时间序列: 炙手可热的RNN: LSTM
Posted 擎创夏洛克AIOps
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时间序列: 炙手可热的RNN: LSTM相关的知识,希望对你有一定的参考价值。
上一讲说到RNN.
RNN可说是目前处理时间序列的大杀器。相比于传统的时间序列算法,使用起来更方便,不需要太多的前提假设,也不需太多的参数调节,更重要的是有学习能力,因此是一种'智能'算法。前面也说到, 不只时间序列,在很多领域,特别是涉及序列数据的,RNN的表现总是那么的'抢眼'。不过,在这抢眼的过程中, 冲锋最前面的可不是简单的RNN(或者说最原始的RNN), 真正把RNN这个牌子''做大做强''的是: 长短时记忆循环神经网络(Long-Short Term Memory RNN, LSTM).
RNN的问题
传统的(或称原始的)RNN理论上是可以记忆任意长度的时间序列,比如你把一本<红楼梦>给她, 理论上她也是可以记忆的. 但, 理论和实际是有差距滴~.
在应用过程中,发现RNN对长时记忆的能力比较弱, 也就是RNN的记性不太好,对于长时间的东西她就有点记不清了,而几乎只会关注最近一段时间的信息。也就是说, 当你给她<红楼梦>之后,梦想着她如何给你讲讲''大观园''的趣事, 她却不知所云地来了句' 说到辛酸处,荒唐愈可悲.由来同一梦,休笑世人痴.' —— 前面的完全忘光了! 为什么?辛辛苦苦地训练她,可她竟这样地不念旧情?! 请不要怪她, 她的''内在逻辑'',上她无法控制的.这个所谓的'内在逻辑'就是指数函数(Exponential function).
恐怖的指数函数
指数函数大家应该都记得:
这就是指数函数,是不是其貌不扬? 是不是纯天然无公害? 你错了, 它展现的实力可是爆炸性的(explosive).
大家听过'棋盘放米'的故事吧: 第一格放1粒米(注意是一粒可不是一斤哦~),第二格放 2 粒米,第三个格放 4 粒米,…, 最后国王付不起了... 对于8x8的棋盘(国际象棋), 一共要放(264
不够直观? 好,再举个例子: 拿一张A4纸,对折,对折,再对折,…尝试一下,你能折几次? 世界记录只有13次! what?! 这么少?! 对的,这就是指数的威力。

梯度消失 *
上面是较通俗的说法, 其实从这个问题的名字就可看出,其切入点是梯度(gradient).


不只在RNN中,其实梯度消失及梯度爆炸在深度学习领域一直是一个比较头疼的问题,这也是深度网络难以训练的主要原因.只不过在深度网络中,是因为层数的增多导致产生类似指数形式的连续乘积。
解决方案
出现梯度消失(主要)与爆炸问题后,有很多解决方法提出来。比如设计更好的初始化权重,限制权重范围等等. 这种''通用''的方法的作用有限.
在RNN中有人提出设计隐藏单元用来储存信息,称为储层计算(Reservoir Computing),比如回声状态网络(Echo State Network, ESN).也有人提出在不同的时间粒度上处理数据,不同的时间处理单元称为渗透单元(Leaky Unit).但目前效果最好的,通用性最高的还是门限(Gated) RNN.其中最火的就是LSTM(Long-Short Term Memory)及GRU(Gated Recurrent Unit).
LSTM
设计初衷
首先,抛开恐怖的指数函数不谈,咱们先想象一个场景:假设你很喜欢古龙的小说,他的小说你都看了好多遍.现在给一篇他的小说,比如<七种武器>里的<霸王枪>, 篇幅不长,故事也不太复杂,让你阅读。
几个小时后,或者大方点,第二天,我来找你,让你一字不落地背出第一章<落日照大旗>. 你一定会问我我是不是凯丁蜜(Are you kidding me?),然后我会说我是斯尔瑞尔斯(I'm serious.). 最后你会承认你背不出. 但我要问你:谁是丁喜?百里长青与丁喜是什么关系?这本小说讲了一个什么故事?你一定滔滔不绝.
背不出一章内容,但却能说出整本小说的故事梗概, 是因为我们会提取主要信息, 不会对信息'一视同仁',懂得取舍.有些信息比如环境描写看看就过去了,一般不会刻意去记忆.但有些重要线索,比如谁杀了谁等等这样的信息我们会记住.
