时间序列预测与优秀数据科学工程师
Posted 金融科技实战
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时间序列预测与优秀数据科学工程师相关的知识,希望对你有一定的参考价值。
前几天看了陆奇关于优秀工程师的演讲,感觉他说的基本都是大实话。演讲中提到的五个观点分别是Believe in 技术、站在巨人的肩膀上做创新、追求Engineering Excellence、每天学习、Ownership。
总体来说对工程师的洗脑因素有之,但理解一下也未尝不可。这里结合实际数据挖掘工作,谈一下对优秀工程师的认识。
优秀的数据科学工程师
关于技术,一直以来我都相信技术的力量,并以此为基础在单位开展工作。数据驱动其实就是技术驱动,想要通过技术驱动改变业务经营,那首先要建立必备的技术自信心,这样才能说服业务人员和你站在一条战线上。业务人员认可你能够把控好交付的模型和产品,也会信赖你提供的技术和支持,最终目标是双赢。当然,如果脱离技术逻辑,无论讲的多么真诚的演讲我都觉得是在忽悠,比如最近在国内人工智能领域走穴的那位历史学家。
站在巨人的肩膀上创新,意思是说不要重复造轮子,而是擅于挑选合适的工具和方法去解决问题。实际经验是要用工程化的思维去工作,都要具备基本的项目管理意识和知识。在现有条件下做出务实的创新,这才是大多数技术人员的使命。另外,涉及到数据科学、人工智能或机器学习的创新应用,在面临新问题的时候可以多读读文献,选择合适的方法进行实验。
追求工程卓越性,也就是大家经常聊的工匠精神了。通俗的讲,做完一件事,一定要前后左右多提一些问题。多提问题就意味着多思考,对应着交付内容更加严谨、科学与务实。具体到数据挖掘,一方面要求模型的结果做到最精准,另一方面还要考虑模型如何才能更好的发挥作用,也就是要实际落地。
