型的拟合优度,通过拟合优度判断预测是否靠谱。0.954的拟合优度,说明模型不能预测的信息只占原始数据信息中的 4.6%,这是非常可喜的结果。说明在本例中所采取的分解过程还是相当靠谱的,如图5-38所示。
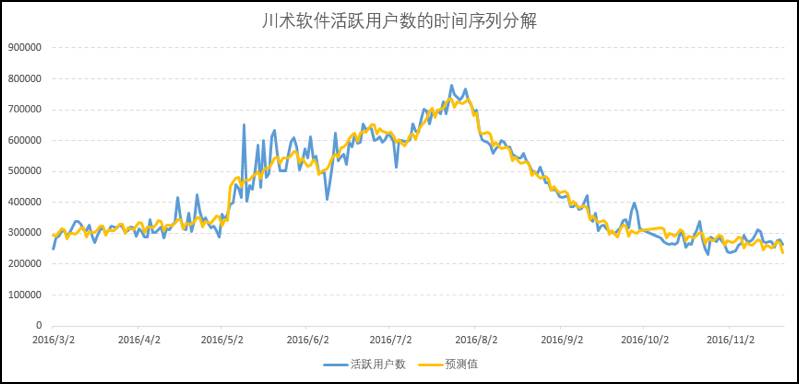
图5-37 时间序列分解的效果检验1
图5-38 时间序列分解的效果检验2
5.5.4 时间序列分解方法的应用局限性
每种分析方法都有它的局限性,时间序列分解方法也一样,但请读者保持乐观,“分解”这种思维,事实上是可以应用在更广泛的业务分析中的,而不仅是时间序列数据。通过以上案例,我们需要注意时间序列分解法中的以下几点局限性。
原始数据中的随机波动因素占比不能过大。随机波动因素的占比过大,说明我们不可预测的东西过多,那么,剩余的部分再怎么分解也无济于事。
分解的过程中,确定移动平均的期数、数据阶段的划分、趋势拟合的方法、循环周期都带有一定的主观判断。这就对分析者提出了较高的要求。在应用时,需要不断地改变这些参数来获得更好的结果。而且,经常会出现仁者见仁的局面。
用加法模型、乘法模型或混合模型没有定论,需要具体问题具体分析。实际情况中,往往是混合模型用得比较多。
需要用在长期的数据序列中。时间序列的分解对时间的长度是有要求的,却没有明确的阈值。至少要在40个数据点以上才能讨论所谓的长期趋势。另外,该方法不适合用在比“天”的颗粒度更小的时间维度上。
时间序列阶段的改变可预测性较差。细心的读者应该发现了,在上文的分解过程中,有一个将整个数据序列分为4个阶段的过程。观察历史数据时,划分阶段并不难;难的是作为“局中人”,将时间序列分解的结果应用于预测时,是不知道何时进入新的阶段的(序列的结构性断点不可预测)。今天还在阶段1,明天就进入阶段2了,这可如何是好?有一些缓解这个问题的方法:一是做“事后诸葛亮”,即连续追踪数据,若连续出现上涨或者下跌,或者出现“史无前例”的最大值和最小值,那么就要考虑数据的结构性变化可能出现了,就要放弃原先的建模方式;二是从业务决策上“明察秋毫”,数据出现结构性变化,往往是较大的决策改变或者产品迭代引起的,那么反过来思考,若业务出现一些“重大改变”,也许就应该重新建模了。
真正的预测,只能在阶段内进行。在本例中能预测未来数据的其实也就只有阶段4。但也不用慌,历史往往会重演。前面三个阶段的数据特征,一定会出现在未来的某个时间点。所以,当数据进入有“历史参考”的某个阶段时,可以用历史经验预测未来的走势。
想了解更多请点击文末 “ 阅读原文 ”购买此书查阅。
原创系列文章:
5 :
6:
数据运营 关联文章阅读:
数据分析、数据产品 关联文章阅读:
商务合作|约稿 请加qq:365242293
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
以上是关于通俗易懂带你看懂时间序列分解模型?高深也不过如此的主要内容,如果未能解决你的问题,请参考以下文章