基于机器学习算法的时间序列价格异常检测(附代码)
Posted 量化投资与机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于机器学习算法的时间序列价格异常检测(附代码)相关的知识,希望对你有一定的参考价值。
近期原创文章:
♥
♥
♥
♥
♥
♥
♥
♥
♥
♥
♥
正文
异常检测是指检测数据集里面与其他数据不相符的数据点。
异常检测也称为异常值检测,是一种数据挖掘过程,用于确定数据集中发现的异常类型并确定其出现的详细信息。 在当今世界,由于大量数据无法手动标记异常值,自动异常检测显得至关重要。 自动异常检测具有广泛的应用,例如欺诈检测,系统健康监测,故障检测以及传感器网络中的事件检测系统等。
你是否有过这样的经历,比如,你经常前往某个目的地进行商务旅行,并且你总是住在同一家酒店。虽然大部分时间那里的房价几乎总是相似的,但偶尔相同的酒店,相同的房间类型,费率却高得令人无法接受,以致于你必须换到另一家酒店,因为你的旅行补贴不能包含这么高的价格。我经历了好几次这样的事情,这让我想到,如果我们能够创建一个模型来自动检测这种价格异常会怎么样呢?
当然某些情况下,一些异常在我们这一生中也只会发生一次,并且我们会事先知道它们的发生,还知道在未来每年的相同时间几乎不会再发生,例如2019年2月2日至2月4日亚特兰大荒谬的酒店价格(译者注:2019年2月3日,第53届超级碗比赛在亚特兰大梅赛德斯——奔驰体育场举行)。
在这篇文章中,我们将探讨不同的异常检测技术,我们的目标是在无监督学习的情况下考察酒店房间价格的时间序列中所在的异常。让我们开始吧!
数据获取
事实上要获取全部数据非常困难,我只能得到一些不完美的数据。
import pandas as pd
import numpy as np
import matplotlib.dates as md
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import host_subplot
import mpl_toolkits.axisartist as AA
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.covariance import EllipticEnvelope
from pyemma import msm
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
from mpl_toolkits.mplot3d import Axes3D
from pyemma import msm
%matplotlib inline
我们将使用的数据是Personalize Expedia Hotel Searches数据集的子集,读者可在此处找到(https://www.kaggle.com/c/expedia-personalized-sort/data,其中训练集为train.csv,测试集为test.csv)。
我们打算按如下方式对训练集train.csv的一个子集进行剪切:
选择包含数据点最多的一个酒店property_id = 104517。
选择visitor_location_country_id = 219 ,国家ID 219是指美国。 我们这样做是为了统一price_usd列。由于不同国家在显示税费方面有不同的惯例,所以此列的价格可能是每晚或整个住宿的。而我们知道此列向美国游客展示的价格总是每晚不含税的。
选择search_room_count = 1。
选择我们需要的特征:date_time,price_usd,srch_booking_window,srch_saturday_night_bool。
expedia = pd.read_csv('expedia_train.csv')
df = expedia.loc[expedia['prop_id'] == 104517]
df = df.loc[df['srch_room_count'] == 1]
df = df.loc[df['visitor_location_country_id'] == 219]
