R语言时间序列之ARMAARIMA模型
Posted 英国学习委员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言时间序列之ARMAARIMA模型相关的知识,希望对你有一定的参考价值。
基本理论知识
ARMA模型称为自回归移动平均模型,是时间序列里常用的模型之一。ARMA模型是对不含季节变动的平稳序列进行建模。它将序列值表示为过去值和过去扰动项的加权和。模型形式如下:
yt=c+a1yt−1+a2yt−2+...+apyt−p+ϵt−b1ϵt−1−b2ϵt−2−...−bqϵt−q
其中
yt
ϕ(l)yt=c+Θ(l)ϵt
其中
ϕ(l)=1−a1l−a2l2−...−aplp
称为自回归系数多项式。
Θ(l)=1−b1l−b2l2−...−bqlq
称为移动平均系数多项式。
ARIMA模型的本质和ARMA是一样的,将ARMA模型里的序列值
yt
Δyt=c+a1Δyt−1+a2Δyt−2+...+apΔyt−p+ϵt−b1ϵt−1−b2ϵt−2−...−bqϵt−q
自相关系数acf刻画的是
yt
偏自相关系数pacf刻画的是去除
yt−1
平稳性:均值为常数,且两个变量间的协方差只取决于它们之间的时间间隔而不取决于时间点。即
E(yt)=μ
Cov(yt,ys)=E((yt−μt)(ys−μs))=γ|s−t|
白噪声:所有随机变量的均值为0,方差不变为常数,且彼此之间不想管的序列即为白噪声序列。一般假设模型的残差为白噪声。即
E(ϵt)=0
Var(ϵt)=σ2
对于所有s≠t,Cov(ϵt,ϵt)=0
建模
建模流程图
1、画出时序图和自相关图
画出序列的时序图,观察序列是否平稳。利用acf()函数画出序列的自相关图,通过自相关图判断序列是否平稳。若自相关图里的自相关系数很快的衰减为0,则序列平稳,否则为非平稳。对于非平稳序列需要将其转化为平稳序列,才可用ARMA进行建模。以R自带的时间序列Nile(尼罗河的流量)为例。
> plot(Nile,type="l")> plot(Nile,type="l",xlab="时间",ylab="尼罗河流量")> acf(Nile,main="自相关图") #画出自相关图
> opar<-par(mfrow=c(2,1))> plot(Nile,type="l",xlab="时间",ylab="尼罗河流量")> acf(Nile,main="自相关图")> par(opar)
1
2
3
4
5
6
7
结果如下: 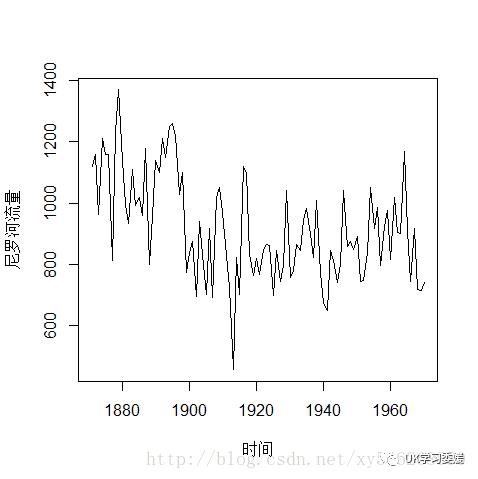
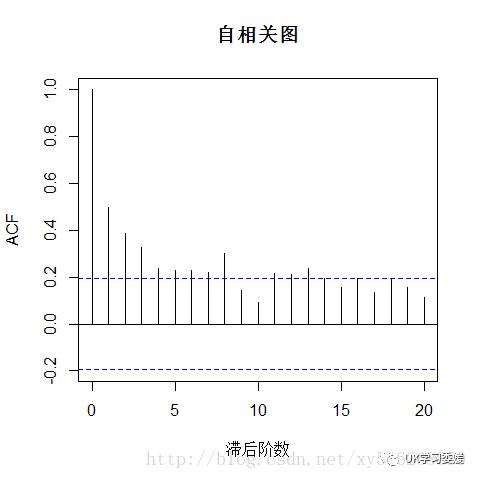
从时序图可以看到序列再1990年有一个下降的趋势,并且自相关图里自相关系数没有快速的减为0(一般认为自相关系数低于2倍标准差即图中蓝色虚线一下时即为0),而是呈现出拖尾的特征,故判断序列为非平稳序列。
2、对序列进行平稳化处理
若序列为非平稳,则需将序列通过差分转化为平稳序列。差分可以消除序列的线性趋势。ndiffs()函数可以帮助我们判断需要进行几次差分。将序列取对数可以保证ARMA模型同方差的假设。代码如下:
> opar<-par(mfrow=c(2,1))> plot(data,type="l",xlab="时间",ylab="尼罗河流量对数值",main="差分前")> acf(data,main="自相关图",xlab="滞后阶数")> par(opar)> library(forecast)> ndiffs(data)[1] 1 #结果表明序列需要进行1阶差分