每天学习是基本功了,听说读写是研究生的四门基本功课,同样适合于于数据科学领域的创新工作。我的知识管理工具有一些,有道云笔记和Endnote做文献管理,onenote做日常笔记,freemind做脑图。每天都需要学习与思考,因为大数据和人工智能领域的技术更新换代很快,昨天用的方法可能今天就不适用了。
最后,关于Ownership,其实并不是太好谈。假大空没意义,我觉得只要能够不懈怠、保持职业素养就不错了。
时间序列预测
说起来跟时间序列预测还是挺有缘的,研究生期间发过两篇混沌时间序列预测的论文;一篇用的神经网络,一篇用的支持向量机,都是热门流行的算法。工作后也做过两次,上次用了ARIMA,这次用的是LSTM,这两算法之间似乎有明显的代沟。
对比统计学和机器学习,不同的背景可能会建立各自的鄙视链;其实都是工具嘛,能解决实际问题就好。
之所以这两项内容进行承接,是因为应用不同方法建立不同场景的时间序列预测模型,整个过程颇为复杂,综合了学术创新和工程实践能力,似乎可以作为检验数据科学工程师能力的一个标准。对照前面优秀工程师的几个观点,除了OwnerShip,都可以相互印证一下。
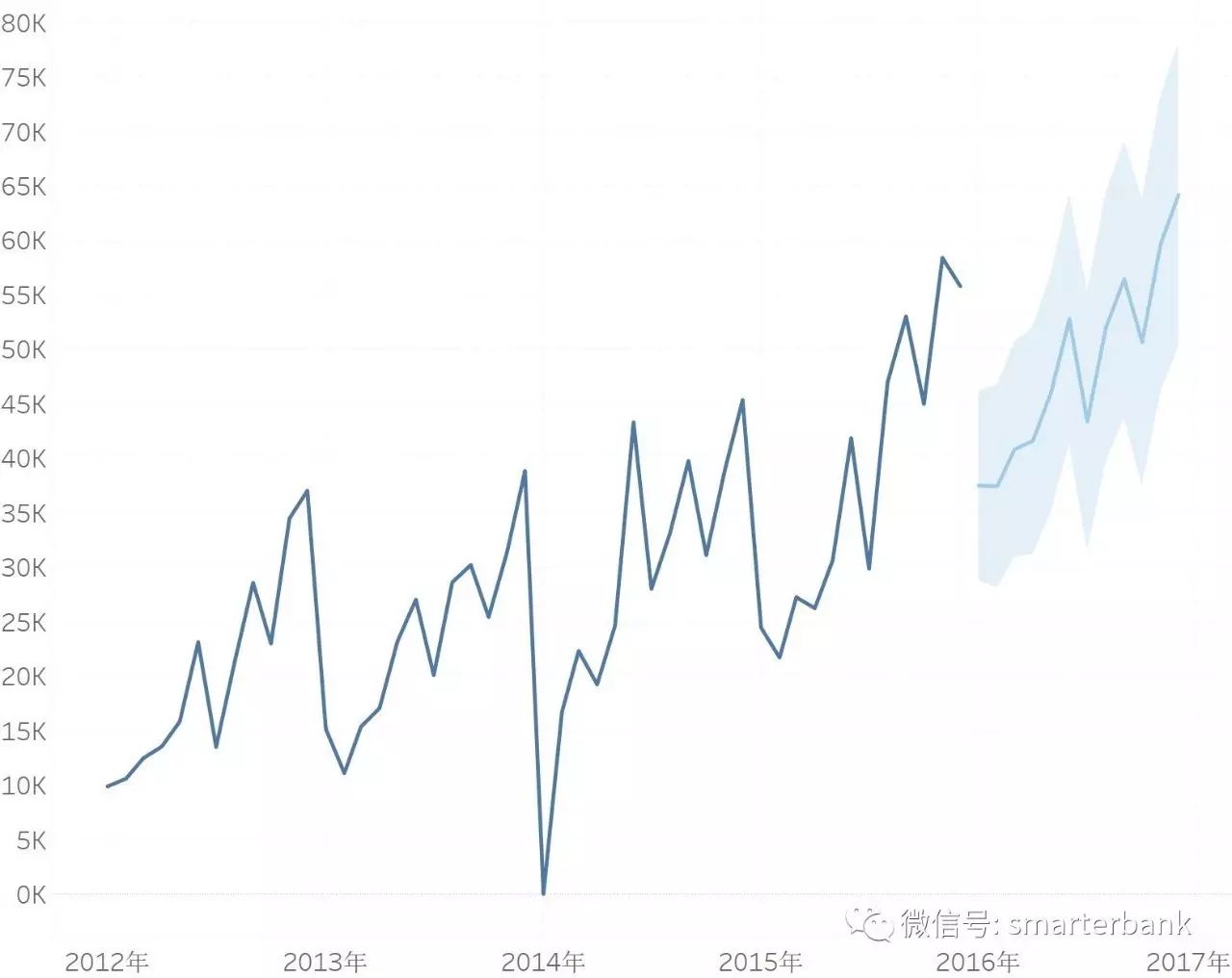
实际建模的背景不多讲,基本过程可以查阅相关文献,这里简单聊一下这几个方法和示例。当然,还有其他的方法进行时间序列预测,这里只是把用过的方法列举下。
1、ARIMA模型
ARIMA模型全称为自回归积分滑动平均模型(Auto regressive Integrated Moving Average Model,简记ARIMA)。ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。
所谓ARIMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。