回过头来再看RNN,继续忽略恐怖的指数函数,直观的理解一下: RNN读取的信息,对信息一视同仁:经过处理的信息,RNN认为这些信息的任何一部分都对接下来的信息有影响,全部都抛给接下来处理的程序.对这些信息,RNN进行同样的处理.,造成大量无用信息冗余,浪费大量记忆空间,导致关键信息无法突出,更多的信息又无法存储.从而产生较前面的信息RNN记不住的问题.这才是''本质原因". 神马指数函数只是'刽子手'而已.
其他方法都只是从表象处理问题(针对梯度消失,或指数函数的连续乘法),或者虽针对本质原因但方法不对头. 而门限RNN正是针对信息的重要性设计的.
LSTM 原理
考虑重要性,那就自然而然的产生两种时态信息. 一种就是长时态(Long term state)信息. 此信息包含'趋势'信息或'主旨'信息,是剔除冗余信息后,对未来信息真正产生作用的信息.比如小说中的主旨大意,新闻要点等等.另一种短时态信息(Short term state). 此类信息是最直接地,对未来信息产生影响的信息. 比如'今天真热啊, 我得吹吹(空调)', ''吹吹'直接导致'空调''或'风扇'的产生,而不是可乐,'凉水澡'等等.
相比传统RNN的'一视同仁', 两种时态信息的区分,致使长时态信息不会被短时信息所淹没.
解决方案
出现梯度消失(主要)与爆炸问题后,有很多解决方法提出来,比如设计更好的初始化权重,限制权重范围等等. 这种''通用''的方法的作用有限. 在RNN中有人提出设计隐藏单元用来储存信息,称为储层计算(Reservoir Computing),比如回声状态网络(Echo State Network, ESN).也有人提出在不同的时间粒度上处理数据,不同的时间处理单元称为渗透单元(Leaky Unit).但目前效果最好的,通用性最高的还是门限(Gated) RNN.其中最火的就是LSTM(Long-Short Term Memory)及GRU(Gated Recurrent Unit).
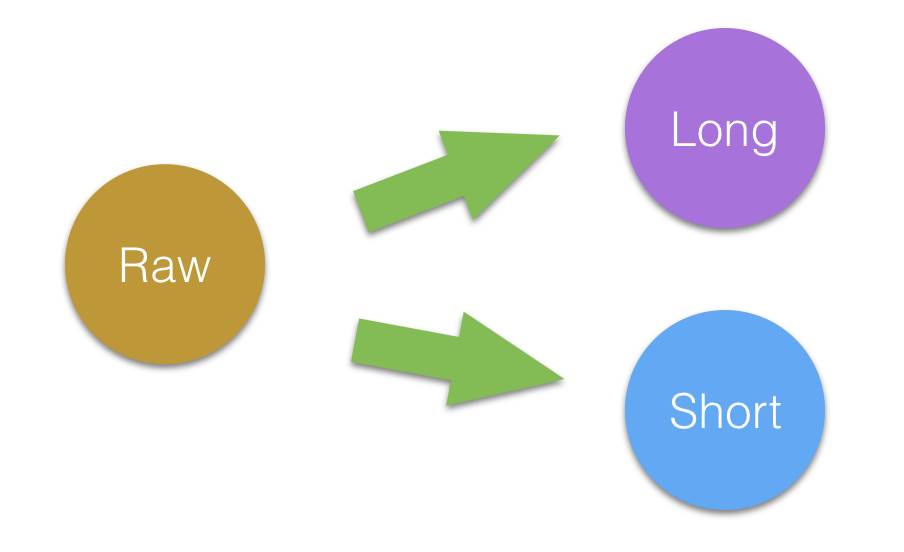
图1: 信息分态
对于两种时态信息, LSTM是如何提取重要信息的呢? 顾名思义,通过门(gate)来'提取'的.
