一文读懂时间序列专题学习手册
Posted 计量经济学服务中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂时间序列专题学习手册相关的知识,希望对你有一定的参考价值。
来源:综合整理自:http://dss.princeton.edu/training/
转载请注明来源
本文主要包括数据类型转换、自相关图、平稳性、协整、格兰杰检验等内容
1、Quarterly date from daily date
use date.dtadesced
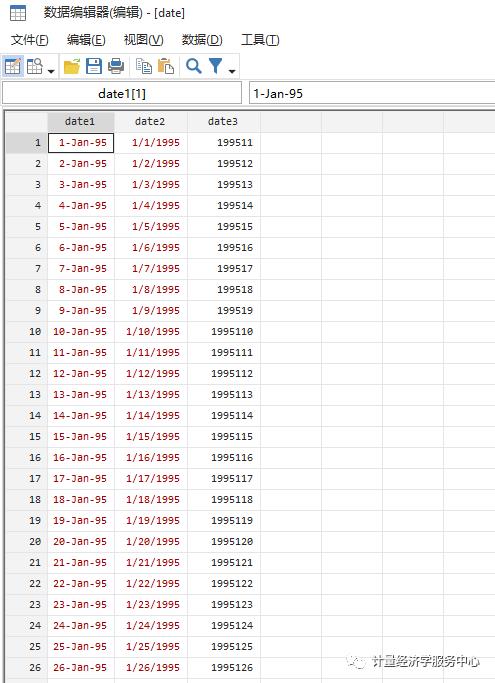
gen datevar=date(date2,"MDY", 2099)format datevar %tdgen quarterly = qofd(datevar)format quarterly %tq
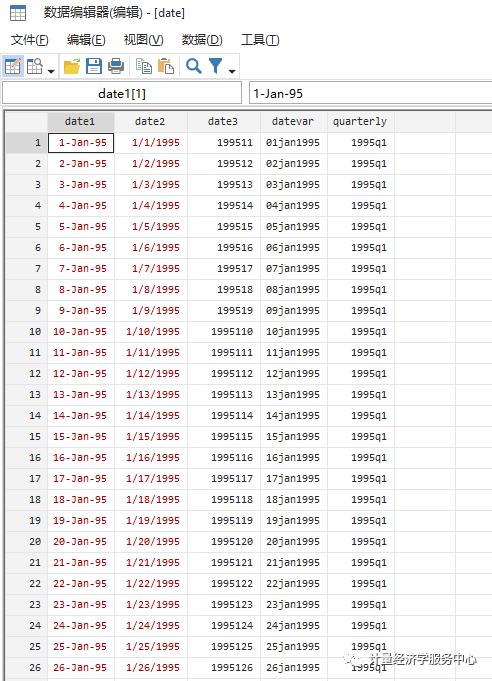
2、Quarterly date from monthly date
gen month = month(datevar)gen day=day(datevar)gen year=year(datevar)gen monthly = ym(year,month)format monthly %tm
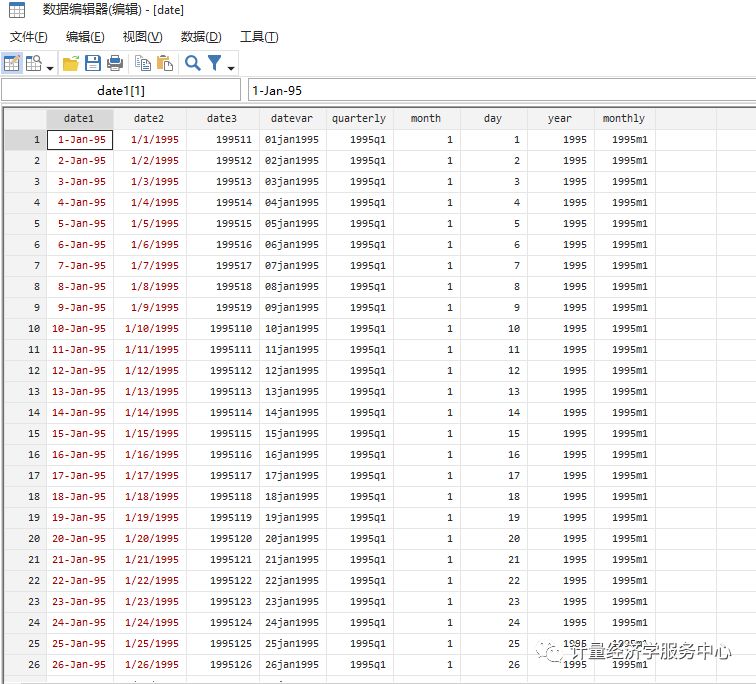
