用于罕见事件时间序列预测的LSTM模型体系结构
Posted 蜂口知道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用于罕见事件时间序列预测的LSTM模型体系结构相关的知识,希望对你有一定的参考价值。
使用LSTM直接进行时间序列预测收效甚微。这是令人惊讶的,因为神经网络能够学习复杂的非线性关系,并且LSTM可能是能够直接支持多元序列预测问题的最成功的递归神经网络类型。
最近在Uber AI Labs进行的一项研究表明,LSTM的自动特征学习功能及其处理输入序列的能力在端到端模型中得到利用,该模型可用于驱动对公共假日等罕见事件的需求预测。
在本文中,您将发现一种为时间序列预测开发可扩展的端到端LSTM模型的方法。
阅读这篇文章后,你会知道:
· 跨多个站点进行多变量、多步骤预测的挑战。
· 用于时间序列预测的LSTM模型架构,包括单独的自动编码器和预测子模型。
· 所提出的LSTM架构在罕见事件中的技能需求预测以及在不相关的预测问题上重用训练模型的能力。
概述
在这篇文章中,我们将回顾由Nikolay Laptev等人撰写的题为“ Uber神经网络的时间序列极端事件预测 ”的论文,在ICML 2017的时间系列研讨会上发表。
这篇文章分为四个部分:
1. 动机
2. 数据集
3. 模型
4. 结果
1.动机
该工作的目标是为多步时间序列预测开发端到端预测模型,该模型可以处理多变量输入(例如,多输入时间序列)。该模型的目的是预测优步驾驶员对拼车的需求,特别是在传统模式不确定性很高的节假日等具有挑战性的日子里。通常,这种假期需求预测属于称为极端事件预测的研究领域。
极端事件预测已成为估计高峰用电需求、交通拥堵严重程度和高峰期定价等应用的热门话题。事实上,有一个称为极值理论(EVT)的统计分支直接处理这一挑战。
