基于时间序列数据的监控实践
Posted 云技术实践
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于时间序列数据的监控实践相关的知识,希望对你有一定的参考价值。
SRE监控理念区别于传统监控的一个特点就是新一代基于时间序列存储的监控。本文通过概念解析以及举例国内外的SRE监控实践,进一步加深大家的理解。
一、什么是 SRE ?
SRE是Site ReliabilityEngineer的简称,它是源起于国外互联网企业的一个词语或者新定义的一个职业。在传统的系统管理员模式时代这个角色我们叫运维,国外称做Operation。
Google SRE的VP叫Ben Treynor,2003年的时候他加入公司第一个任务就是组建一个7人的“生产运维小组”。但很快他发现根据Google机器增加的速度,按照传统的运维模式是无法快速满足运维需求的。由于他自己本身就是一个资深的软件开发人员,他就按照组建一个研发团队一样来组建这个运维团队。招收了许多研发工程师,这些工程师具有开发能力,又了解一些系统管理的知识,最主要的是他们鄙视重复劳动。他们把一些最佳实践、方式、流程、方法都固化成代码,用这种方式去应对规模性的扩张,去应对复杂度的上升。
DevOps现在是国内外都非常热的一个概念,很多人狭窄地理解为DevOps就是让研发部门去做运维的事,或者运维部门做研发的事情。但实际上DevOps的思想更多是要把整个开发流程的界限打通,产品深入到研发的内部,研发可以把信息快速反馈给产品,开发和运维或者QA和运维之间的界限也需要打通,形成“开发团队与运营团队之间更具协作性、更高效的关系”。
Google将运维的角色职能扩展为SRE,也就是用软件工程师的方法和手段,来解决运维的难题。从名字就不难看出SRE更多地将目光投向了整个系统运行的稳定性上。实际上SRE试图平衡服务不可用以及产品快速创新、提高运维效率之间的风险,因此SRE是要保证用户满意度,平衡各方面因素,包括功能、服务以及性能。可以说SRE就是DevOps的思想在开发和运维之间的一个平衡。
这是前Google SRE, 《SRE:Google运维解密》译者孙宇聪将SRE工作职责归纳总结的一个图,孙宇聪老师现在也是数人云的技术顾问。我们可以看到SRE的工作分成了三大类。第一类是运维部门最基本也最重要的工作—应急响应。因为随着企业业务现规模的不断扩大,IT跟运营的结合越来越紧密,IT部门很多时候需要处理的事情和业务运营有关。比如双十一这种特殊事件节点的监控和应急响应就和业务息息相关,这一点应该非常好理解。基于应急响应之上是日常运维,其实就是保证系统能够正常更新、快速迭代。更高一级的工作内容就是输出一些工程研发,实现运维自动化,可编排化和可编程化。
可以看出应急响应无论对传统运维部门还是SRE人员来说都是最基本和最重要的工作,而监控处于整个生产环境需求金字塔模型的最底层,SRE依靠监控数据来对服务的情况作出理性判断,用科学的方法应对紧急的情况。下面我将为大家介绍一下SRE在监控方面的一些理念和实践。