df = df[['date_time', 'price_usd', 'srch_booking_window', 'srch_saturday_night_bool']]
进行数据剪切后,我们将要适用的数据如下:
df.info()
df['price_usd'].describe() 
至此,我们已经检测到一个极端异常,即最大price_usd是5584美元。
如果某单一数据点可被视为相应于其余数据的异常,我们则称之为Point Anomalies(例如,购买具有大的交易价值的物品)。我们可以回去检查搜索日志,看看它是什么。 经过一番调查后,我猜它要么是一个错误要么是用户偶然搜索了一个总统套房而无意预订或查看。为了找到更多不是极端的异常,决定删除这个点。
expedia.loc[(expedia['price_usd'] == 5584) &
(expedia['visitor_location_country_id'] == 219)]

df = df.loc[df['price_usd'] < 5584]至此,我相信你已经发现我们遗漏了一些东西,也就是说,我们不知道用户搜索的房间类型,标准间的价格可能与大床海景房的价格有很大差异。请记住这一点,但为了示范目的,我们不得不继续。
时间序列可视化
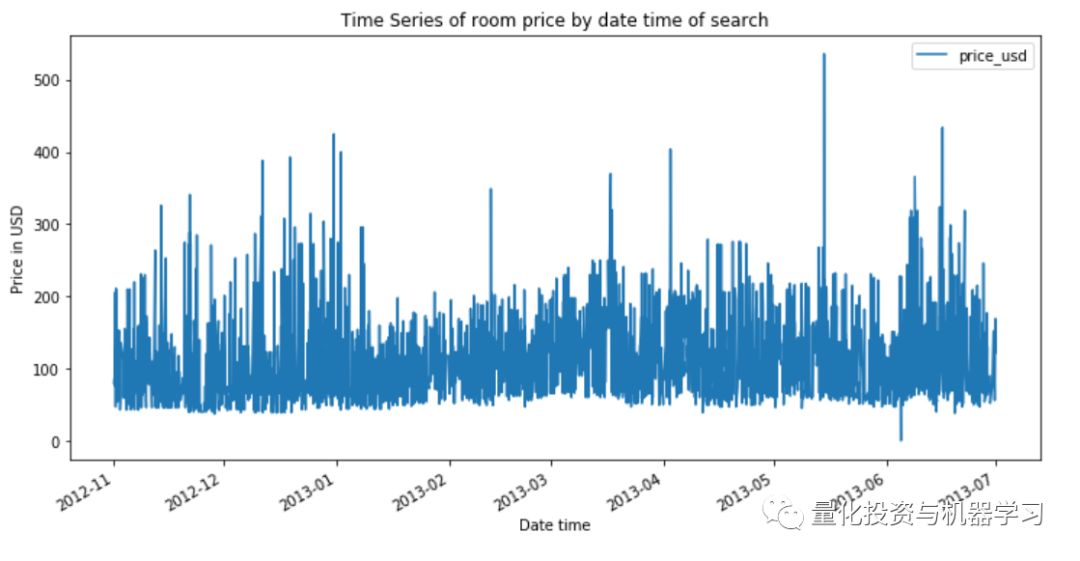
df.plot(x='date_time', y='price_usd', figsize=(12,6))
plt.xlabel('Date time')
plt.ylabel('Price in USD')
plt.title('Time Series of room price by date time of search');
a = df.loc[df['srch_saturday_night_bool'] == 0, 'price_usd']
b = df.loc[df['srch_saturday_night_bool'] == 1, 'price_usd']
plt.figure(figsize=(10, 6))
plt.hist(a, bins = 50, alpha=0.5, label='Search Non-Sat Night')
plt.hist(b, bins = 50, alpha=0.5, label='Search Sat Night')
plt.legend(loc='upper right')
plt.xlabel('Price')
plt.ylabel('Count')
plt.show();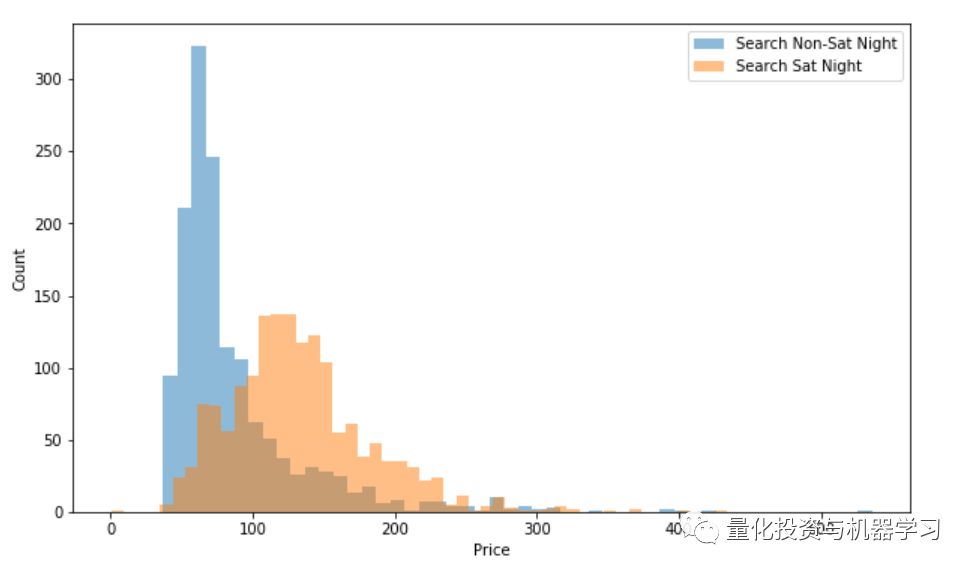
一般来说,搜索非周六晚上的价格会更稳定且更低,而周六晚上的价格通常会上涨,看来这家酒店在周末很受欢迎。
基于聚类算法的异常检测
k-means 算法
k-means是一种应用广泛的聚类算法。它创建了k个类似的数据点集(即聚类),不属于这些组的数据可能会被标记为异常。在我们开始应用k-means算法之前,先使用elbow方法来确定最佳聚类数。
data = df[['price_usd', 'srch_booking_window', 'srch_saturday_night_bool']]
n_cluster = range(1, 20)
kmeans = [KMeans(n_clusters=i).fit(data) for i in n_cluster]
scores = [kmeans[i].score(data) for i in range(len(kmeans))]
fig, ax = plt.subplots(figsize=(10,6))
ax.plot(n_cluster, scores)
plt.xlabel('Number of Clusters')
plt.ylabel('Score')
plt.title('Elbow Curve')
plt.show();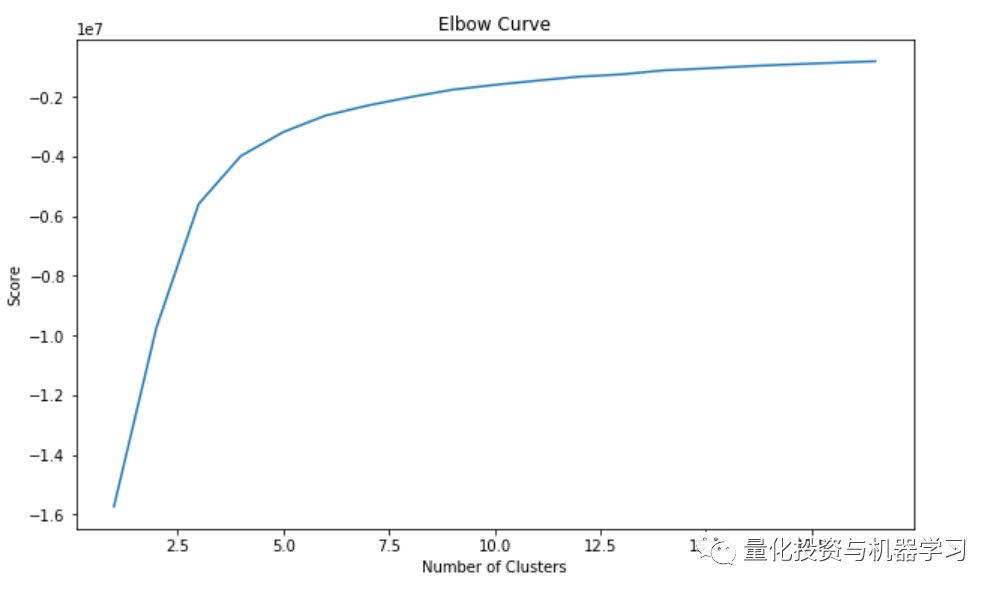
从上面的肘曲线我们看到,图形在聚类数目为10之后趋于平稳,这意味着添加更多聚类并不能解释我们相关变量中的更多方差。
我们设置n_clusters = 10,并将k-means的输出数据绘制成3D聚类图。