描述了两种现有方法:
· 经典预测方法:根据时间序列建立模型,可能适合需要。
· 两步法:经典模型与机器学习模型结合使用。
这些现有模型的难度激发了对单个端到端模型的需求。
此外,还需要一个可以跨区域推广的模型,特别是针对每个城市收集的数据。这这意味着对一些或所有城市进行培训,并提供可用数据的模型,用于对一些或所有城市进行预测。。我们可以将此概括为对支持多变量输入、进行多步骤预测和跨多个站点(在本例中是城市)进行概括的模型的一般需求。
2.数据集
该模型适用于Uber数据集,该数据集包括美国顶级城市五年的匿名拼车数据。
一项为期五年的美国主要城市(按人口计算)每日完成行程的历史数据,被用来提供美国所有主要节假日的预测。。每个预测的输入包括每个出行的信息,以及天气,城市和假日变量。为了避免缺乏数据,我们使用其他功能,包括天气信息(例如降水,风速,温度)和城市级信息(例如,当前行程,当前用户,当地假期)。
下面的图表提供了一个为期一年的六个变量的样本。
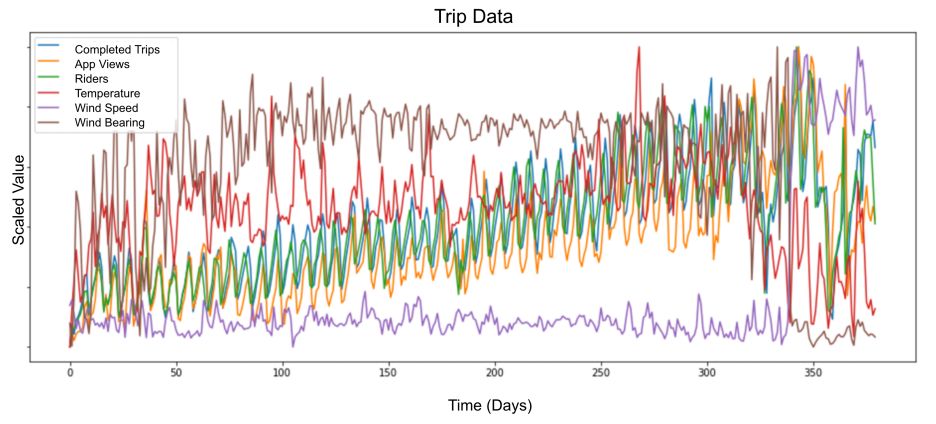
从“优步神经网络的时间序列极端事件预测” 模型得到的多元输入
通过将历史数据拆分为输入和输出变量的滑动窗口来创建训练数据集。
本文未指定实验中使用的回溯和预测范围的具体大小。
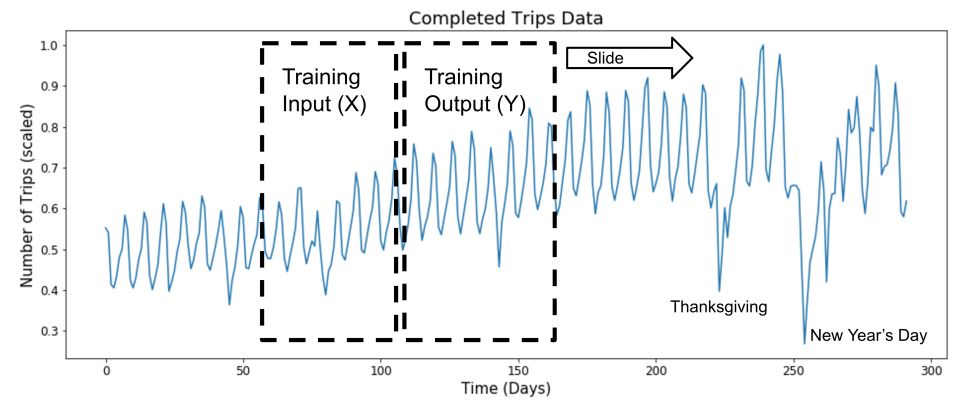
基于“优步神经网络的时间序列极端事件预测”时间序列建模的滑窗法
通过对每批样品的观察值进行标准化来缩放时间序列数据,并且每个输入序列都是去趋势的,而不是去标准化的。
神经网络对未缩放的数据很敏感,因此我们将每个小批量标准化。此外,我们发现降低数据的趋势会产生更好的结果。
3.模型
LSTM,例如Vanilla LSTMs,对该问题进行了评估,并表现出相对较差的表现。