二、什么是时间序列存储
监控系统经过10年的发展,从传统的探针模型与图形化趋势展示的模型已经演变为一个新的模型,即基于时间序列信息的监控模型。SRE监控理念区别于传统监控的一个特点就是新一代基于时间序列存储的监控。
首先,我先介绍一下什么是时间序列存储。
时间序列存储最简单的定义就是数据格式里包含timestamp字段的数据。比如股票市场的价格,环境中的温度,主机的CPU使用率等。时间序列数据在查询时,对于时间序列总是会带上一个时间范围去过滤数据。同时查询的结果里也总是会包含timestamp字段。
监控数据大量呈现为时间序列数据特征,所以,为了应对复杂的监控数据格式,在每一份数据中加上时间字段,让时间序列存储的场景一下子打开了。
区别于传统的关系型数据库,时间序列数据的存储、查询和展现进行了专门的优化,从而获得极高的数据压缩能力、极优的查询性能,特别契合需要处理海量时间序列数据的物联网应用场景。在工业制造、物流、能源、环境、水务等领域有着巨大的需求。
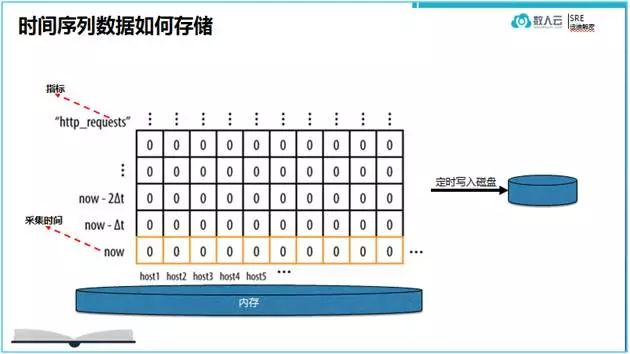
时间序列数据的难点是实时数据量庞大,写入速度需要特别快。谷歌的监控组件Borgmon在内存中设计了一个基于内存的数据库,这个数据库存储设计的每一个数据点包含一对键值(timestamp, value),并且数据点按照时间轴一次排列形成一维列表,通过加入以name=value 汇聚的标签来排列组合,把时间序列数据变为多维数据表结构如上图。在实践中,数据会被存在一个固定大小的Borgmon内存中,通过定期的垃圾收集机制清除过时的时间序列数据。
注意,内存中的数据大小正好被有意设计为可以实时查询的时间区间。对于谷歌数据中心来说,其时间区间是12小时,需要17GB 大小的内存来存储数据点为24字节,每间隔1分钟收集,总存储量位一百万个数据点。Borgmon定期的把内存中过期的数据清除出来并存到时间数据库(TSDB)中。Borgmon是支持查询TSDB 数据库的。
三、国外基于时间序列存储监控的实践
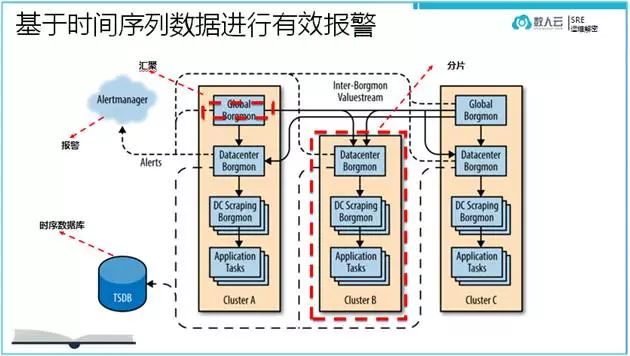
谷歌的监控体系如上图所示。注意Scraping进程是用来分片应用的日志数据处理量的。毕竟当监控的指标增多之后,把实时数据流全部指向Borgmon 进程会加重Borgmon进程的处理负载。
谷歌Borgmon 收集回来的数据,是定义了一套报警规则来过滤时间序列数据的。其简洁的语法就是label=value 的数列组合完成。设计的非常巧妙。规则如下:
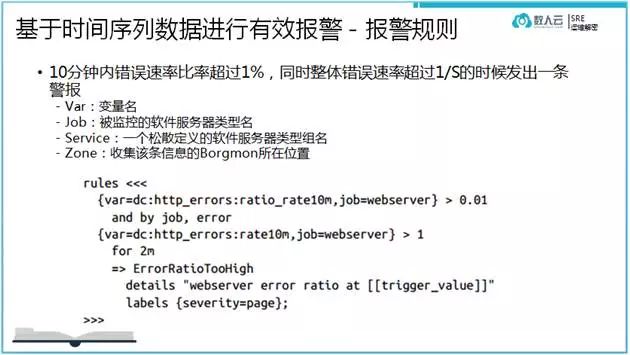
监控报警的条件随着业务的条件会越来越复杂,只有这种数列语法的规则才能快速定义出各种各样的监控图例和报警策略。