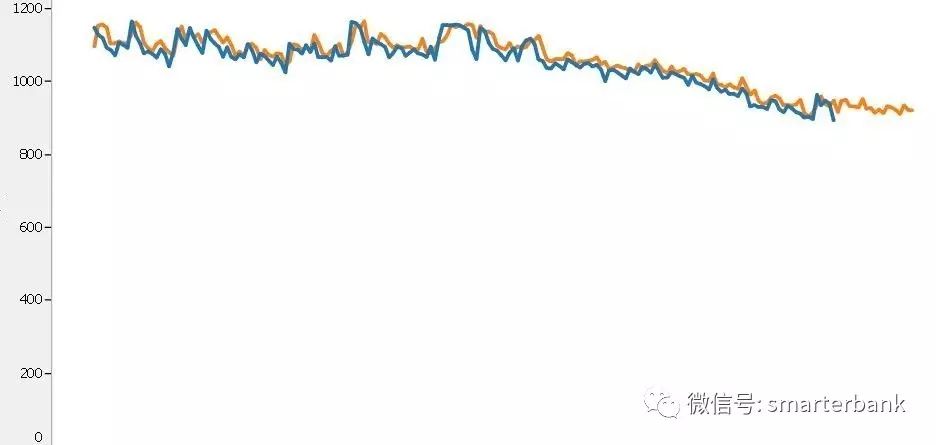
上图用ARIMA做的产品余额预测,结果还不错,预测部分的MAPE为3%。
2、SVM
支持向量机(Support Vector Machine,SVM) 算法是经典的机器学习算法之一,无论在理论分析还是实际应用中都已取得很好的成果,SVM的理论基础是Vapnik提出的“结构风险最小化"原理。SVM算法泛化能力很强,在解决很多复杂问题时有很好的表现。除了数据分类方面应用,SVM逐渐被推广到回归分析、多种背景的模式识别、数据挖掘、函数逼近拟合、医学诊断等众多领域。
SVM的思想源于线性学习器,可以将线性可分的两种不同类型的样例自动划分为两类。如果这两类样例不是线性可分的,则可以使用核函数方法,将实验对象的属性表达在高维特征空间上,并由最优化理论的学习算法进行训练,实现由统计学习理论推导得出的学习偏置,从而达到分类的效果,这就是SVM的基本思路。
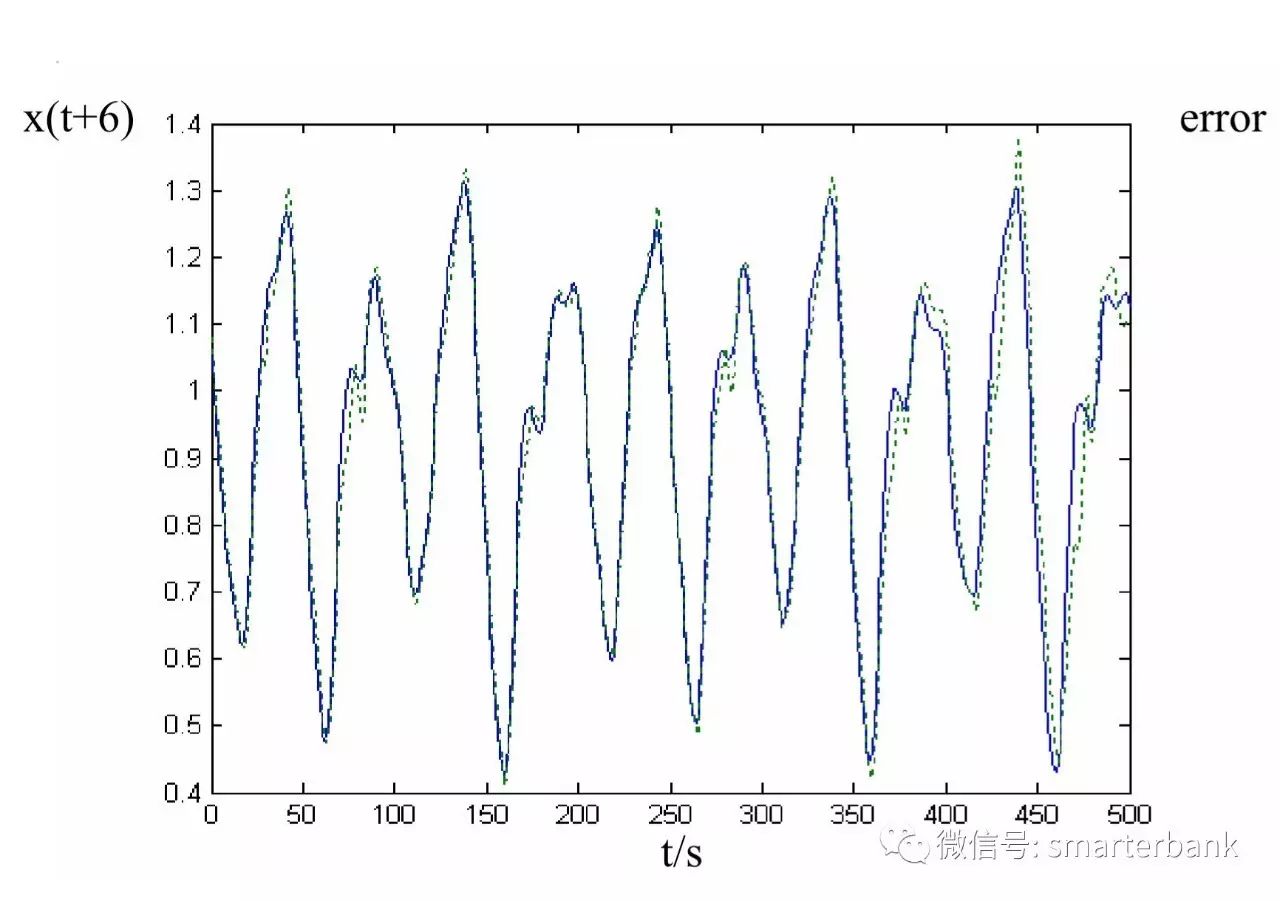
上图为用SVR做的混沌时间序列预测,非常准。为了写论文,需要把算法搞得尽量复杂;实际工作中,更加追求简洁和稳定。
3、LSTM
LSTM,全称为长短期记忆网络(Long Short Term Memory networks),是一种特殊的RNN,能够学习到长期依赖关系。LSTM由Hochreiter & Schmidhuber (1997)提出,许多研究者进行了一系列的工作对其改进并使之发扬光大。
LSTM在许多问题上效果非常好,现在被广泛使用。LSTM可以应用到语言翻译、控制机器人、图像分析、文档摘要、语音识别图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等任务中。