这并不奇怪,因为它反映了其他地方的发现。
我们最初的LSTM实施相对于最先进的方法没有表现出优越的性能。
使用了更精细的架构,包括两个LSTM模型:
· 特征提取器:用于将输入序列提取到特征向量的模型,该特征向量可以用作进行预测的输入。
· 预测者:使用提取的要素和其他输入进行预测获得模型。
开发了LSTM自动编码器模型用作特征提取模型,并使用Stacked LSTM作为预测模型。
我们发现普通LSTM模型的性能比我们的基线差。因此,我们提出了一种新的架构,它利用自动编码器进行特征提取,与基线相比实现了卓越的性能。在进行预测时,首先将时间序列数据提供给自动编码器,自动编码器被压缩为平均和连接的多个特征向量。然后将特征向量作为输入提供给预测模型以进行预测。
该模型首先通过自动特征提取来建立网络,这对于在大规模的特殊事件中捕捉复杂的时间序列动态至关重要。然后通过集合技术(例如,平均或其他方法)聚合特征向量。然后将最终向量与新输入连接并送到LSTM预测器进行预测。
目前还不清楚在进行预测时,自动编码器究竟得到了什么,不过我们可以猜测,对于预测的城市来说,它是一个多变量时间序列,在预测的时间间隔之前进行观测。作为自动编码器输入的多变量时间序列将导致可以连接的多个编码向量(每个系列一个)。目前尚不清楚平均在这一点上可以采取什么角色,尽管我们可能猜测它是执行自动编码过程的多个模型的平均值。
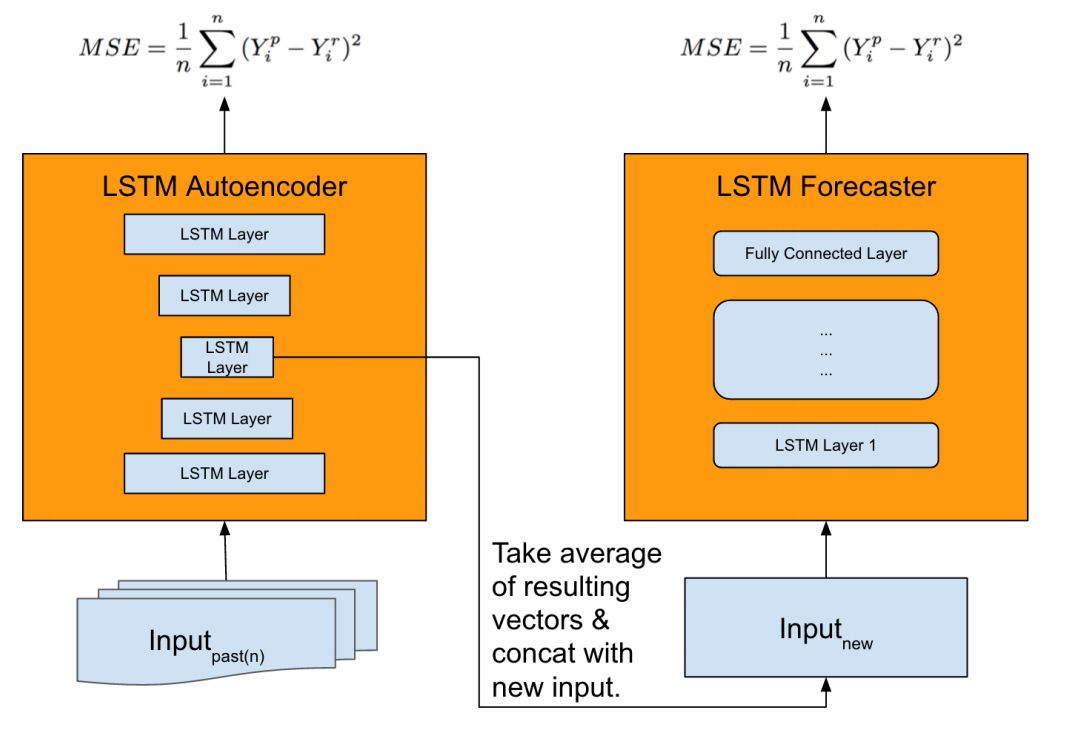
基于“优步神经网络的时间序列极端事件预测” 特征提取模型及预测模型综述
作者评论说,可以将自动编码器作为预测模型的一部分,并对其进行评估,但单独的模型可以提高性能。但是,拥有一个单独的自动编码器模块可以在我们的经验中产生更好的结果。在演示论文时使用的幻灯片中提供了开发模型的更多细节。