X = df[['price_usd', 'srch_booking_window', 'srch_saturday_night_bool']]
X = X.reset_index(drop=True)
km = KMeans(n_clusters=10)
km.fit(X)
km.predict(X)
labels = km.labels_
#Plotting
fig = plt.figure(1, figsize=(7,7))
ax = Axes3D(fig, rect=[0, 0, 0.95, 1], elev=48, azim=134)
ax.scatter(X.iloc[:,0], X.iloc[:,1], X.iloc[:,2],
c=labels.astype(np.float), edgecolor="k")
ax.set_xlabel("price_usd")
ax.set_ylabel("srch_booking_window")
ax.set_zlabel("srch_saturday_night_bool")
plt.title("K Means", fontsize=14);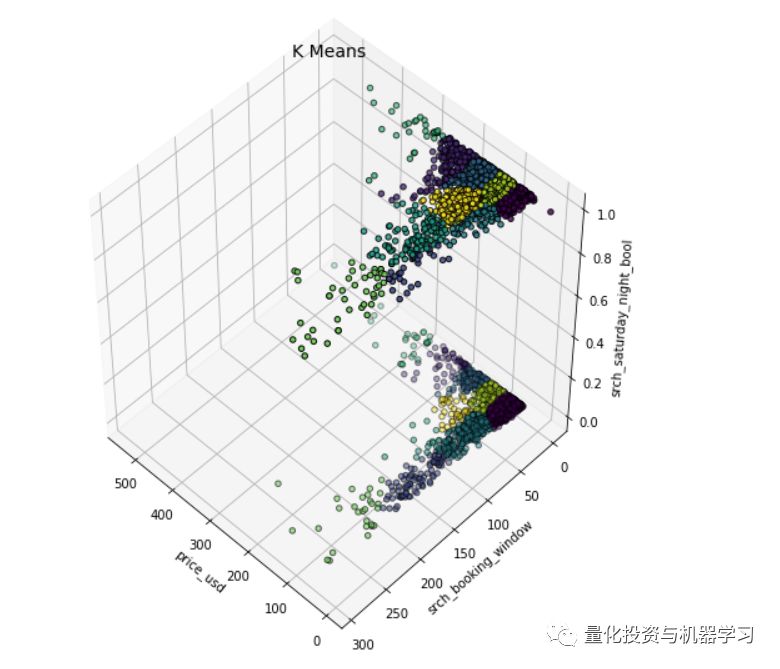
现在我们需要用PCA(Principal component analysis,主成分分析)算法确定保留多少个特征是最合适的。
data = df[['price_usd', 'srch_booking_window', 'srch_saturday_night_bool']]
X = data.values
X_std = StandardScaler().fit_transform(X)
mean_vec = np.mean(X_std, axis=0)
cov_mat = np.cov(X_std.T)
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
eig_pairs = [ (np.abs(eig_vals[i]),eig_vecs[:,i]) for i in range(len(eig_vals))]
eig_pairs.sort(key = lambda x: x[0], reverse= True)
tot = sum(eig_vals)
var_exp = [(i/tot)*100 for i in sorted(eig_vals, reverse=True)] # Individual explained variance
cum_var_exp = np.cumsum(var_exp) # Cumulative explained variance
plt.figure(figsize=(10, 5))
plt.bar(range(len(var_exp)), var_exp, alpha=0.3, align='center', label='individual explained variance', color = 'g')
plt.step(range(len(cum_var_exp)), cum_var_exp, where='mid',label='cumulative explained variance')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.legend(loc='best')
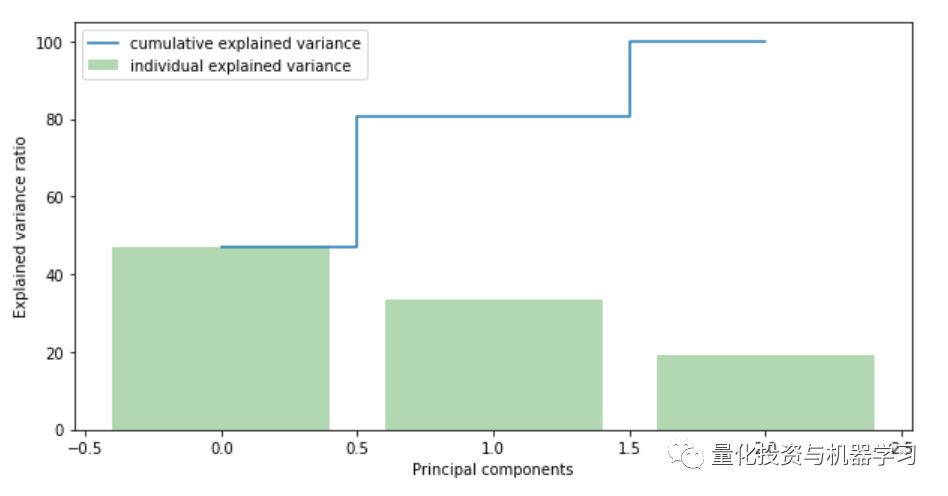
我们看到第一个成分price_usd解释了近50%的差异,第二个成分srch_booking_window解释了超过30%。但同时我们也必须注意到,几乎没有任何成分可以忽略不计。由于前两个成分包含80%以上的信息,所以我们将设置n_components = 2。
基于聚类算法的异常检测的基本假设是,如果我们对数据进行聚类划分,则正常数据将属于聚类,而异常数据将不属于任何聚类或属于小聚类。我们使用以下步骤来查找和可视化异常数据。
计算每个点与其最近的质心点之间的距离,最大的距离被认为是异常的。