> ndata<-diff(data,1)> ndiffs(ndata)[1] 0 #结果表明无需进行
> opar<-par(mfrow=c(2,1))> plot(ndata,type="l",main="差分后")> acf(ndata,main="自相关图",xlab="滞后阶数")> par(opar)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
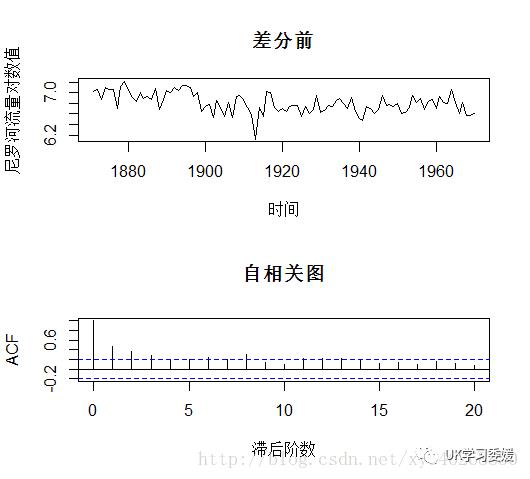
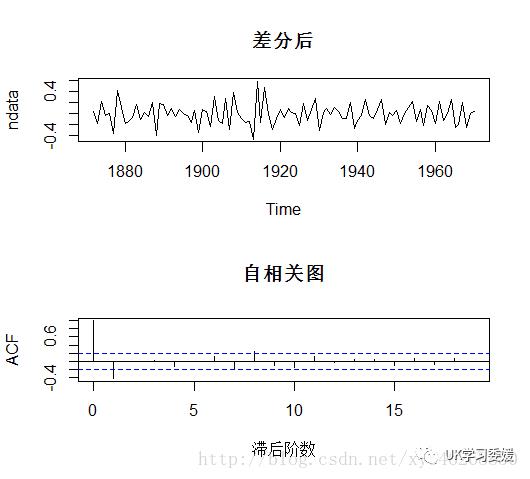
从上图可以看到,1阶差分以后序列变为平稳序列,且自相关图显示自相关系数在滞后1阶后就快速的减为0。进一步表明序列平稳。
3、ARMA模型的定阶及参数估计
| acf值 | pacf值 | 模型 |
|---|---|---|
| 拖尾(逐渐减为0) | P阶截尾(p阶快速减为0) | ARIMA(p,d,0) |
| q阶截尾 | 拖尾 | ARIMA(0,d,q) |
| 拖尾 | 拖尾 | ARIMA(p,d,q) |
如上表所示,我们可以通过acf和pacf图来判断模型的阶数。还可以通过模型的AIC和BIC值来选取模型,AIC和BIC的介绍见前面的基本理论知识。R里面的auto.arima()函数就是通过选取AIC和BIC最小来选取模型的。
R可以通过arima()函数估计模型参数,调用格式为:
arima(data,order=c(p,d,q),method=,…)
| 参数 | 含义 |
|---|---|
| data | 时间序列 |
| order | 模型的阶数 |
| method | 模型参数估计的方法,“ML”极大似然估计,”CSS”条件最小二乘估计,“CSS-ML” |
> opar<-par(mfrow=c(2,1))
> acf(ndata)
> pacf(ndata)
> par(opar)
> model1<-arima(data,order=c(0,1,1),method="ML") > model1Call:arima(x = data, order = c(0, 1, 1), method = "ML")Coefficients:
ma1
-0.7677s.e. 0.1046sigma^2 estimated as 0.02623: log likelihood = 39.3, aic = -74.6
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
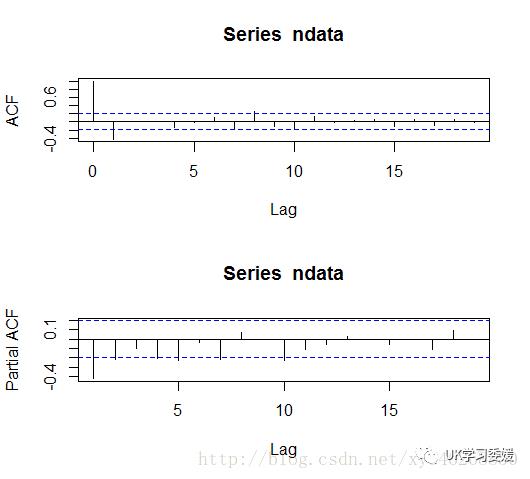
通过上面的acf和pacf图,我们可以选取建立ARIMA(0,1,1)模型。最后估计出来的模型为
yt=yt−1+ϵt−0.7677ϵt−1
4、模型检验
模型参数检验包括两个检验:参数的显著性检验和残差的正态性和无关性检验。
参数的显著性检验:用估计出的系数除以其的标准差(se)得到的商与T统计量5%的临界值(1.96)比较,商的绝对值大于1.96,则拒绝原假设,认为系数显著的不为0,否则认为系数不显著。系数不显著的可以去掉,语法为arima(data,order,fixed=c(NA,0,NA…)),fixed为0的位置即为被去掉的参数的位置。
