如何在时间序列预测中使用LSTM网络中的时间步长
Posted 深度搜索
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在时间序列预测中使用LSTM网络中的时间步长相关的知识,希望对你有一定的参考价值。
注:本文由深度搜索机器人利用深度学习和知识图谱等技术, 从海量信息中自动发现并生成。
来源:AI100
编辑:深度搜索(ID:deep_search)
Keras中的长短期记忆(LSTM)网络支持时间步长。
这就引出这样一个问题:单变量时间序列的滞后观察是否可以用作LSTM的时间步长,这样做是否能改进预测性能。
在本教程中,我们将研究Python 中滞后观察作为LSTM模型时间步长的用法。
在学完此教程后,你将懂得:
如何开发出测试工具,系统地评测时间序列预测问题中的LSTM时间步长。
将不同数量的滞后观察作为LSTM模型输入时间步长使用所产生的影响。
使用不同数量的滞后观察和为LSTM模型匹配神经元数所产生的影响。
让我们开始吧。
利用LSTM网络进行时间序列预测时如何使用时间步长
照片由 YoTuT拍摄并保留部分权利
教程概览
本教程分为4部分。它们分别为:
洗发水销量数据集
试验测试工具
时间步长试验
时间步长和神经元试验
环境
本教程假设您已安装 PythonSciPy 环境。您在学习本示例时可使用Python 2 或 3。
本教程假设您已使用TensorFlow或 Theano后端安装Keras(2.0或更高版本)。
本教程还假设您已安装scikit-learn、Pandas、 NumPy 和Matplotlib。
如果您在安装Python环境时需要帮助,请查看这篇文章:
如何使用Anaconda安装机器学习和深度学习所需的 Python 环境
http://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
洗发水销量数据集
该数据集描述某洗发水在3年内的月度销量。
数据单位为销售量,共有36个观察值。原始数据集由Makridakis、Wheelwright和Hyndman(1998)提供。
您可通过此链接下载和进一步了解该数据集:https://datamarket.com/data/set/22r0/sales-of-shampoo-over-a-three-year-period。
下方示例代码加载并生成已加载数据集的视图。
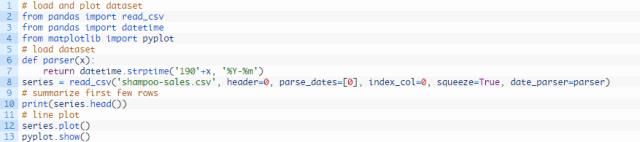
运行该示例,以Pandas序列的形式加载数据集,并打印出头5行。