gen datevar = date(date2, "MDY", 2099)format datevar %tdgen year= year(datevar)gen w = week(datevar)gen weekly = yw(year,w)format weekly %twbrowse
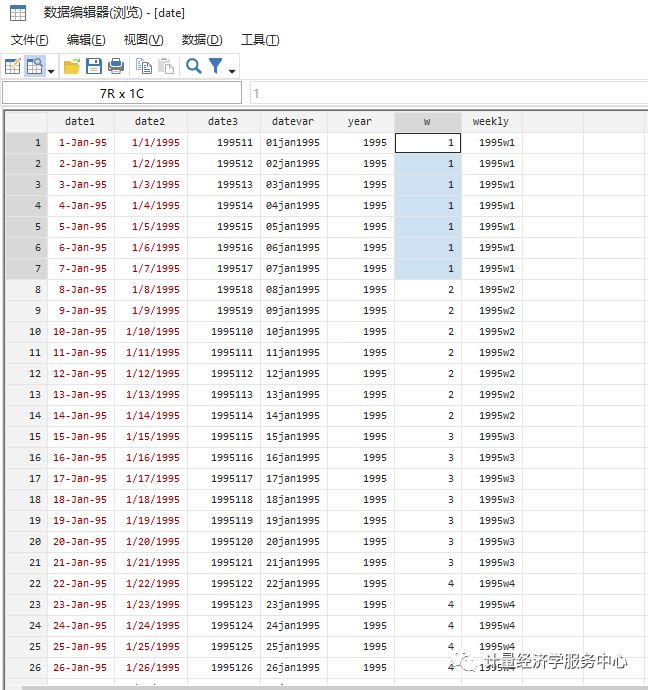
From daily to yearly
gen year1 = year(datevar) From quarterly to yearly
gen year2 = yofd(dofq(quarterly)) From weekly to yearly
gen year3 = yofd(dofw(weekly))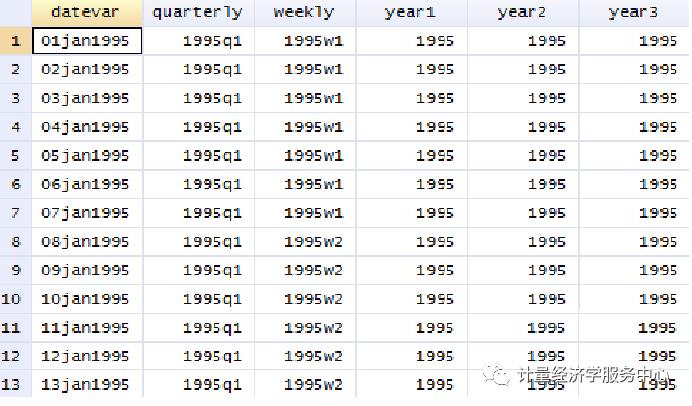
tsset timevar例如

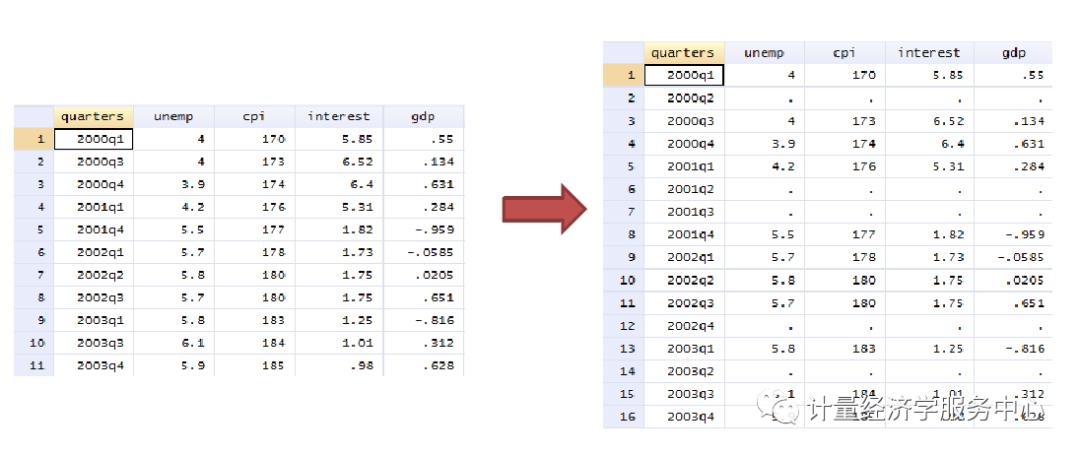
使用命令tsfill可以填补时间序列的空白。使用tsfill 你需要 tset, tsset 或 xtset 的数据 。
tset quarterstsfill
To generate values with past values use the “L” operator
generate unemp L1=L1.unempgenerate unemp L2=L2.unemplist datevar unemp unemp L1 unemp L2 in 1/5
To generate forward or lead values use the “F” operator