自动编码器的输入是512 LSTM单位,自动编码器中的瓶颈用于创建32或64 LSTM单位的编码特征向量。
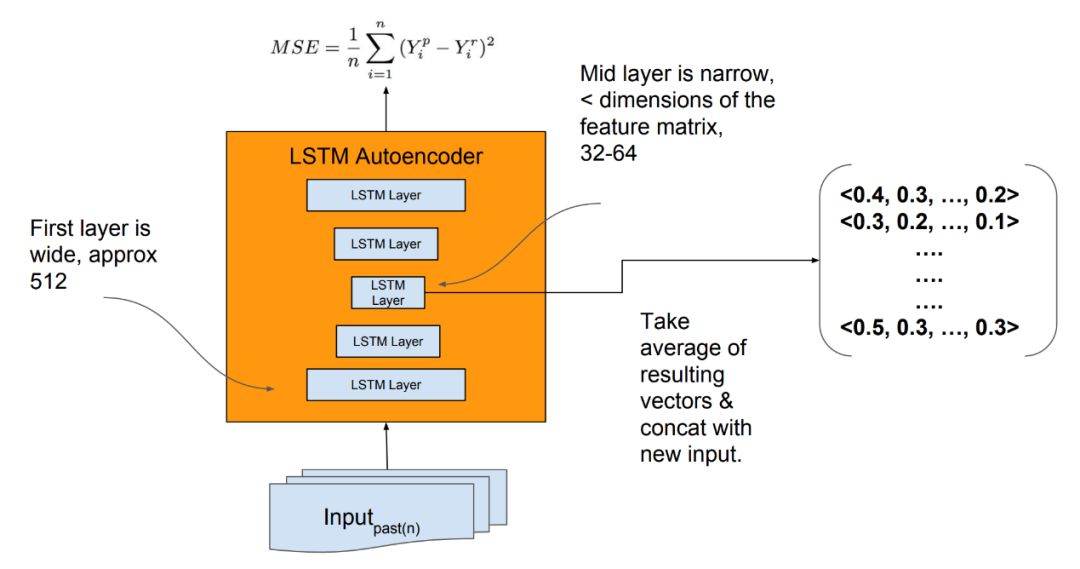
从优步神经网络的“时间序列极端事件预测”中获取特征提取的LSTM自动编码器的详细信息
使用“ 新输入 ”的形式 将编码的特征向量提供给预测模型,尽管未指定此新输入是什么; 我们可以猜测它是一个时间序列,也许是预测区间之前的观测预测的城市的多变量时间序列。或者,从本系列文章中提取的特征(尽管我对此持怀疑态度,因为这篇文章和幻灯片与此相悖)
该模型是根据大量数据进行训练的,这是堆叠LSTM或LSTM的一般要求。所描述的生产神经网络模型在数千个时间序列上进行训练,每个时间序列具有数千个数据点。在进行新的预测时,不会对该模型进行再训练。此外,本研究亦采用一种有趣的方法来估计预测的不确定性,就是自举。
分别采用自动编码器和预测模型对模型不确定度和预测不确定度进行估计。输入被提供给给定的模型并且活跃性消失(如幻灯片中所评论的)。该过程重复100次,模型和预测误差项用于预测不确定性的估计。
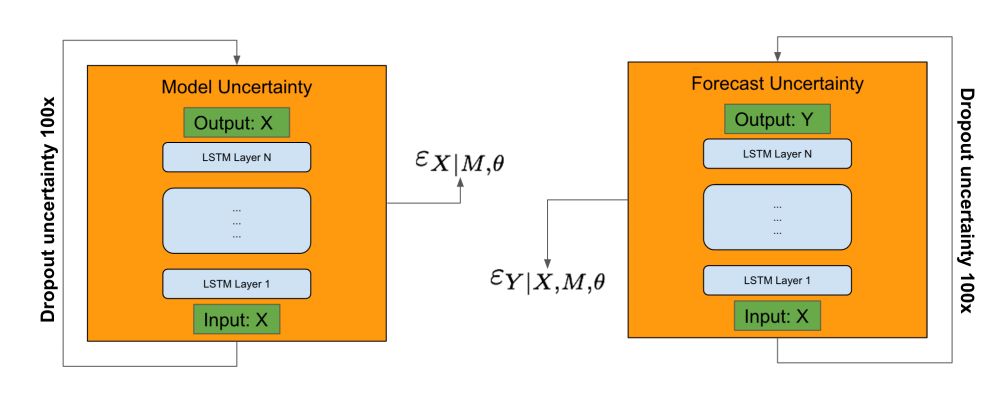
“优步神经网络时间序列极端事件预测” 预测不确定性评估综述
这种预测不确定性的方法可以在2017年的论文“ 优步时间序列的深度和自信预测 ”中得到更好的描述。
4.发现
对该模型进行了评估,特别关注美国城市对美国假期的需求预测。
没有具体说明模型评估的具体情况。新的广义LSTM预测模型被发现优于优步使用的现有模型,如果我们假设现有模型得到了很好的调整,这可能会令人印象深刻。
结果显示,与包含单变量时间序列和机器学习模型的当前专有方法相比,预测精度提高了2%-18%。