我们使用outliers_fraction为算法提供有关数据集中存在的异常值比例的信息,不同的数据集这个参数的设置也不尽相同。然而,我首先给出初始估计outliers_fraction = 0.01,因为在标准正态分布中它的百分比与均值的Z score距离的绝对值超过了3。
使用outliers_fraction计算number_of_outliers。
将threshold设置为这些异常值的最小距离。
异常检测结果anomaly1包含了上述方法(0:正常,1:异常)。
使用聚类视图可视化异常点。
使用时间序列视图可视化异常点。
def getDistanceByPoint(data, model):
distance = pd.Series()
for i in range(0,len(data)):
Xa = np.array(data.loc[i])
Xb = model.cluster_centers_[model.labels_[i]-1]
distance.set_value(i, np.linalg.norm(Xa-Xb))
return distance
outliers_fraction = 0.01
# get the distance between each point and its nearest centroid. The biggest distances are considered as anomaly
distance = getDistanceByPoint(data, kmeans[9])
number_of_outliers = int(outliers_fraction*len(distance))
threshold = distance.nlargest(number_of_outliers).min()
# anomaly1 contain the anomaly result of the above method Cluster (0:normal, 1:anomaly)
df['anomaly1'] = (distance >= threshold).astype(int)
# visualisation of anomaly with cluster view
fig, ax = plt.subplots(figsize=(10,6))
colors = {0:'blue', 1:'red'}
ax.scatter(df['principal_feature1'], df['principal_feature2'], c=df["anomaly1"].apply(lambda x: colors[x]))
plt.xlabel('principal feature1')
plt.ylabel('principal feature2')
plt.show();
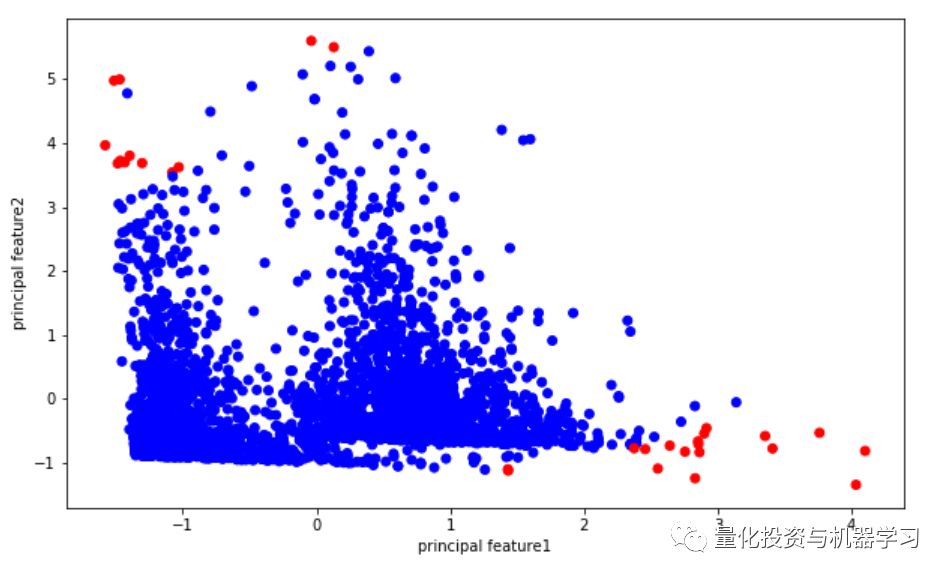
df = df.sort_values('date_time')
df['date_time_int'] = df.date_time.astype(np.int64)
fig, ax = plt.subplots(figsize=(10,6))
a = df.loc[df['anomaly1'] == 1, ['date_time_int', 'price_usd']] #anomaly
ax.plot(df['date_time_int'], df['price_usd'], color='blue', label='Normal')
ax.scatter(a['date_time_int'],a['price_usd'], color='red', label='Anomaly')
plt.xlabel('Date Time Integer')
plt.ylabel('price in USD')
plt.legend()
plt.show();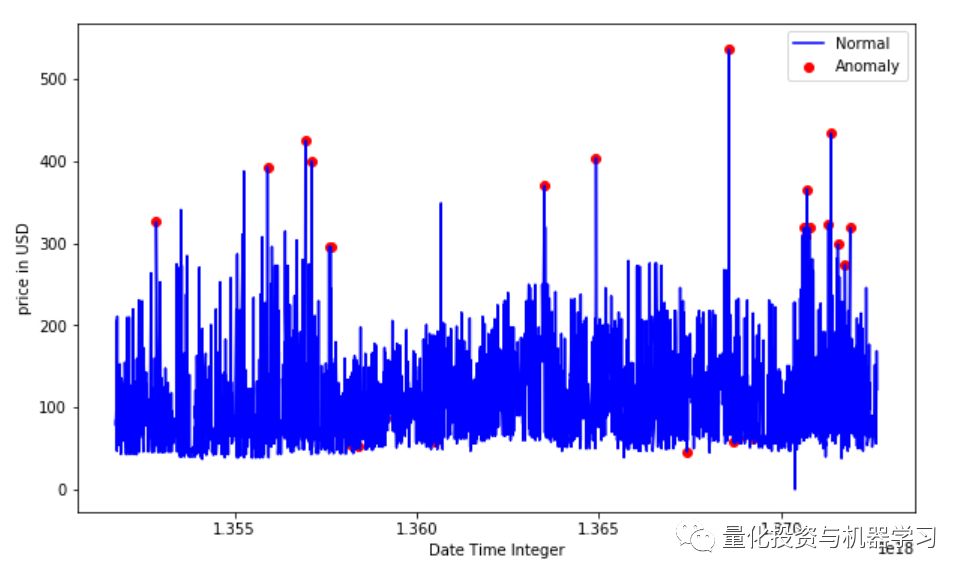
看起来由k-means聚类算法获得的异常价格要么是非常高的费率要么是非常低的费率。
基于孤立森林算法的异常检测
孤立森林算法来检测异常纯粹是基于一个事实:异常点是少数的和不同的。该算法在不采用任何距离或密度测量的情况下实现异常点隔离,这与基于聚类的或基于距离的算法有根本的不同。