generate unemp F1=F1.unempgenerate unemp F2=F2.unemplist datevar unemp unemp F1 unemp F2 in 1/5
To generate the difference between current a previous values use the “D” operator
generate unemp D1=D1.unempgenerate unemp D2=D2.unemplist datevar unemp unemp D1 unemp D2 in 1/5
D1 = y t – yt-1
D2 = (y t – y t-1 ) – (y t-1 – y t-2 )
To generate seasonal differences use the “S” operator
=S1.unempgenerate unemp S2=S2.unemp
S1 = y t – y t-1
S2 = (y t – y t-2 )
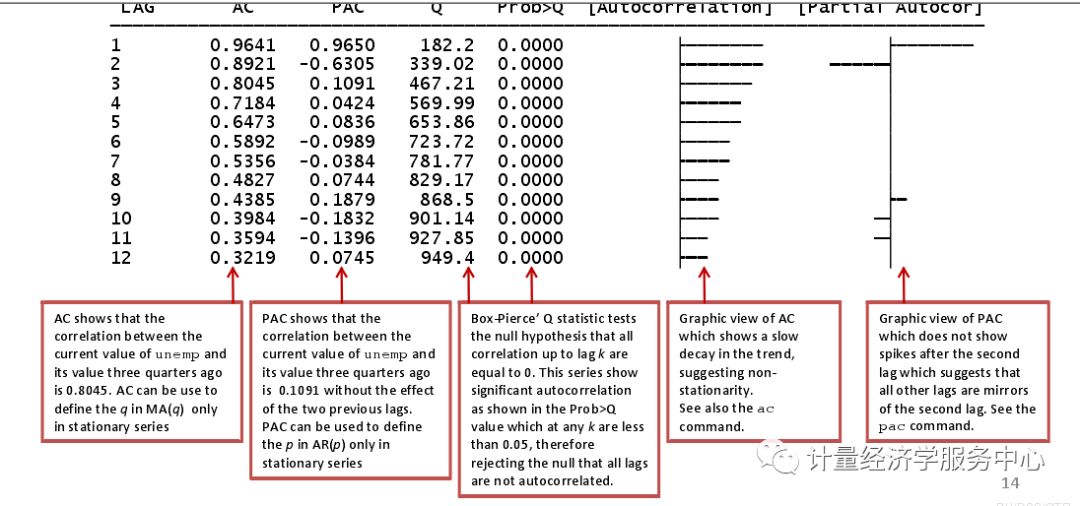
corrgram unemp, lags(12) 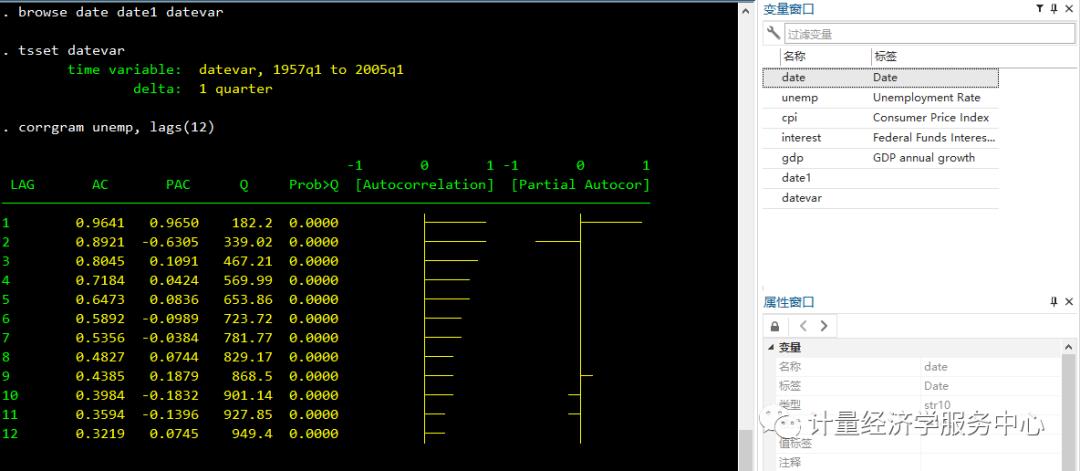
line unemp datevar 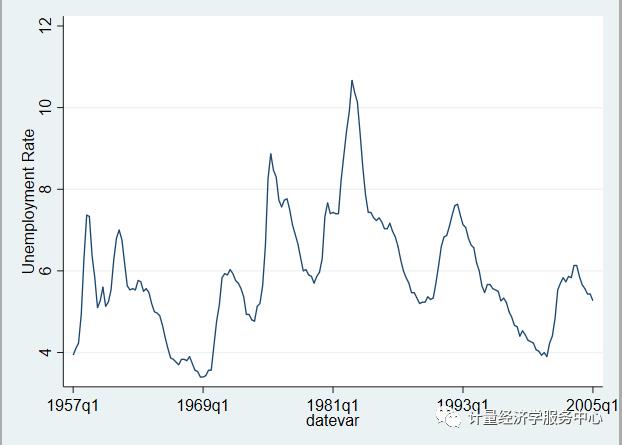
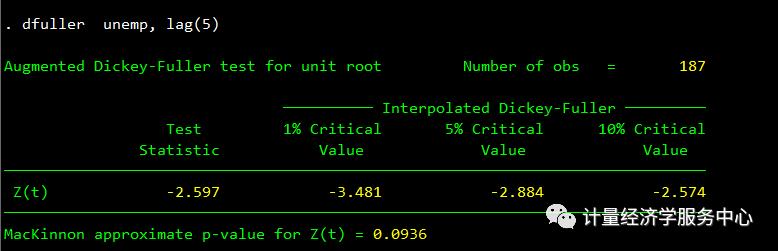