四、国内基于时间序列存储的监控实践
数人云在构建自己的监控报警工具的时候,就参考了谷歌的监控基础设施设计思想,通过技术选型我们研发团队把目光放在了以Prometheus这个开源监控项目之上构建自己的监控报警系统。
通过熟悉和实践,我们基本构建出了和谷歌Borgmon 类似的监控报警体系。值得注意的事情就是,以上在介绍谷歌的Borgmon 监控体系的时候,感觉架构非常容易理解,应该实现并不困难。但是等我们上线自己的监控报警系统的时候,发现其实内功在底层。
首先,Prometheus 本身的高可用方案还没有靠谱的实现。我们自己通过Consul 的health check 和dns 设计的方案仅仅是standby方式,如何实现多活的应用架构才可以说是完美。我们研发小伙伴的诉求是无止境的。
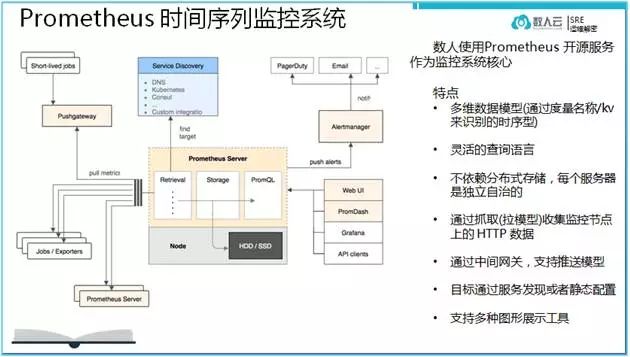
最终,通过不断的优化,我们终于实现成如下监控架构。在研发的过程中,发现绘图组件Grafana 已经成为开源领域最强大的工具,并且没有之一之说。Prometheus 项目最终把自己的绘图方案直接舍弃对接了Grafana 方案,足以说明它的威力。数人研发团队在使用Grafana 的过程中也深刻体会到了这个项目的强大,正在慢慢消化其中的技术实现。
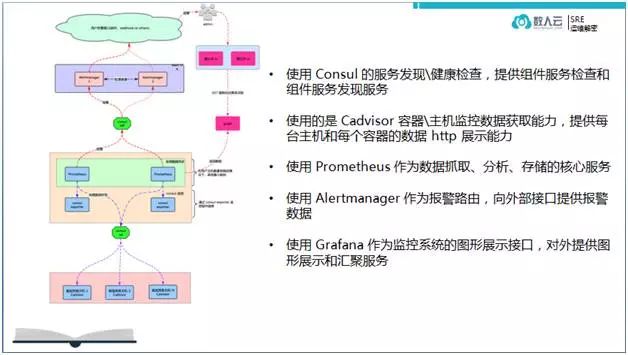
最终,我们梳理并建立了清晰简洁的监控报警控制面板来全局管理数人云PaaS平台的集群应用监控工作。下图为首页谍照。
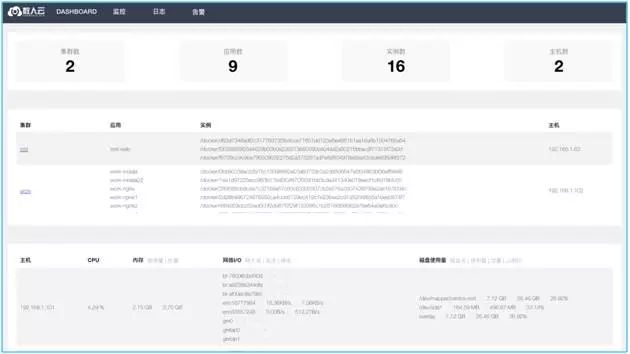
还有更细节的实时监控绘图界面,如下:
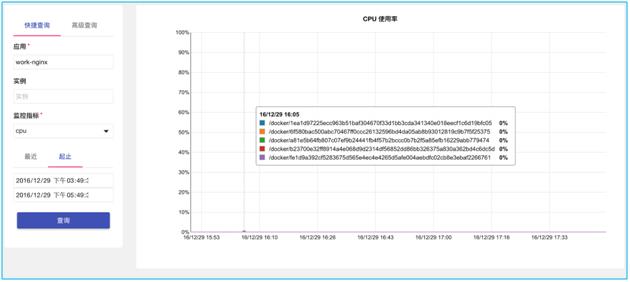
可以实时查询任一应用的容器实例的监控指标,大家看到这里容器ID 是UUID,还无法一一解读。这里需要通过调度器才能给启动的容器定义一个人机能理解的实例名字。这块的设计我们放在了我们的开源调度器Swan 上。等这个监控体系接入Swan 之后,就可以用类如0.taskname.username.clustername.dcname这样的语法来指定查询任意一个容器实例了,并且这个名字是可以支持 DNS 查询的。

《运维前线》新书发布,十三位前线运维专家倾力奉献,现场送出30本。云技术社区、华章书院、优云联手倾力精彩奉献!现场另有云技术社区定制数据线、北极熊袋子等精美礼品!2017年首场专业运维会议,一线专家解密当前运维前线,扫码或者点击阅读原文立即报名!
 加入云技术社区技术交流微信群,联系北极熊微信:hadxiaer(加的时候请备注:姓名-城市-公司)
加入云技术社区技术交流微信群,联系北极熊微信:hadxiaer(加的时候请备注:姓名-城市-公司)





交流 分享 提升

以上是关于基于时间序列数据的监控实践的主要内容,如果未能解决你的问题,请参考以下文章