在应用孤立森林模型时,我们设置contamination = outliers_fraction,即告诉模型数据集中的异常值比例为0.01。
fit和predict(data)对数据执行异常检测,返回1表示正常,-1表示异常。
最后,我们使用时间序列视图可视化异常点。
data = df[['price_usd', 'srch_booking_window', 'srch_saturday_night_bool']]
scaler = StandardScaler()
np_scaled = scaler.fit_transform(data)
data = pd.DataFrame(np_scaled)
# train isolation forest
model = IsolationForest(contamination=outliers_fraction)
model.fit(data)
df['anomaly2'] = pd.Series(model.predict(data))
# visualization
fig, ax = plt.subplots(figsize=(10,6))
a = df.loc[df['anomaly2'] == -1, ['date_time_int', 'price_usd']] #anomaly
ax.plot(df['date_time_int'], df['price_usd'], color='blue', label = 'Normal')
ax.scatter(a['date_time_int'],a['price_usd'], color='red', label = 'Anomaly')
plt.legend()
plt.show();
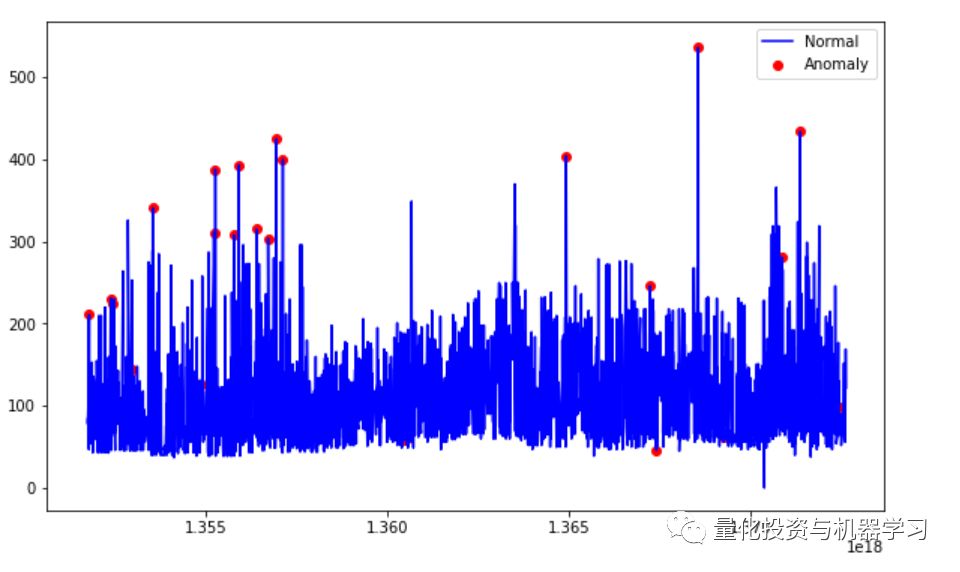
基于支持向量机算法的异常检测
SVM通常与监督学习相关联,但OneClassSVM可将异常检测问题看作无监督学习问题,其学习一个用于异常检测的决策函数:将新数据分类为与训练集相似或不同两类。
OneClassSVM
根据文章《Support Vector Method for Novelty Detection》(http://users.cecs.anu.edu.au/~williams/papers/P126.pdf),我们知道SVM是最大化几何边缘区的方法,而不是构建一个概率分布模型。SVM用于异常检测的思想在于寻找一个函数,使得其在高密度点区域取值为正在低密度点区域取值为负。
在拟合OneClassSVM模型时,我们设置nu = outliers_fraction,它是训练误差分数的上限和支持向量分数的下限,并且必须在0和1之间。基本上这恰好与我们期望的数据集中的异常值比例相符。
指定要在算法中使用的内核类型:rbf,这将使SVM能够使用非线性函数将超空间投影到更高的维度。
gamma是RBF核类型的参数,并控制各个训练样本的影响——这会影响模型的“平滑度”。通过实验,我没有发现任何显著差异。
predict(data) 对数据进行分类,因为我们的模型是单类模型,所以返回+1或-1,其中-1表示异常,1表示正常。
data = df[['price_usd', 'srch_booking_window', 'srch_saturday_night_bool']]
scaler = StandardScaler()
np_scaled = scaler.fit_transform(data)
data = pd.DataFrame(np_scaled)
# train oneclassSVM
model = OneClassSVM(nu=outliers_fraction, kernel="rbf", gamma=0.01)
model.fit(data)
df['anomaly3'] = pd.Series(model.predict(data))
fig, ax = plt.subplots(figsize=(10,6))
a = df.loc[df['anomaly3'] == -1, ['date_time_int', 'price_usd']] #anomaly
ax.plot(df['date_time_int'], df['price_usd'], color='blue')