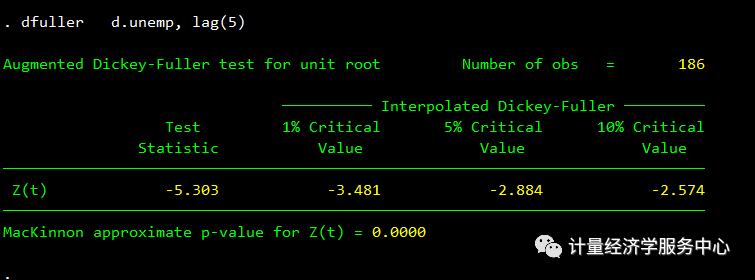
Dickey-Fuller检验是最常用的平稳性检验之一。零假设这个级数有一个单位根。检验统计数据表明,失业率系列有一个单位根,它位于接受区域内。
处理随机趋势(单位根)的一种方法是取变量的一阶差分。
dfuller unemp, lag(5)dfuller d.unemp1, lag(5)
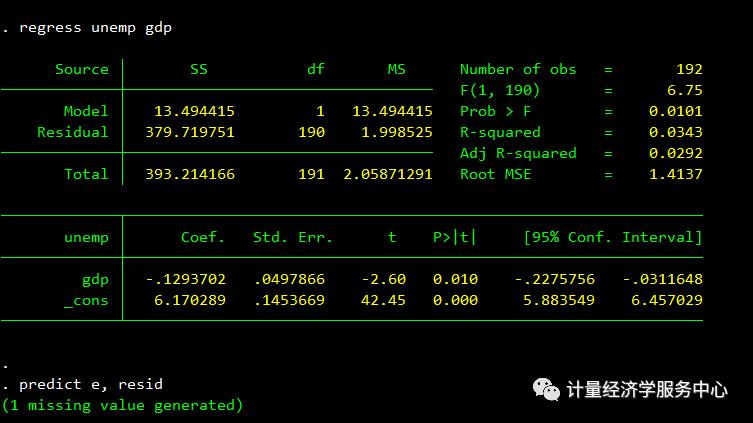
regress unemp gdppredict e, residdfuller e, lags(10)

本部分来源:http://dss.princeton.edu/training/,部分资源整理自:百度文库、CDA数据分析师、社会科学中的数据可视化
在实证分析中,我们经常需要确定因果关系是x导致y,还是y导致x。对此,Granger提出了一种解决方法:如果x是y的原因,且不存在反向因果,则x过去值可以预测y未来值,反之则不然。具体来说,我们建立时间序列模型如下,并提出假设H0:βm=0,m=1,2…p。如果接受该假设,则意味着x过去值不能够预测y未来值;如果拒绝该假设,则可以,即x是y的格兰杰因(Granger cause)。
格兰杰因果关系检验假设了有关y和x每一变量的预测的信息全部包含在这些变量的时间序列之中。检验要求估计以下的两个回归模型:
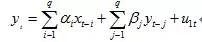
模型1
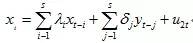