然后将在Uber数据集上训练的模型直接应用于M3-Competition数据集的子集,该数据集由大约1,500个月单变量时间序列预测数据集组成。
这是一种迁移学习,一种非常理想的目标,允许跨问题域重用深度学习模型。令人惊讶的是,该模型表现良好,与表现最佳的方法相比并不是很好,但比许多复杂模型更好。结果表明,可能通过微调(例如在其他转移学习案例研究中完成),该模型可以重复使用并且更加熟练。
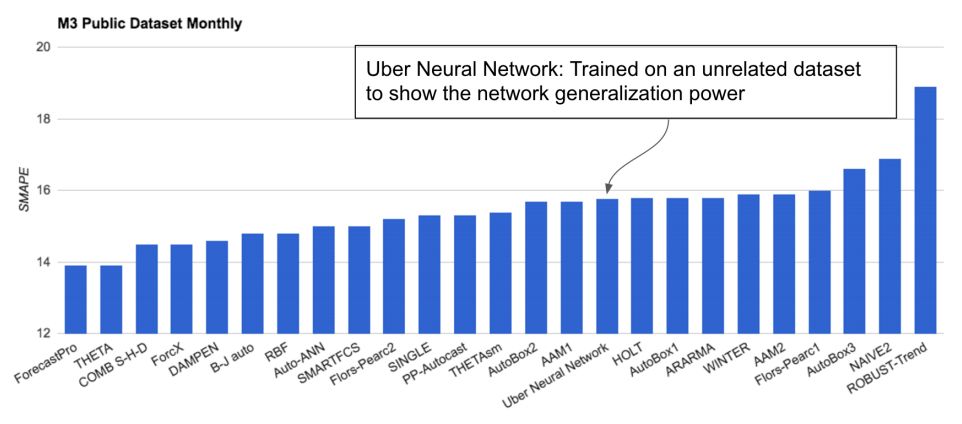
LSTM模型在优步数据上的表现以及对“优步神经网络的时间序列极端事件预测”中M3数据集的评估
重要的是,作者提出,深度LSTM模型对时间序列预测的最有益应用可能是:
· 有大量的时间序列。
· 每个系列都有大量的观察结果。
· 时间序列之间存在很强的相关性。
根据我们的经验,选择时间序列的神经网络模型有三个标准:(a)时间序列的数量(b)时间序列的长度(是正确c)时间序列之间的相关性。如果(a),(b)和(c)高,那么神经网络可能的选择,否则经典的时间序列方法可能效果最好。这一点可以用一张幻灯片很好地总结出来。
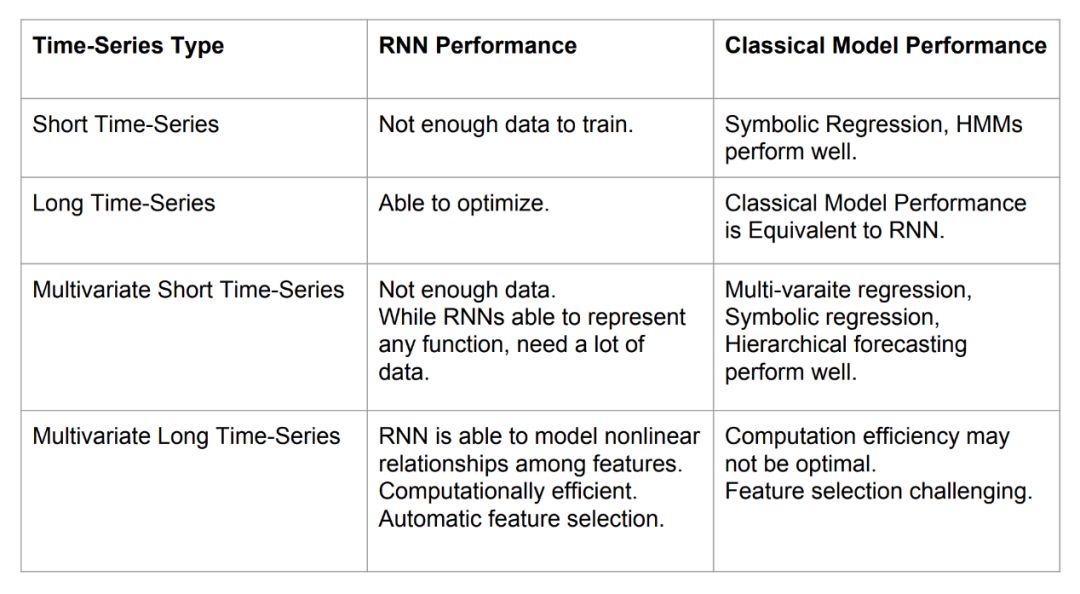
应用LSTM进行时间序列预测的经验教训来自“优步神经网络的时间序列极端事件预测”幻灯片

-END-
蜂口小程序全新改版上线啦,各种最新行业资讯免费看,欢迎扫描左下方二维码关注哦~
参与内测,免费获取蜂口所有内容,请扫描右下方二维码申请内测资格,更有其他优惠福利多多,欢迎大家多多参与,尽情挑刺,凡是好的建议,我们都会虚心采纳哒~
蜂口小程序将持续为你带来最新技术的落地方法,欢迎随时关注了解~
以上是关于用于罕见事件时间序列预测的LSTM模型体系结构的主要内容,如果未能解决你的问题,请参考以下文章