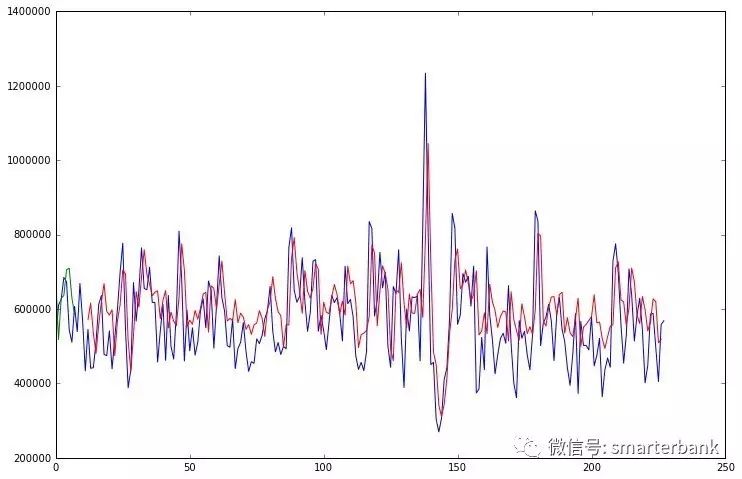
上图为用LSTM做的时间序列预测模型,预测部分的MAPE是17%;相比前面几个当然效果最差,但其实已经可以用了。同样的数据,LSTM表现效果稍强于SVR,比ARIMA强了很多。不同的业务场景,或者说不同的数据条件下,需要选择适合的算法模型。
关于Forecast和Predict
关于时间序列分析,严格的说对应的都是Forecast这个单词。其预测对象都是同一个,基于历史观测值预测未来某段时间的值。如果非要与Predict区分,那么这个可以翻译成预报,比如天气预报。至于Predict,其不同训练样本对应着不同的对象,预测的目标则是其他的对象,比如信用评分。
本文通过不同场景下的时间序列预测方法和经验,简单聊了一下对于优秀数据科学工程师的理解。每天学习,坚持思考,工匠精神,简单务实,追求实际效果,这是优秀工程师的基本素质,也需要孜孜不倦的努力才能实现。
最后,大多数的数据科学家都仅仅是Title而已,工程师才是实实在在的内涵。
文章已经差不多了,主题内容是励志篇和技术篇,片尾再加个彩蛋。
最近去听了Strata 2017大会,由Cloudera和Oreilly主办,这是大数据领域干货比较多的论坛。基本上人工智能和机器学习已经成为今年的主流话题,spark的讨论要远多于hadoop自身的发展。另外,大会的学术气息也还行,很多高标准的分享主题。
总体上人工智能的技术讨论没问题,但有同事说关于深度学习的场景太少了。我想即便真有场景,甲方也不会细致讲出来的,至于靠乙方那自然是不可能的。技术都ok了,甲方当自强。
对于人工智能在银行的应用,我的观点是坚持实事求是,绝对不忽悠。随便弄个POC拿出来讲很容易,对于乙方还可以理解,但甲方这样干绝对会被人笑死的。