ax.scatter(a['date_time_int'],a['price_usd'], color='red')
plt.show();
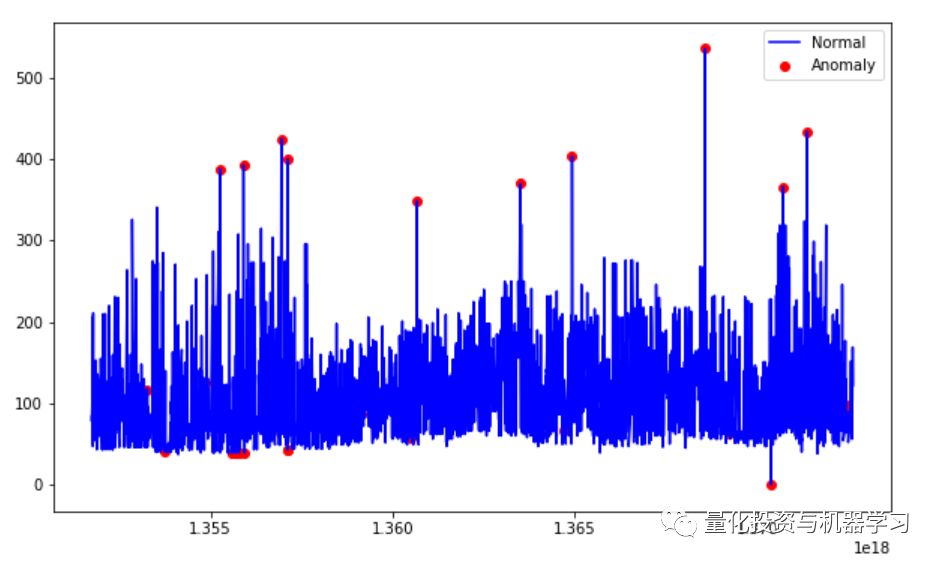
基于高斯分布的异常检测
高斯分布也称为正态分布。我们将使用高斯分布来开发异常检测算法,也就是说,假设我们的数据是正态分布的。这个假设不能适用于所有的数据集,但是当它成立时,却提供了一种有效的方法来发现异常值。
Scikit-Learn的covariance.EllipticEnvelope是一个函数,它通过假设我们的整个数据集满足多元高斯分布,从而计算数据集一般分布的关键参数。过程如下:
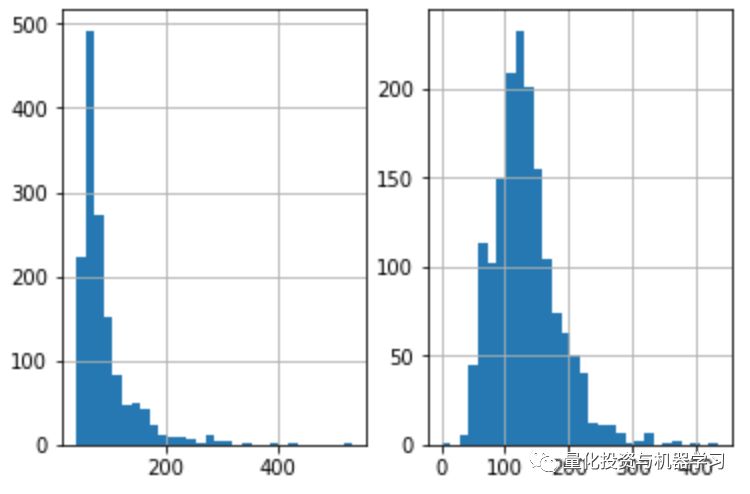
根据前面定义的类别创建两个不同的数据集:search_Sat_night,Search_Non_Sat_night。
对每个类别相应的数据集应用EllipticEnvelope(高斯分布)。
设置contamination参数,即我们数据集中异常值的比例。
我们使用decision_function来计算给定观察点的决策函数。它等于移位的Mahalanobis 距离。异常值的阈值为0,确保了与其他异常值检测算法的兼容性。
predict(X_train) 根据拟合模型来预测X_train的标签(1表示正常,-1表示异常)。
df_class0 = df.loc[df['srch_saturday_night_bool'] == 0, 'price_usd']
df_class1 = df.loc[df['srch_saturday_night_bool'] == 1, 'price_usd']
fig, axs = plt.subplots(1,2)
df_class0.hist(ax=axs[0], bins=30)
df_class1.hist(ax=axs[1], bins=30);
envelope = EllipticEnvelope(contamination = outliers_fraction)
X_train = df_class0.values.reshape(-1,1)
envelope.fit(X_train)
df_class0 = pd.DataFrame(df_class0)
df_class0['deviation'] = envelope.decision_function(X_train)
df_class0['anomaly'] = envelope.predict(X_train)
envelope = EllipticEnvelope(contamination = outliers_fraction)
X_train = df_class1.values.reshape(-1,1)
envelope.fit(X_train)
df_class1 = pd.DataFrame(df_class1)
df_class1['deviation'] = envelope.decision_function(X_train)
df_class1['anomaly'] = envelope.predict(X_train)
# plot the price repartition by categories with anomalies
a0 = df_class0.loc[df_class0['anomaly'] == 1, 'price_usd']
b0 = df_class0.loc[df_class0['anomaly'] == -1, 'price_usd']
a2 = df_class1.loc[df_class1['anomaly'] == 1, 'price_usd']
b2 = df_class1.loc[df_class1['anomaly'] == -1, 'price_usd']
fig, axs = plt.subplots(1,2)
axs[0].hist([a0,b0], bins=32, stacked=True, color=['blue', 'red'])
axs[1].hist([a2,b2], bins=32, stacked=True, color=['blue', 'red'])
