内存缓存数据库Memcached基础学习
Posted 云存储技术交流
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内存缓存数据库Memcached基础学习相关的知识,希望对你有一定的参考价值。
memcached是什么?
memcached是高性能的分布式内存缓存服务器。
一般使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态web应用的速度、提高可扩展性
memcached的特征:
1. 协议简单
2. 基于libevent的事件处理
3. 内置内存存储方式
4. memcached不互相通信的分布式
协议简单:
memcached使用简单文本行的协议,因此通过telnet也能在memcached上保存数据,取得数据。
基于libevent的事件处理
libevent是一个程序库,它将linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。
memcached使用这个libevent库,因此在linux、BSD等操作系统上发挥高性能。
内置内存存储方式
memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存储在内存中,因此重启memcached、重启操作系统会导致全部数据的丢失。内容容量达到指定值之后,就基于LRU算法自动删除不使用的缓存。memcached本身是为缓存而设计的服务器,因此没有考虑数据的永久性问题。
memcached不互相通信的分布式
各个memcahced不会互相通信已共享信息,如何进行分布式,是由客户端来实现的。
 向memcached保存数据的方法有:
向memcached保存数据的方法有:
add、replace、set
my $add = $memcached->add( '键', '值', '期限' );
my $replace = $memcached->replace( '键', '值', '期限' );
my $set = $memcached->set( '键', '值', '期限' );
向memcached保存数据时可以指定期限(秒)。不指定期限memcached按照LRU算法保存数据。上面三个方法的区别:
add:仅当存储空间中不存在键相同的数据时才保存
replace:仅当存储空间中存在键相同的数据时才保存
set:与add和replace不同,无论何时都保存
获取数据
获取数据使用get 和 get_multi 方法
一次获取多条数据时使用get_multi,可以非同步的同时取得多个键值,速度要比循环调用get快数十倍
my $val = $memcached->get('键');
my $val = $memcached->get_multi('键1', '键2', '键3', '键4', '键5');
删除数据
删除数据使用delete方法
$memcached->delete('键', '阻塞时间(秒)');
删除第一个参数指定键的数据,第二个参数指定一个时间值,可以禁止使用同样的键保存新数据。此功能可以用于防止缓存数据的不完整。注意:set函数忽视该阻塞,照常保存数据增一和减一操作
memcahced的内存存储机制
slab Allocation机制:整理内存以便重复使用
slab allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定的块,以完全解决内存碎片问题。
slab Allocation 将分配的内存分割成各种尺寸的块(chunk),并把尺寸相同的块分成组(chunk的集合)
slab allocator 能重复使用已分配的内存目的。也就是说,分配到的内存不会释放,而且重复利用。

slab Allocation的主要术语
Page: 内存分配给slab的内存空间,默认是1MB,分配给slab之后根据slab的大小切分成chunk,一个page为4kb
Chunk:用于缓存记录的内存空间
slab class:特定大小chunk的组
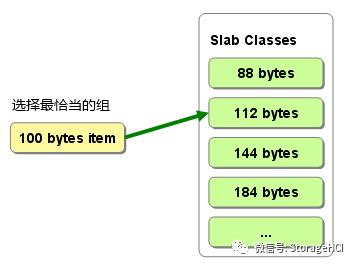
在slab中缓存数据的原理:
memcached根据收到数据的大小,选择最适合数据大小的slab,memcached中保存着slab内空闲的chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
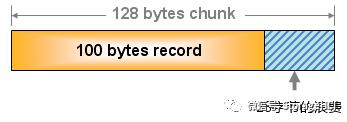
slab Allocator的缺点:
slab allocator 分配的是特定长度的内存因此无法有效利用分配的内存。例如:将100字节的数据缓存到128字节上,剩余的28字节就浪费掉了。
使用Growth Factor进行调优
memcached在启动时指定Growth Factor因子(选项-f),就可以在某种程度上控制slab之间的差异,默认是1.25
设置命令:memcached -f 2 -vv
查看memcahced的内部状态
# telnet 127.0.0.1 11211
stats
查看slabs的使用状况
# memcached-tool 127.0.0.1
# Item_Size Max_age Pages Count Full? Evicted Evict_Time OOM
1 96B 30s 1 1 no 0 0 0
memcached的删除机制
memcached在数据删除方面有效利用资源,数据不会真正从memcached中消失。
memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被成为lazy(惰性) expiration,因此memcached不会在过期监视上耗费cpu时间
LRU: 从缓存中有效删除数据的原理当memcached的内存空间不足时,就从最近未使用的记录中搜索,并将其空间分配给新的记录。新的记录覆盖掉使用最少的chunk
# memcached -M 禁止LRU,一般情况下是非常推荐使用LRU
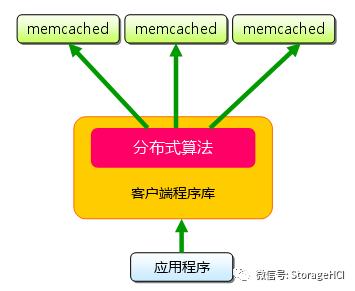
memcached的分布式算法
memcached的分布式
memcached的分布式是由客户端程序库来实现的,这种分布式是memcached最大的特点。
Memcached的分布式方法:
set方法:
首先向memcached中添加'tokyo' 将'tokyo'传给客户端程序库后,客户端实现的算法就会根据'键'来决定保存数据的memcached服务器。
get方法:
获取时也要将要获取的键“tokyo”传递给函数库。 函数库通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值。
hash-type主要有两种方法:
1.取模法:这种算法不适用于memcached分布式,当一台memcached服务器故障,将会造成所有memcached缓存失效。
2.一致性hash算法:首先求出memcached服务器的哈希值,并将其配置到1-2^32的圆上,然后用同样的方法求出存储数据的键的哈希值,并映射到圆上,然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。
以上是关于内存缓存数据库Memcached基础学习的主要内容,如果未能解决你的问题,请参考以下文章