然后就可生成显示明显增长趋势的序列线图。
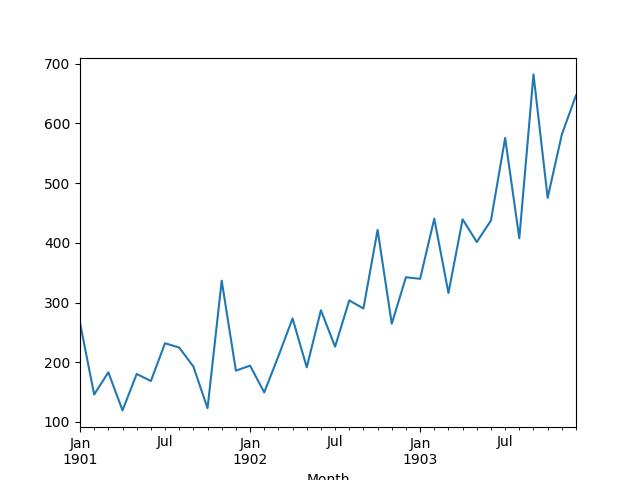 洗发水销量数据集线图
洗发水销量数据集线图
接下来,我们来看看本试验中使用的LSTM配置和测试工具。
试验测试工具
此部分描述本教程使用的测试工具。
数据划分
我们将把洗发水销量数据集分为两个集合:一个训练集和一个测试集。
前两年的销售数据将作为训练数据集,最后一年的数据将作为测试集。
我们将使用训练数据集创建模型,然后对测试数据集进行预测。
对测试数据集的持续性(persistence)预测(天真预测)的误差为136.761(单位:洗发水月度销量)。这种预测方法为测试工具提供了一个较低的性能合格界限。
模型评测
我们将使用滚动预测的方式,也称为步进式模型验证。
以每次一个的形式运行测试数据集的每个时间步长。使用模型对时间步长作出预测,然后收集测试组生成的实际预期值,模型将利用这些预期值预测下一时间步长。
这模拟了现实生活中的场景,新的洗发水销量观察值会在月底公布,然后被用于预测下月的销量。
训练数据集和测试数据集的结构将对此进行模拟。
最后,收集所有测试数据集的预测,计算误差值总结该模型的预测能力。采用均方根误差(RMSE)的原因是这种计算方式能够降低粗大误差对结果的影响,所得分数的单位和预测数据的单位相同,即洗发水月度销量。
数据准备
在用数据集拟合LSTM模型前,我们必须对数据进行转化。
在匹配模型和进行预测之前须对数据集进行以下三种数据转化。
转化序列数据使其呈静态。具体来说,就是使用 lag=1差分移除数据中的增长趋势。
将时间序列问题转化为监督学习问题。具体来说,就是将数据组为输入和输出模式,上一时间步长的观察值可作为输入用于预测当前时间步长的观察值。
转化观察值使其处在特定区间。具体来说,就是将数据缩放带 -1 至1的区间内,以满足LSTM模型默认的双曲正切激活函数。
在进行计算和得出误差分数之前,对预测值进行这些转化的逆转化使它们恢复至原来的区间内。
LSTM模型
我们将使用一个有状态的LSTM模型,其中神经元个数为1,epoch数为500。
须将批大小设置为1,因为我们将应用步进式验证法,对最后 12 个月的各月数据进行一步预测。
批大小为 1 意味着要使用在线训练(而不是批训练或 mini-batch 训练)的方法拟合模型。因此,模型拟合预计将会产生一些偏差。
理论上,需要使用更多的训练epoch(例如 1000 或 1500),但是为了使运行次数处在合理区间,我们将epoch数减至500。
我们将使用高效的ADAM优化算法和均方误差损失函数拟合这个模型。
试验运行
每种试验方案将进行10次试验。
这样做的原因是LSTM网络的初始条件随机生成,得出的结果会大不相同,每进行一次试验,给定配置都会受到训练。
让我们开始进行试验吧。
时间步长试验
我们将进行5次试验,每次试验都将使用一个不同数量的滞后观察作为从1至5的时间步长。
当使用有状态的LSTM时,时间步长为1的表示将为默认表示。时间步长为2至5的用法为人为设定。这样做的目的是希望滞后观察额外的上下文可以改进预测模型的性能。
在训练模型之前,将单变量时间序列转化为监督学习问题。时间步长的数目规定用于预测下一时间步长(y)的输入变量(X)的数目。因此,对于表达中使用的每一个时间步长,必须从数据集的开始部分移除很多数据行。这是因为并没有什么先前观察,来作为数据集第一个数据的时间步长。
测试时间步长为1的完整代码编写如下所示。
每个试验中时间步长1至5 的run()函数的时间步长参数都各不相同。另外,每次试验结束时须将试验结果保存在文件中,并且进行另一不同试验时必须更改该文件的名称;例如:experiment_timesteps_1.csv, experiment_timesteps_2.csv,etc.
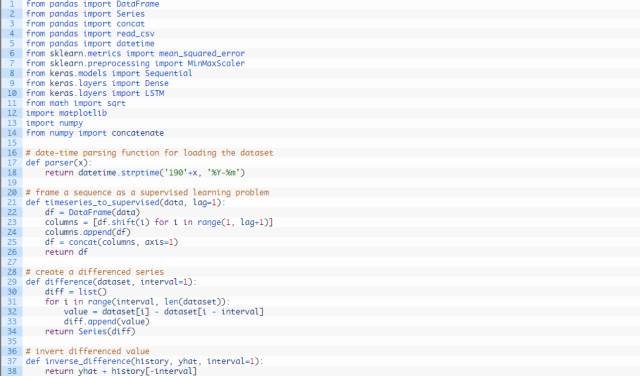