模型2
模型1是为了检验X对Y的影响,模型二是为了检验Y对X的影响。(其中白噪音u1t 和u2t假定为不相关的)
基本逻辑:
模型一中,如果模型α1,α2 , ... , αq 中只要存在一个系数显著为不零,那就认为X对Y有格兰杰因果关系,模型二类似;
方法一:
reg y L.y L.x (滞后1 期)estat ic (显示AIC 与BIC 取值,以便选择最佳滞后期)reg y L.y L.x L2.y L2.xestat ic (显示AIC 与BIC 取值,以便选择最佳滞后期)……
特别说明,此处p和q的取值完全可以不同,而且应该不同,这样才能获得最有说服力的结果,这也是该方法与其他两个方法相比的最大优点,该方法缺点是命令过于繁琐。
方法二:
ssc install gcause (下载格兰杰因果检验程序gcause)gcause y x,lags(1) (滞后1 期)estat ic (显示AIC 与BIC 取值,以便选择最佳滞后期)gcause y x,lags(2) (滞后2 期)estat ic (显示AIC 与BIC 取值,以便选择最佳滞后期)
特别说明,在选定滞后期后,对于因果关系检验,该方法提供F检验和卡方检验。如果两个检验结论不一致,原则上用F检验更好些。因为卡方检验是一个大样本检验,而实证检验所能获得的样本容量通常并不大,如果采用的是大样本,则以卡方检验结果为准。不过,通常情况下,大样本下两个检验结论一致,所以不用担心。综上,F检验适用范围更广。
方法三:
var y x (向量自回归)vargranger
注意:1、如果实际检验过程中AIC和BIC越来越小,直到不能再滞后(时间序列长度所限)。这样的话,可能数据确实存在高阶自相关。在这种情况下,可以限制p的取值,比如取最大的或 , 。2、回归结果中各期系数显著性不同,有的不显著有的显著,如实汇报就可以。最好全部汇报。不显著的期数可能意味着那一期的自相关很弱。
1、导入数据
use http: //www.stata-press.com/data/imeus/ukrates, clear2、安装外部命令(安装gcause格兰杰因果检验程序)
ssc install gcause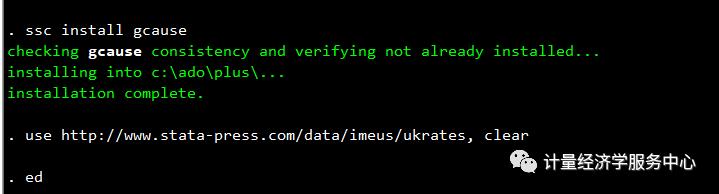
3、格兰杰检验
gcause r20 rs, lags(1)estat icgcause r20 rs, lags(2)estat ic
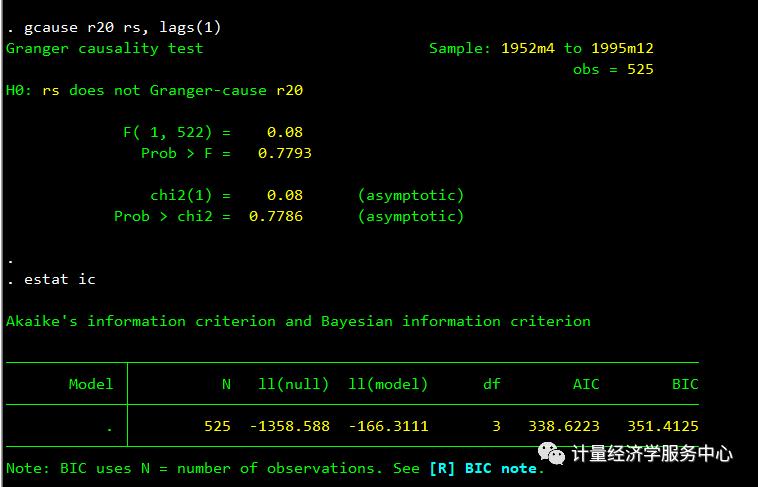
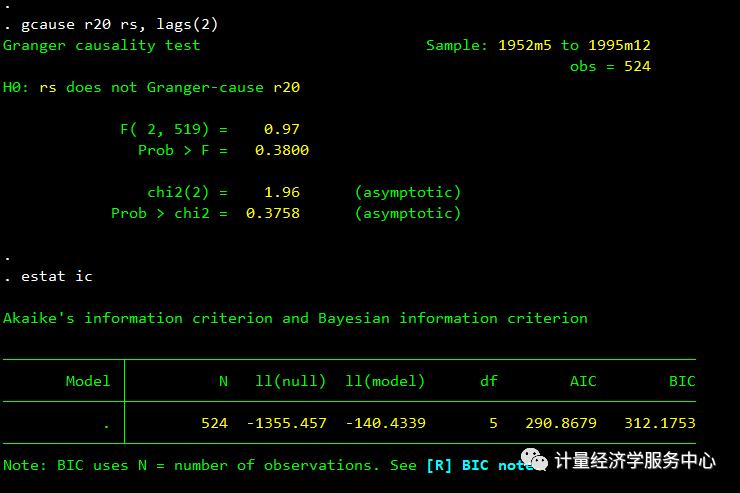
依次对滞后一期、滞后两期等变量进行回归,根据AIC及BIC的取值确定最佳的滞后期。在本例中,我们发现p=q=3时AIC及BIC的值最小,因此我们将p和q都赋值为3。滞后三期回归结果如图所示:
gcause r20 rs, lags(3)estat ic
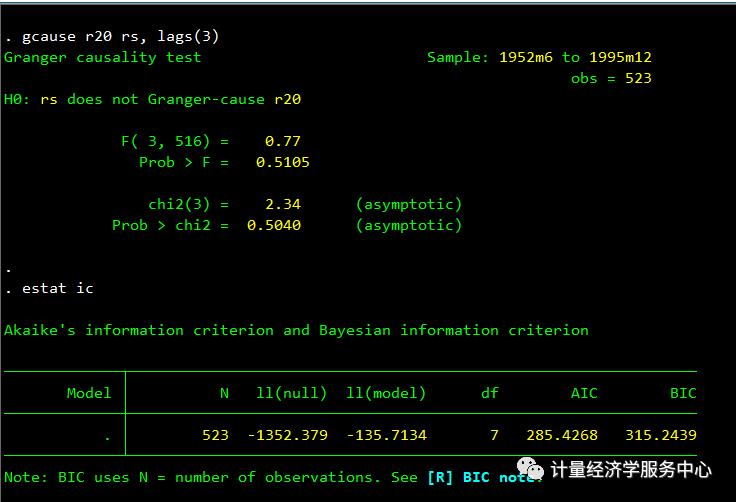
我们发现F检验和卡方检验得出一致结论,接受原假设,即rs不是r20的格兰杰因。
