R语言中使用多重聚合预测算法(MAPA)进行时间序列分析
Posted 拓端数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言中使用多重聚合预测算法(MAPA)进行时间序列分析相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=10016
这是一个简短的演示,可以使用该代码进行操作。使用MAPA生成预测。
> mapasimple(admissions)t+1 t+2 t+3 t+4 t+5 t+6 t+7 t+8 t+9 t+10 t+11 t+12457438.0 446869.3 450146.7 462231.5 457512.8 467895.1 457606.0 441295.7 471611.2 454282.0 458308.0 453472.5
这提供了序列和预测的简单图解:每个时间预测状态的详细视图:
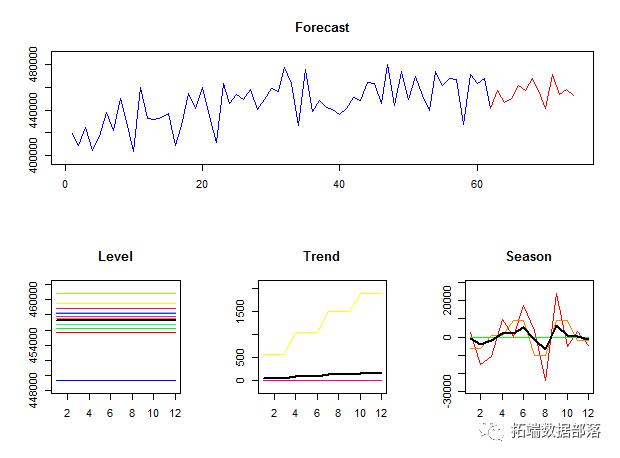
在此示例中,我还使用了paral = 2。创建一个并行集群,然后关闭该集群。如果已经有并行集群在运行,则可以使用paral = 1。
时间聚合的不同级别上的估计和预测。
第一估计模型在每个时间聚合级别的拟合度,还提供已识别ETS组件的可视化。 第二提供样本内和样本外预测。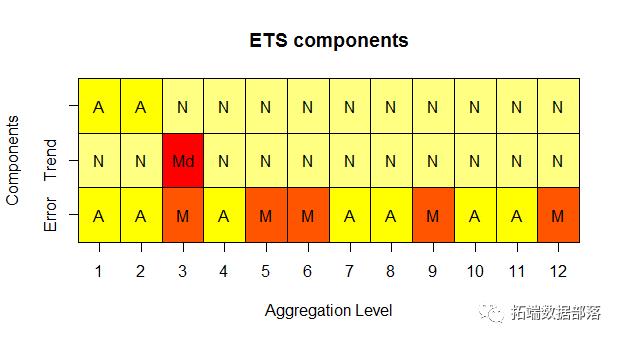
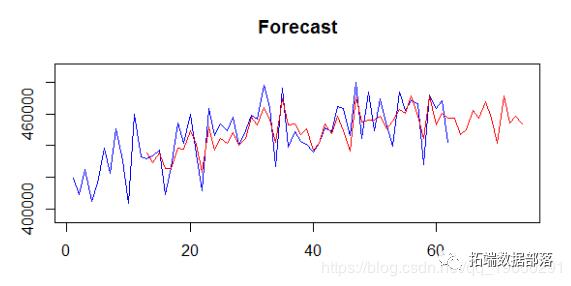
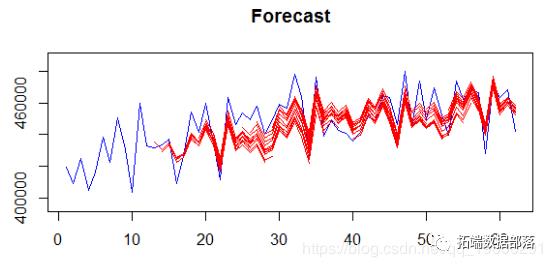
通过在上述任何函数中设置outplot = 0来停止绘制输出。这些函数还有更多选项,可以设置最大时间聚合级别,MAPA组合的类型等。
第一个是在所有聚合级别上强制使用特定的指数平滑模型。
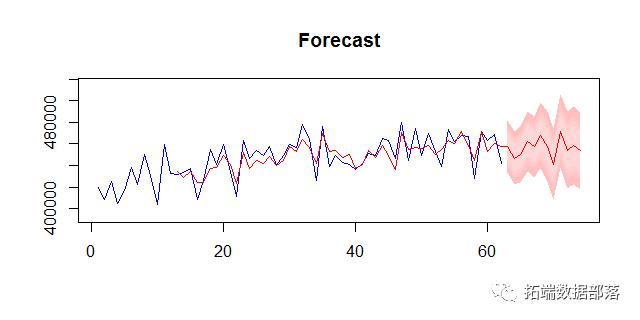
在这种情况下,将非季节性阻尼趋势模型拟合到时间序列。由于MAPA不能再在模型之间进行更改并选择一个简单的模型,因此对于给定系列的汇总版本,预选模型可能具有太多的自由度。此外,如果选择了季节性模型,则对于具有非整数季节性的任何聚合级别,将拟合该模型的非季节性版本。 另一个新选项是能够计算经验预测间隔。由于这些都需要模拟预测以进行计算,因此它们的计算量很大。要获得80%,90%,95%和99%的预测: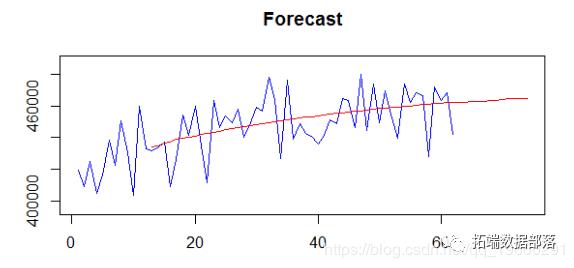
mapa(admissions,conf.lvl=c(0.8,0.9,0.95,0.99),paral=2)
更多内容,请点击左下角“阅读原文”查看


![]()
案例精选、技术干货 第一时间与您分享
长按二维码加关注
更多内容,请点击左下角“阅读原文”查看
以上是关于R语言中使用多重聚合预测算法(MAPA)进行时间序列分析的主要内容,如果未能解决你的问题,请参考以下文章
拓端tecdat|R语言编程指导用线性模型进行臭氧预测: 加权泊松回归,普通最小二乘,加权负二项式模型,多重插补缺失值
R语言使用car包的vif函数计算方差膨胀因子,并基于方差膨胀因子开方后和阈值的判断来确认模型特征(预测变量)之间是否存在多重共线性(Multicollinearity)