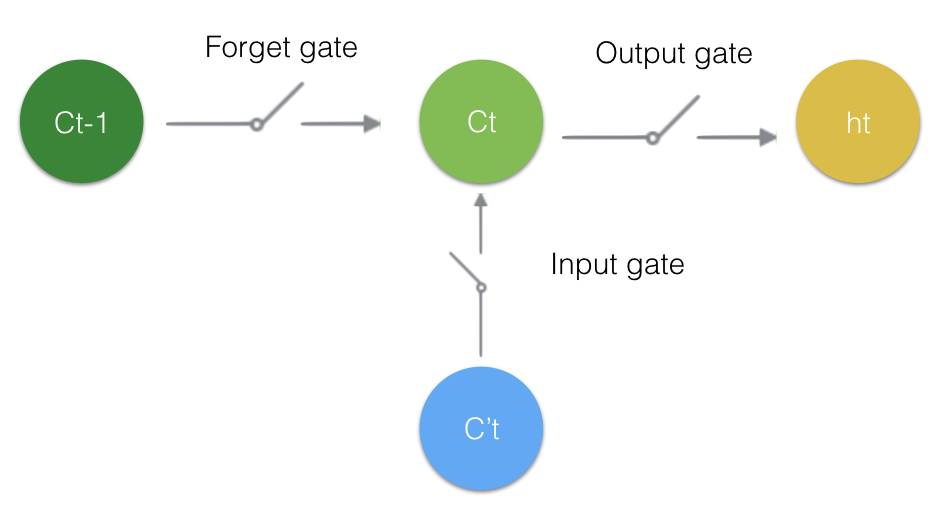
图2:信息流门限控制

门限控制


至此.LSTM单元就构建完成了.
LSTM 的 BPTT
对模型训练,要更新的参数即为权重(与偏置),其中权重的设置有四处,三个门与输入的端.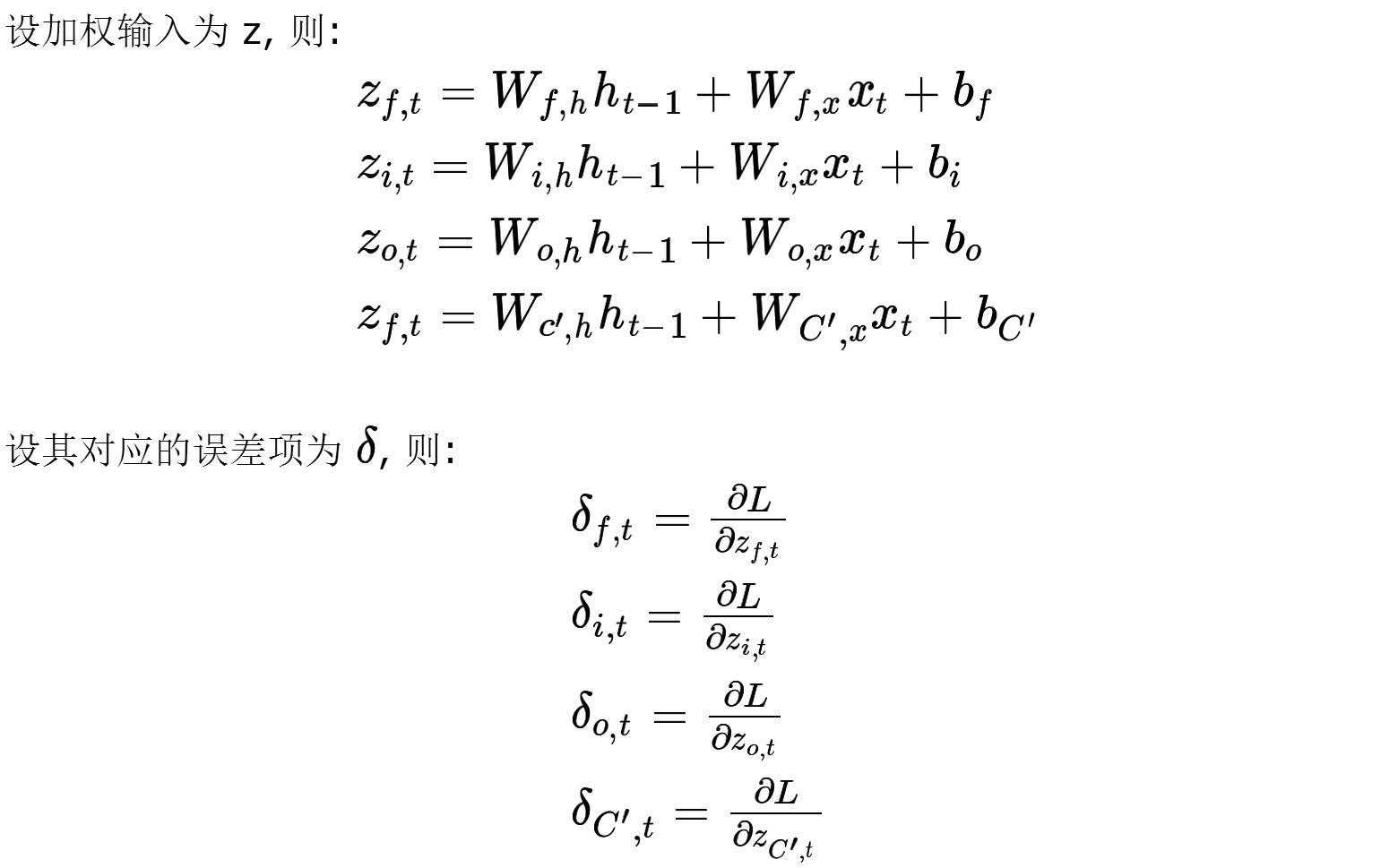
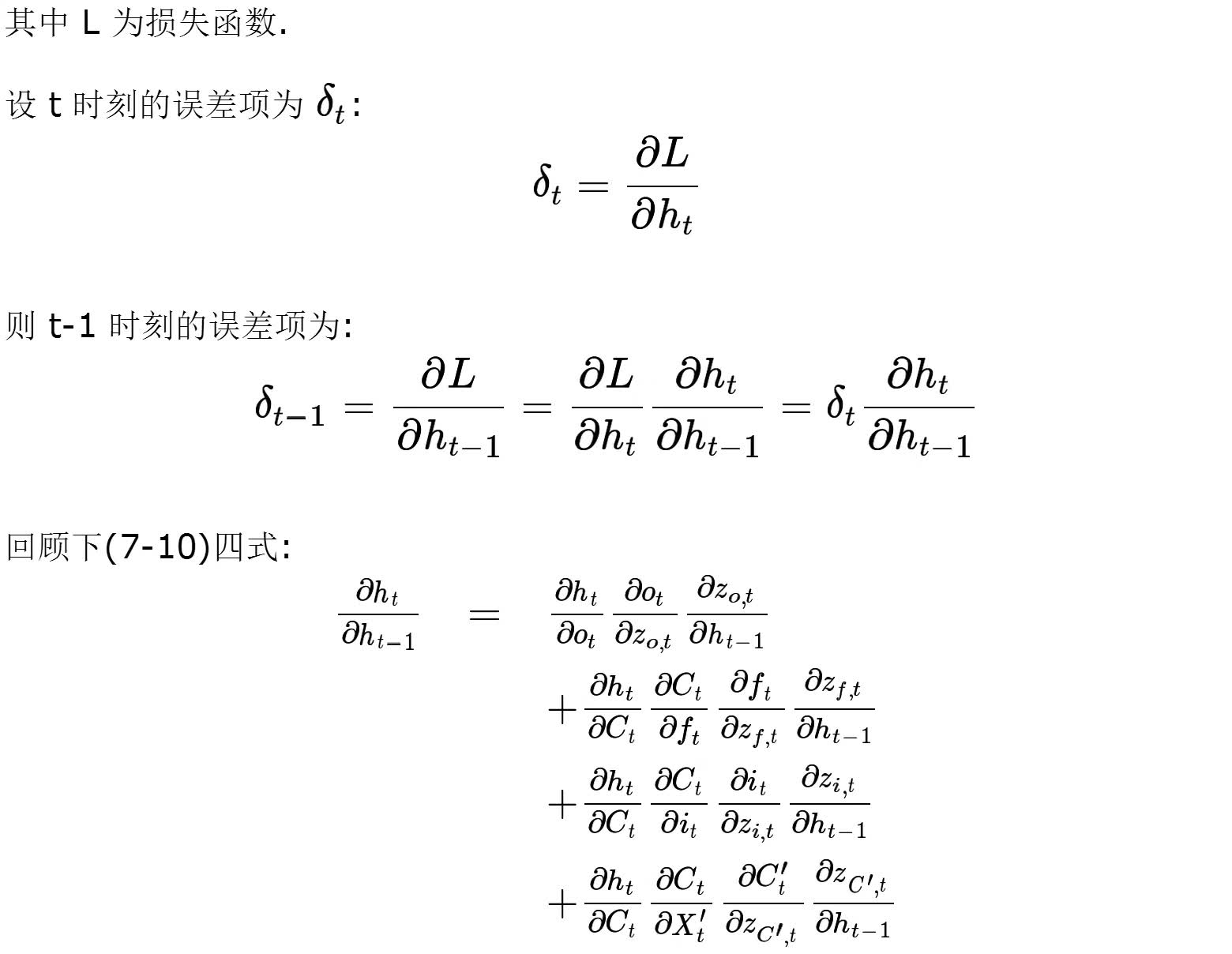


