时间序列的表示与信息提取
Posted 数学人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时间序列的表示与信息提取相关的知识,希望对你有一定的参考价值。
文章链接:
https://zr9558.com/2018/03/07/timeseriesclustering/
提到时间序列,大家能够想到的就是一串按时间排序的数据,但是在这串数字背后有着它特殊的含义,那么如何进行时间序列的表示(Representation),如何进行时间序列的信息提取(Information Extraction)就成为了时间序列研究的关键问题。
就笔者的个人经验而言,其实时间序列的一些想法和文本挖掘是非常类似的。通常来说句子都是由各种各样的词语组成的,并且一般情况下都是“主谓宾”的句子结构。于是就有人希望把词语用一个数学上的向量描述出来,那么最经典的做法就是使用 one - hot 的编码格式。i.e. 也就是对字典里面的每一个词语进行编码,一个词语对应着一个唯一的数字,例如 0,1,2 这种形式。one hot 的编码格式是这行向量的长度是词典中词语的个数,只有一个值是1,其余的取值是0,也就是 (0,...,0,1,0,...,0) 这种样子。但是在一般情况下,词语的个数都是非常多的,如何使用一个维度较小的向量来表示一个词语就成为了一个关键的问题。几年前,GOOGLE 公司开源了 Word2vec 开源框架,把每一个词语用一串向量来进行描述,向量的长度可以自行调整,大约是100~1000 不等,就把原始的 one-hot 编码转换为了一个低维空间的向量。在这种情况下,机器学习的很多经典算法,包括分类,回归,聚类等都可以在文本上得到巨大的使用。Word2vec 是采用神经网络的思想来提取每个词语与周边词语的关系,从而把每个词语用一个低维向量来表示。在这里,时间序列的特征提取方法与 word2vec 略有不同,后面会一一展示这些技巧。






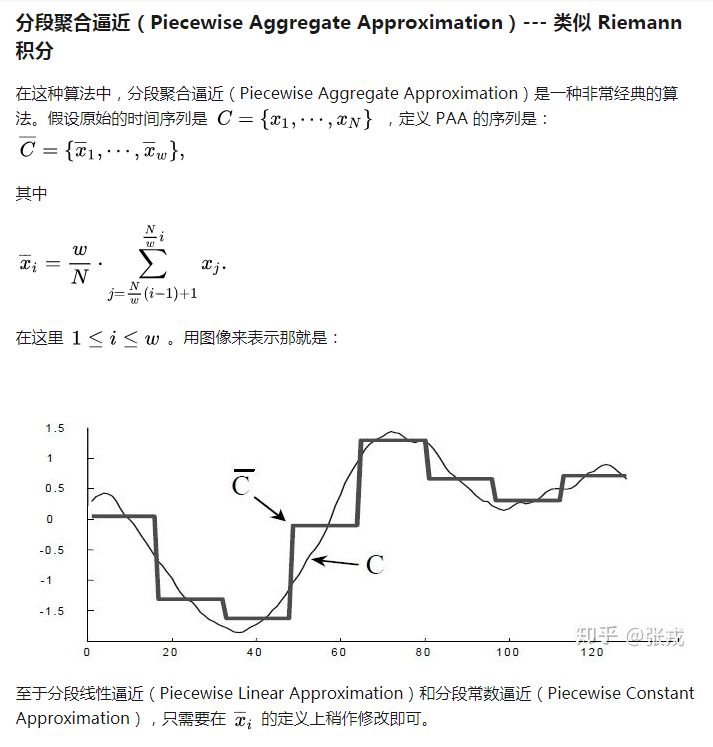

总结
在本篇文章中,我们介绍了时间序列的一些表示方法(Representation),其中包括时间序列统计特征,时间序列的熵特征,时间序列的分段特征。
相关文章推荐:
1.
2.
3.
4.
欢迎大家关注公众账号数学人生
以上是关于时间序列的表示与信息提取的主要内容,如果未能解决你的问题,请参考以下文章