用 LSTM 做时间序列预测的一个小例子
Posted 人工智能LeadAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 LSTM 做时间序列预测的一个小例子相关的知识,希望对你有一定的参考价值。
正文共3867个字,3张图,预计阅读时间10分钟。
问题:航班乘客预测
数据:1949 到 1960 一共 12 年,每年 12 个月的数据,一共 144 个数据,单位是 1000
目标:预测国际航班未来 1 个月的乘客数
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
%matplotlib inline
导入数据:
# load the dataset
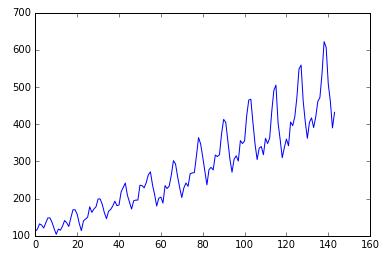
dataframe = read_csv('international-airline-passengers.csv', usecols=[1], engine='python', skipfooter=3) dataset = dataframe.values# 将整型变为floatdataset = dataset.astype('float32') plt.plot(dataset) plt.show()
从这 12 年的数据可以看到上升的趋势,每一年内的 12 个月里又有周期性季节性的规律。
需要把数据做一下转化:
将一列变成两列,第一列是 t 月的乘客数,第二列是 t+1 列的乘客数。
look_back 就是预测下一步所需要的 time steps:
timesteps 就是 LSTM 认为每个输入数据与前多少个陆续输入的数据有联系。例如具有这样用段序列数据 “…ABCDBCEDF…”,当 timesteps 为 3 时,在模型预测中如果输入数据为“D”,那么之前接收的数据如果为“B”和“C”则此时的预测输出为 B 的概率更大,之前接收的数据如果为“C”和“E”,则此时的预测输出为 F 的概率更大。
# X is the number of passengers at a given time (t) and Y is the number of passengers at the next time (t + 1). # convert an array of values into a dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return numpy.array(dataX), numpy.array(dataY) # fix random seed for reproducibility numpy.random.seed(7)
当激活函数为 sigmoid 或者 tanh 时,要把数据正则话,此时 LSTM 比较敏感。
设定 67% 是训练数据,余下的是测试数据。
# normalize the datasetscaler = MinMaxScaler(feature_range=(0, 1)) dataset = scaler.fit_transform(dataset)# split into train and test setstrain_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
X=t and Y=t+1 时的数据,并且此时的维度为 [samples, features]
# use this function to prepare the train and test datasets for modeling
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
投入到 LSTM 的 X 需要有这样的结构: [samples, time steps, features],所以做一下变换:
# reshape input to be [samples, time steps, features]trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1])) testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
建立 LSTM 模型:
输入层有 1 个input,隐藏层有 4 个神经元,输出层就是预测一个值,激活函数用 sigmoid,迭代 100 次,batch size 为 1
# create and fit the LSTM networkmodel = Sequential() model.add(LSTM(4, input_shape=(1, look_back))) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(trainX, trainY, epochs=100, batch_size=1,verbose=2)
Epoch 100/100
1s - loss: 0.0020
预测:
# make predictionstrainPredict = model.predict(trainX) testPredict = model.predict(testX)
计算误差之前要先把预测数据转换成同一单位
# invert predictionstrainPredict = scaler.inverse_transform(trainPredict) trainY = scaler.inverse_transform([trainY]) testPredict = scaler.inverse_transform(testPredict) testY = scaler.inverse_transform([testY])
计算 mean squared error
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
Train Score: 22.92 RMSE
Test Score: 47.53 RMSE
画出结果:蓝色为原数据,绿色为训练集的预测值,红色为测试集的预测值
# shift train predictions for plottingtrainPredictPlot = numpy.empty_like(dataset) trainPredictPlot[:, :] = numpy.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict# shift test predictions for plottingtestPredictPlot = numpy.empty_like(dataset) testPredictPlot[:, :] = numpy.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict# plot baseline and predictionsplt.plot(scaler.inverse_transform(dataset)) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show()
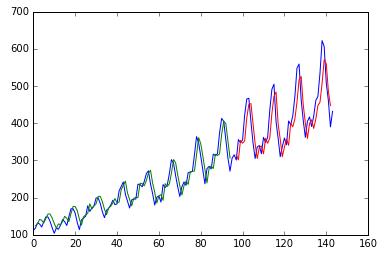
上面的结果并不是最佳的,只是举一个例子来看 LSTM 是如何做时间序列的预测的。
可以改进的地方,最直接的 隐藏层的神经元个数是不是变为 128 更好呢,隐藏层数是不是可以变成 2 或者更多呢,time steps 如果变成 3 会不会好一点。
另外感兴趣的筒子可以想想,RNN 做时间序列的预测到底好不好呢

http://machinelearningmastery.com/time-series-prediction-lstm-recurrent-neural-networks-python-keras/
推荐阅读 历史技术博文链接汇总
http://www.jianshu.com/p/28f02bb59fe5
也许可以找到你想要的
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org

大家都在看

点击“阅读原文”直接打开报名链接
以上是关于用 LSTM 做时间序列预测的一个小例子的主要内容,如果未能解决你的问题,请参考以下文章
在 LSTM 中包含分类特征和序列以进行序列预测的最佳实践?