axs[0].set_title("Search Non Saturday Night")
axs[1].set_title("Search Saturday Night")
plt.show();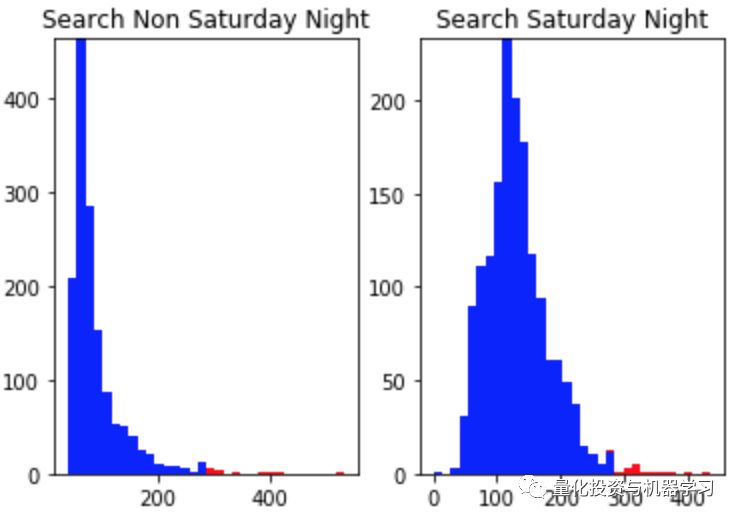
# add the data to the main
df_class = pd.concat([df_class0, df_class1])
df['anomaly5'] = df_class['anomaly']
# df['anomaly5'] = np.array(df['anomaly22'] == -1).astype(int)
fig, ax = plt.subplots(figsize=(10, 6))
a = df.loc[df['anomaly5'] == -1, ('date_time_int', 'price_usd')] #anomaly
ax.plot(df['date_time_int'], df['price_usd'], color='blue', label='Normal')
ax.scatter(a['date_time_int'],a['price_usd'], color='red', label='Anomaly')
plt.legend()
plt.show();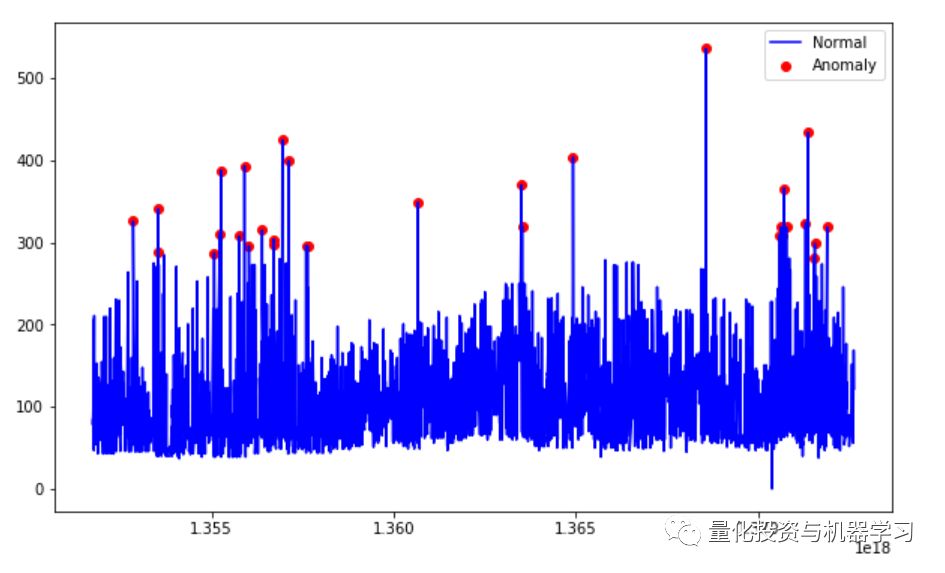
有趣的是可以看到,以这种方式检测到的异常点只有异常的高价点而没有异常的低价点。
马尔可夫链的异常检测
我们需要对马尔可夫链定义状态下的数据点进行离散化。我们将使用'price_usd'来定义这个示例的状态,并定义5个级别的值(非常低、非常低、平均、非常高、非常高)/(VL、L、A、H、VH)。马尔可夫链可以表示为状态VL,L,L,A,A,H,H,VH。每个价格都是一种状态到另一种状态的价格。我们可以利用历史价格数据建立马尔可夫链,并用它来计算序列概率。然后,我们可以找到任何新序列发生的概率,然后标记为异常的罕见序列。
# train markov model to get transition matrix
def getTransitionMatrix (df):
df = np.array(df)
model = msm.estimate_markov_model(df, 1)
return model.transition_matrix
# return the success probability of the state change
def successProbabilityMetric(state1, state2, transition_matrix):
proba = 0
for k in range(0,len(transition_matrix)):
if (k != (state2-1)):
proba += transition_matrix[state1-1][k]
return 1-proba
# return the success probability of the whole sequence
def sucessScore(sequence, transition_matrix):
proba = 0
for i in range(1,len(sequence)):
if(i == 1):
proba = successProbabilityMetric(sequence[i-1], sequence[i], transition_matrix)
else:
proba = proba*successProbabilityMetric(sequence[i-1], sequence[i], transition_matrix)
return proba
# return if the sequence is an anomaly considering a threshold
def anomalyElement(sequence, threshold, transition_matrix):