至于人工智能和深度学习在银行的应用场景,我的想法和要做的内容主要有两个。一是上面做的LSTM时间序列预测模型,这是一个比较靠谱的模型,毕竟效果在那摆着,不是用为了复杂而复杂。另外一个就是结合复杂网络与深度学习,在风控、反欺诈领域再搞点内容,比如把去年在信用卡审批反欺诈的模型继续做一下。
实现了点的突破,后面应该是面的普及,还有就是技术平台的完善。TF是可以搞一下的,补充到数据挖掘基础设施里面;Intel的BigDL也不错,针对至强处理器加了料。
最后,其实从数据挖掘的创新上相比同业我们做的已经不错了,不足还是在落地应用的深度和广度,毕竟创新与应用是相辅相成的。

这是Hadoop之父Doug Cutting,个子很高,精神的很。
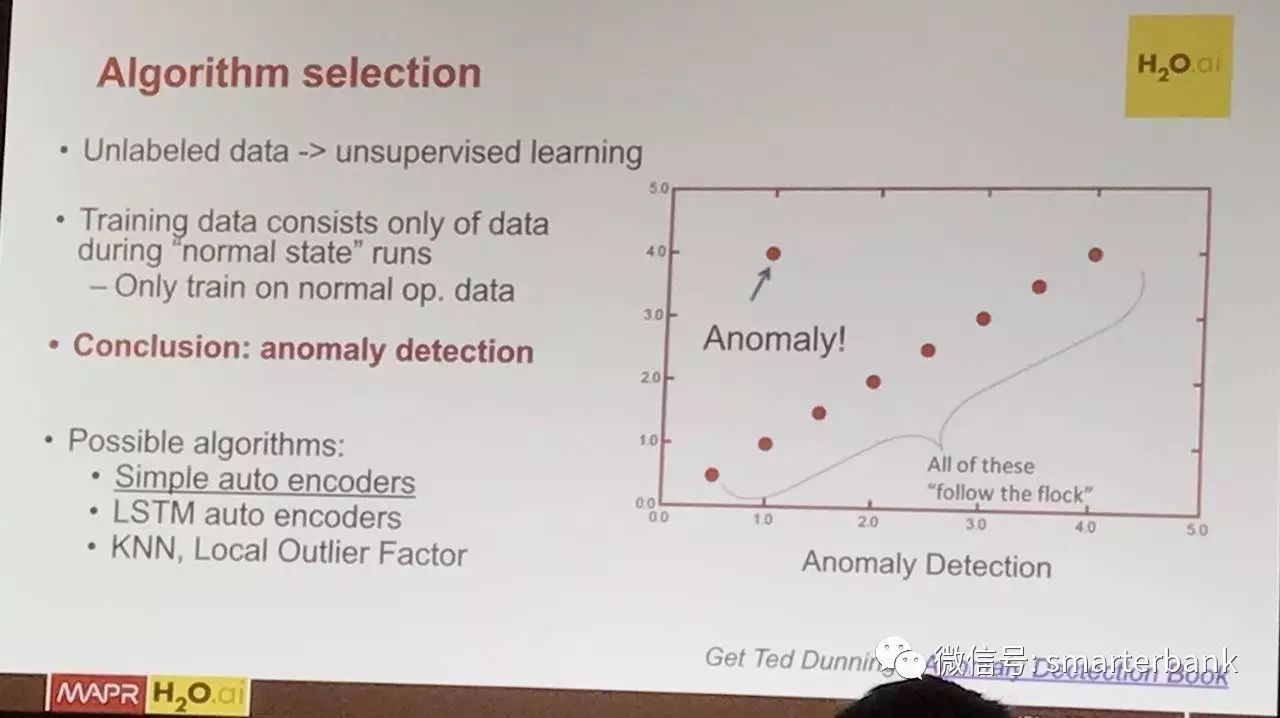
这是一个Anomaly Detection的主题,原来想听的主题水平较差,就中途过来听了会这个。异常检测或者是孤立点挖掘和我原来论文的方向一致,不过我那是纯粹折腾算法。这个主要用于机器人故障检查,提供软硬一体的解决方案。硬件进行信号的实时采集,传统实时数据库的意思,算法自然是深度学习了。人工智能,一个特点就是更多的数据加上更复杂的算法。
这是Intel在金融交易欺诈检测领域的一个例子,很显然仅仅是一个POC。基本上这就是目前厂商在金融领域应用人工智能的现状了,有很强的软硬件,但根本没有靠谱的场景。坏样本不够多,所以我们在项目中会尝试用无监督、半监督的方式去做。如果坏样本够多,那么GBDT的效果可能比CNN更好。我向以前怼过的厂商致歉,人工智能在银行能否有效应用,其实主要还是要靠甲方。
Oreilly的精美书签,可以召唤神龙了。
以上是关于时间序列预测与优秀数据科学工程师的主要内容,如果未能解决你的问题,请参考以下文章