1、导入数据
use "C:\Users\admin\Desktop\tsdata.dta"2、Granger causality: using OLS
If you regress ‘y’ on lagged values of ‘y’ and ‘x’ and the coefficients of the lag of ‘x’ are statistically significantly different from 0, then you can argue that ‘x’ Granger-cause ‘y’, this is, ‘x’ can be used to predict ‘y’ (see Stock & Watson -2007-, Green -2008).
regress unemp L(1/4).unemp L(1/4).gdp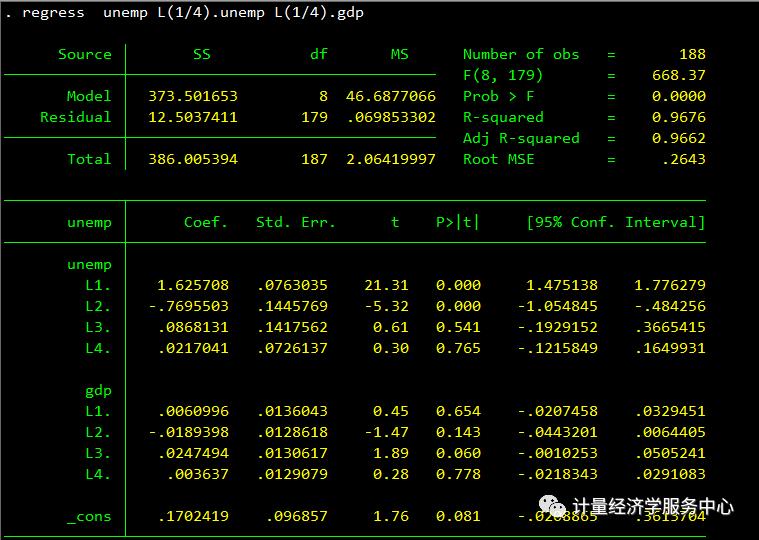
regress unemp L(1/4).unemp L(1/4).gdp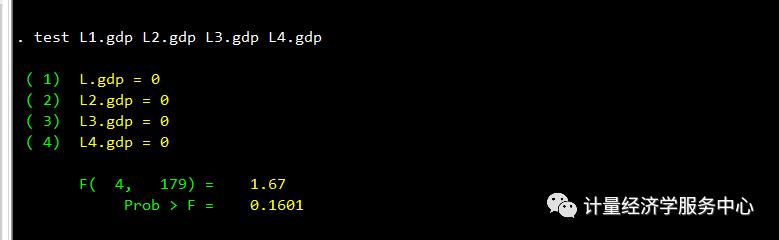
Granger causality: using VAR
quietly var unemp gdp, lags(1/4)vargranger
◆◆◆◆
精彩回顾
点击上图查看:
点击上图查看:
·
·
·
END
l 计量经济学服务中心 l
长按二维码
以上是关于一文读懂时间序列专题学习手册的主要内容,如果未能解决你的问题,请参考以下文章