残差的正态性检验:画出残差的QQ图即可判断,QQ图中残差基本完全落在45°线上即为符合正态性假设。否则模型可能出现错误。语法为:
qqnorm(model$residuals)
qqline(model$residuals)
残差的无关性检验:也称为残差的白噪声检验,由前面白噪声的定义可知,残差(=估计值-真实值)应为不相关的序列。常用LB统计量来检验残差。
Q=n(n+2)∑(ρ/(n−k))
服从自由度为K-p-q的卡方分布,其中n为样本容量。语法为:
Box.test(model$residuals,type=”Ljung-Box”)
> qqnorm(model1$residuals)> qqline(model1$residuals)> Box.test(model1$residuals,type="Ljung-Box")
Box-Ljung testdata: model1$residualsX-squared = 1.5897, df = 1, p-value = 0.2074
1
2
3
4
5
6
7
8
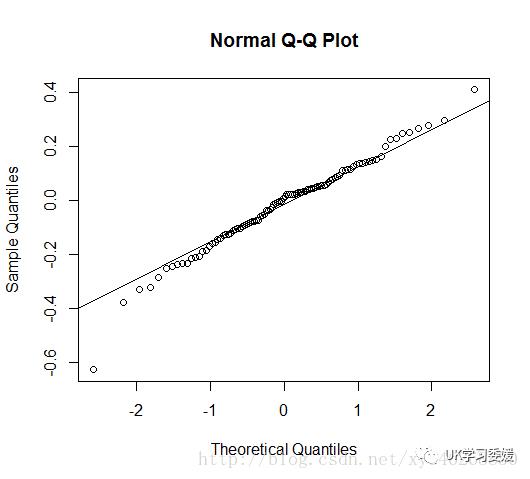
从 画出的QQ图和LB检验的结果来看,残差符合正态性假设且不相关,则认为模型拟合数据比较充分,可以用来进行下一步预测。
5、预测
> p<-predict(model1,4)
> p
$predTime Series:
Start = 1971 End = 1974 Frequency = 1 [1] 6.686726 6.686726 6.686726 6.686726$seTime Series:
Start = 1971 End = 1974 Frequency = 1 [1] 0.1619621 0.1662765 0.1704817 0.1745857> plot(Nile,xlab="时间",ylab="流量")
> lines(exp(p$pred),col="red")
> exp(p$pred)Time Series:
Start = 1971 End = 1974 Frequency = 1 [1] 801.6934 801.6934 801.6934 801.6934
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
从预测结果可以看到 ,预测的后四年的值均为801.69。时间序列在做预测时经常会出现这个问题。如果数据能够多一点,做出来的模型可能预测效果会好一点。时间序列模型只适合短时期的预测,不适合长时期的。而且我个人认为时间序列的模型在加入外生变量方面不是很方便,没有回归做起来方便(这一点是在参加天池的比赛时体会到的),这也是时间序列模型应用的一个缺点。所以在时间序列模型的基础上再结合回归,不知道结果会不会更好一点。希望以后能有更多的机会实践,也希望有丰富实践经验的前辈们不吝赐教!
获取最新的留学咨询,最全面的英国课程信息,最贴心的论文辅导。
委媛2010年公派留学到英国攻读博士学位,做过TA,RA。 帮导师批改本科生和研究生的作业。8年论文辅导经验,为您的留学生活保驾护航。
以上是关于R语言时间序列之ARMAARIMA模型的主要内容,如果未能解决你的问题,请参考以下文章