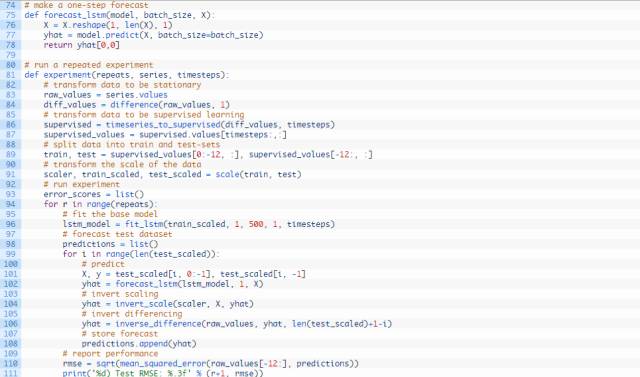
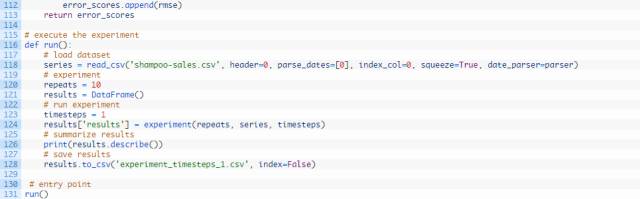
运行5个不同的试验,各试验的时间步长数量不同。
如果你有足够的记忆和中央处理器(CPU)资源,可并行运行这5个试验。这些试验对图形处理器(GPU)并无要求,几分钟到几十分钟即可完成。
在运行完这些试验时,你应该有5个保存有结果的文件,如下所示:

我们可以编写代码载入并总结这些结果。
特别地,检查每个试验的描述性统计并使用箱须图比较各试验的结果对得出结论很有帮助。
总结这些结果的代码如下所示。
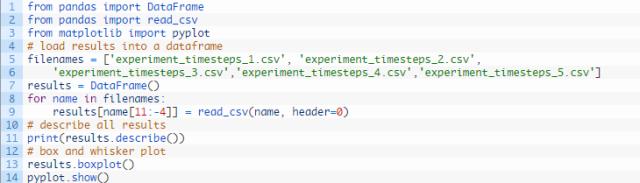
运行代码,首先打印每组结果的描述性统计。
从平均性能的角度看,我们可以得出:使用一个时间步长得出的性能最好。当观察对比测试均方根误差中值时,我们也得出相同结论。

另外还生成了比较结果分布的箱须图。
该图和描述性统计所表明的结论相一致。随着时间步长的数量增加,图中出现测试均方根误差增加的总体趋势。
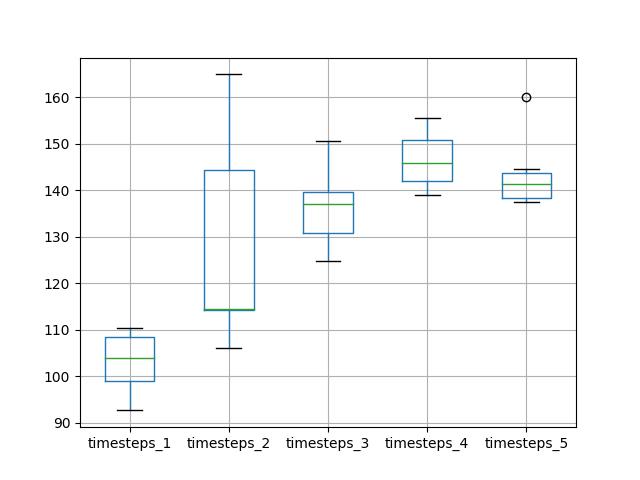
时间步长对比均方根误差的箱须图
我们并没有像预期的那样,看到性能随着时间步长的增加而增强,至少在使用这些数据集和LSTM配置的试验中没看到。
这就引出这样一个问题,网络的学习能力是否是一个限制因素。我们将在下一部分探讨这一点。
时间步长和神经元试验
LSTM网络神经元(又称为模块)的数量定义网络的学习能力。
之前的试验中仅使用了一个神经元,这可能限制了网络的学习能力,以致于滞后观察作为时间步长的使用不够有效。
我们可以重复上文试验,并通过增加时间步长来增加LSTM中神经元的数量,观察性能是否会因此而得到提升。
我们可以通过改变试验函数的这一行来实现这步,将:

改为

另外,我们可以在保存结果的文件的名称后加上一个“_neurons”后缀,从而将这些结果与第一个试验中得出的结果区分开来,例如,将:

改为
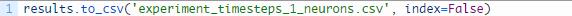
应用这些更改,重复上文中的5个试验。
在运行完这些试验后,你应创建有5个结果文件。

和之前的试验一样,我们可以载入结果、计算描述性统计并创建箱须图。完整的代码编写如下所示。
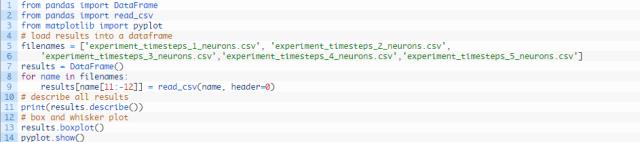
运行代码,首先打印各试验(共5个)的描述性统计。
这些结果和使用单神经元LSTM的第一组试验所表明的结论相一致当神经元数量和时间步长数量设置为1时,测试均方根误差的均值似乎最小。
生成箱须图,比较这些结果的分布。
随着神经元数量和时间步长数量的增加,变动幅度和中值性能几乎呈现出线性增长的趋势。
线性增长趋势可能表明:网络学习能力虽然有增强,但是并没有获得充分的时间来拟合数据。也许还需要增加epoch的数量。
时间步长对比均方根误差的箱须图
延 伸
本部分列举来你可能会考虑探索并进一步研究的几个方向。
滞后作为特征。滞后观察作为时间步长使用还引出另一问题:滞后观察能否用作输入特征。KerasLSTM 应用内部处理时间步长和特征的方式是否相同,这一点尚不清楚。
诊断运行线图。观察同一给定试验不同运行中训练和测试均方根误差随epoch数变化的线图,可能很有帮助。这样做可能会有助于判断出模式是否过度拟合或者欠拟合,转而,我们可以制定方法进行处理。
增加训练epoch。在第二组试验中, LSTM中神经元数量的增加可能受益于训练epoch的增加。这可通过一些后续试验进行探索。
增加重复次数。重复试验10次得出的测试均方根误差结果数据群相对较小。将重复次数增至30或100次可能或得出更加可靠的结果。
总 结
在本教程中,你学习了如何研究在LSTM网络中将滞后观察作为输入时间步长使用。
具体而言,你学习了:
如何开发强大的测试工具,应用于LSTM输入表示试验。
LSTM时间序列预测问题中如何将滞后观察作为输入时间步长的使用。
如何通过增加时间步长来增加网络的学习能力。
你发现与预期不同的是,滞后观察作为输入时间步长使用并没有降低选定问题和LSTM配置的测试均方根误差。
End.
文章由深度搜索推荐引擎,根据用户喜好自动生成,并不代表本网赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请在30日内与本网联系,我们将在第一时间删除内容![声明]本站文章版权归原作者所有内容为作者个人观点本站只提供参考并不构成任何投资及应用建议。本站拥有对此声明的最终解释权。
以上是关于如何在时间序列预测中使用LSTM网络中的时间步长的主要内容,如果未能解决你的问题,请参考以下文章