if (sucessScore(sequence, transition_matrix) > threshold):
return 0
else:
return 1
# return a dataframe containing anomaly result for the whole dataset
# choosing a sliding windows size (size of sequence to evaluate) and a threshold
def markovAnomaly(df, windows_size, threshold):
transition_matrix = getTransitionMatrix(df)
real_threshold = threshold**windows_size
df_anomaly = []
for j in range(0, len(df)):
if (j < windows_size
df_anomaly.append(0)
else:
sequence = df[j-windows_size:j]
sequence = sequence.reset_index(drop=True)
df_anomaly.append(anomalyElement(sequence, real_threshold, transition_matrix))
return df_anomalydf['anomaly24'] = df_anomaly
fig, ax = plt.subplots(figsize=(10, 6))
a = df.loc[df['anomaly24'] == 1, ('date_time_int', 'price_usd')] #anomaly
ax.plot(df['date_time_int'], df['price_usd'], color='blue')
ax.scatter(a['date_time_int'],a['price_usd'], color='red')
plt.show();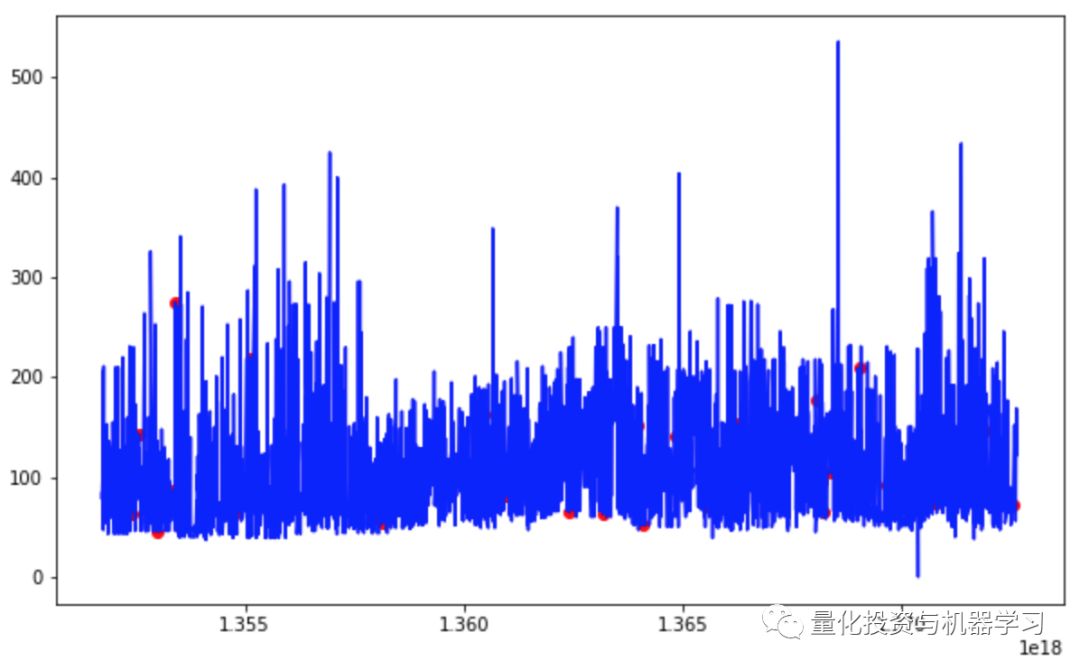
a = df.loc[df['anomaly24'] == 0, 'price_usd']
b = df.loc[df['anomaly24'] == 1, 'price_usd']
fig, axs = plt.subplots(figsize=(16,6))
axs.hist([a,b], bins=32, stacked=True, color=['blue', 'red'])
plt.show();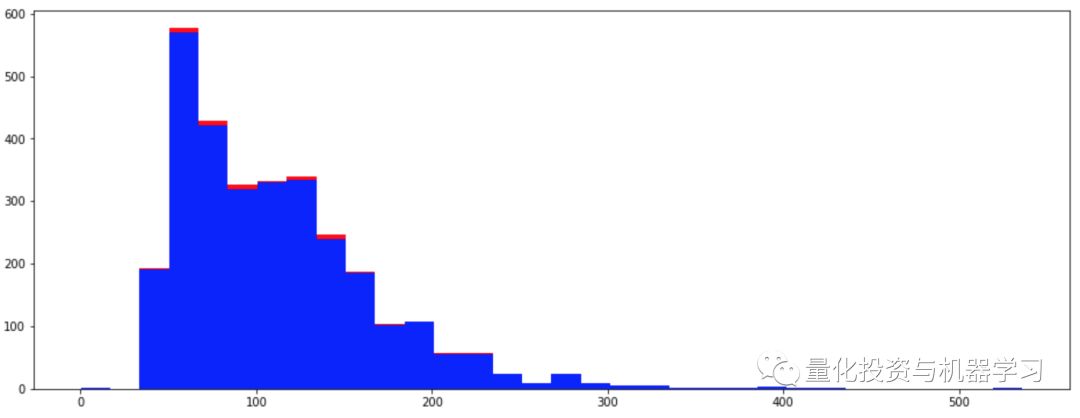
因为我们的异常检测是无监督学习。在构建模型之后,我们不知道它做得有多好,因为我们没有测试它的依据。因此,在将这些方法置于关键路径之前,需要对这些方法的结果进行实地测试。
总结
到目前为止,我们已经用五种不同的方法进行了价格异常检测。因为我们的异常检测是无监督学习,在构建模型之后,由于我们没有任何东西可以对它进行测试,我们也没有办法知道这些方法的有效性。因此,在将这些方法应用于重要场合之前,须务必对其进行现场数据的测试。
参考文献:
1、https://www.datascience.com/blog/python-anomaly-detection
2、https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
3、https://scikit-learn.org/stable/modules/generated/sklearn.svm.OneClassSVM.html
4、https://scikit-learn.org/stable/modules/generated/sklearn.covariance.EllipticEnvelope.html
5、https://www.kaggle.com/victorambonati/unsupervised-anomaly-detection
如何获取代码
在后台输入
20190208
后台获取方式介绍
推荐阅读
以上是关于基于机器学习算法的时间序列价格异常检测(附代码)的主要内容,如果未能解决你的问题,请参考以下文章