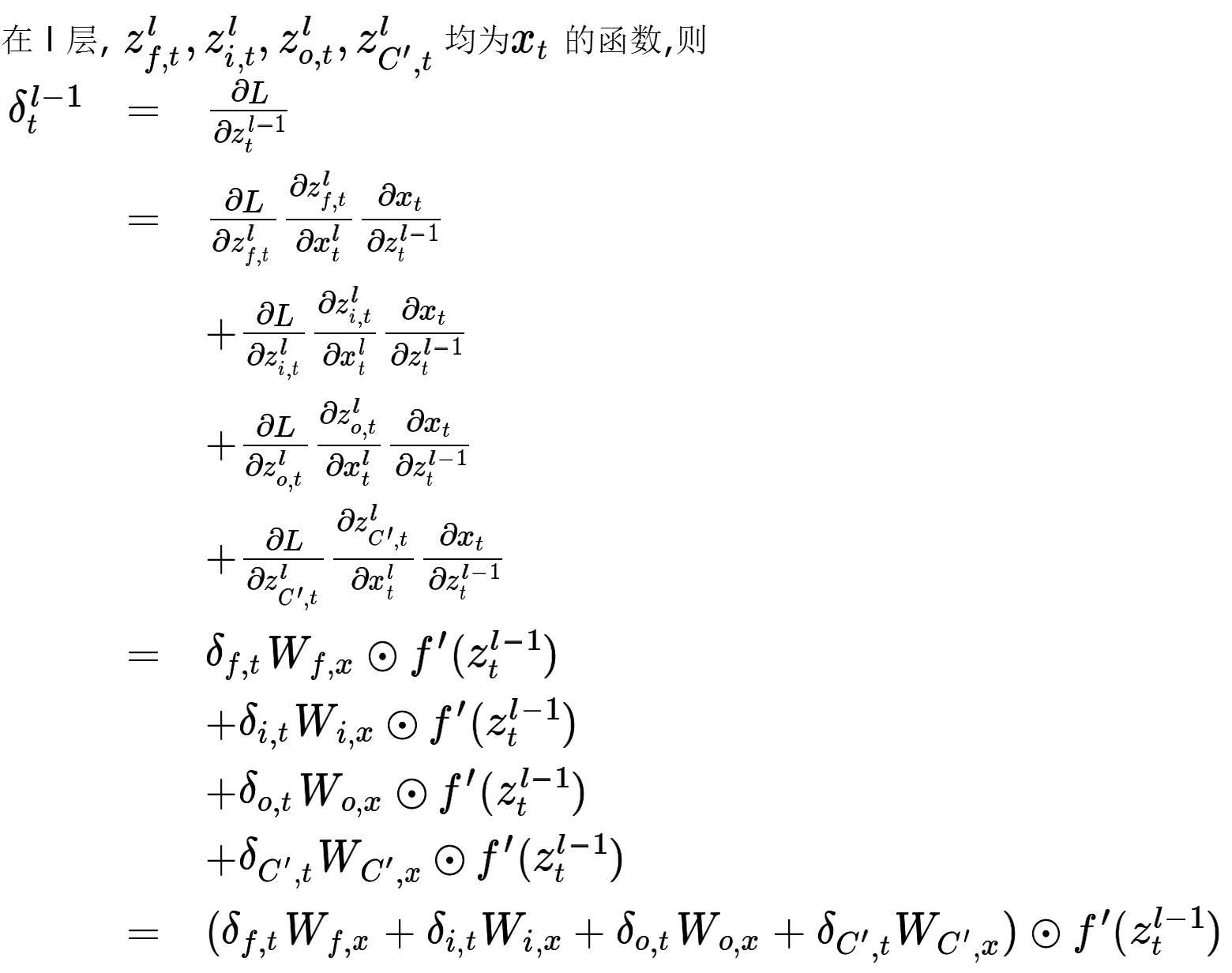

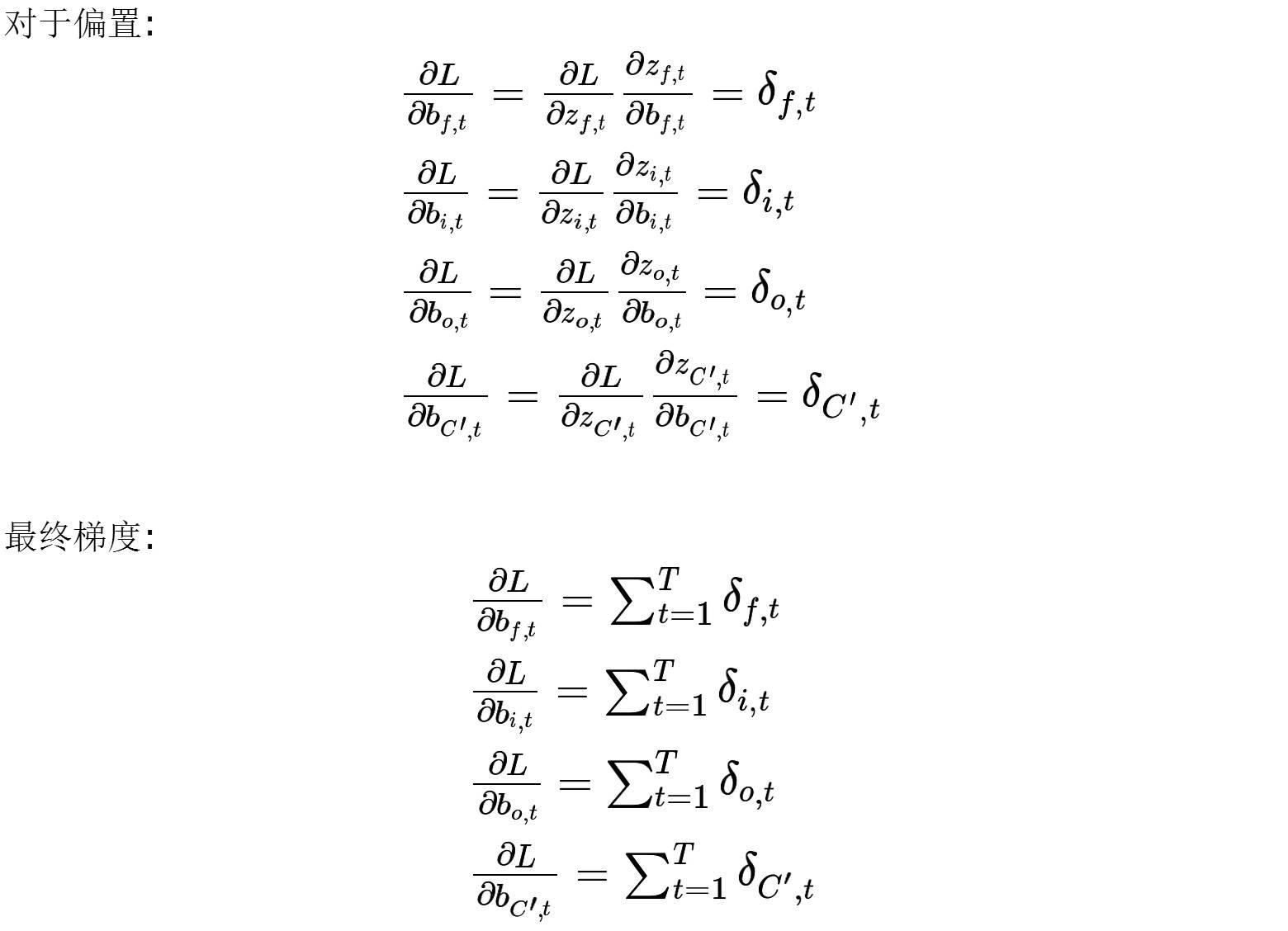
以上就是 LSTM 的 BPTT, 似乎很多公式,但其实四种模式都是一样的,怕大家混淆就都写上了,只不过这样看着会很多的样子.
参考文献:
1: Deep Learning, 2016, Ian Goodfellow, Yoshua Bengio, Aaron Courville.
2: Neural Networks and Deep Learning, 2016, Michael Nielsen.
3: Understanding LSTM, 2015, Colah's blog.
4: A Critical Review of Recurrent Neural Networks for Sequence Learning, 2015, Zachary C. Lipton et al.
5: 零基础入门深度学习(6)- 长短时记忆网络(LSTM) 2017, hanbingtao.
分类: Deep Learning,Machine Learning,Time Series
标签: LSTM, rnn, deep learning, 时间序列, time series
夏洛克 ITOA
Make Data Think
人工智能 | 机器学习 | IT运维
以上是关于时间序列: 炙手可热的RNN: LSTM的主要内容,如果未能解决你的问题,请参考以下文章