百度QA金BUG集锦之《Redis主从同步失败案例的步步深入》
Posted 百度QA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度QA金BUG集锦之《Redis主从同步失败案例的步步深入》相关的知识,希望对你有一定的参考价值。
在百度质量部,QA的看家本领之一就是发现问题、定位问题、推动问题的妥善修复。本期《金BUG》专辑汇总了几例BUG发现分析解决的案例,欢迎各路英雄关注并讨论
一、背景
2015.7.31 某网段的TOR故障一小时,网络故障恢复后,redis 多个从主从同步异常:除slave0外,其他slave的offset均比master大。
注:redis的主从之间通过offset进行增量同步,即从向主发送它当前存储数据的offset,主将这个offset之后的增量数据同步给从,以保证主从数据一致。然而线上出现从的offset比主大,说明主从同步的逻辑存在问题。
二、问题影响
Redis主从同步分三种:
全量同步(主从首次连接或者增量同步失败) —— redis主dump出所有的数据发给从;
增量同步(主从连接瞬断)—— redis主将slave发送的offset之后的数据发给从;
长连接同步(正常情况) —— redis主从维护一个长连接,redis主将所有写请求发给从;
该问题只会影响redis主和从的增量同步,即网络瞬断时会影响同步,影响分为两种:
发生问题后,进行增量同步时从的offset比主大:增量同步失败,进行全量同步,对redis从中的数据不影响;
发生问题后,进行增量同步时从的offset比主小(出现问题时从的offset比主大,但是随着主写入数据,offset可能会超过从):主从增量同步异常,从中的数据比主少。
三、Bug定位
异常原因
由问题背景可看出bug由从的replica_offset引起,分析代码中会修改从的offset的逻辑:
初始化:从的offset是在向主请求增量同步失败后由主返回:
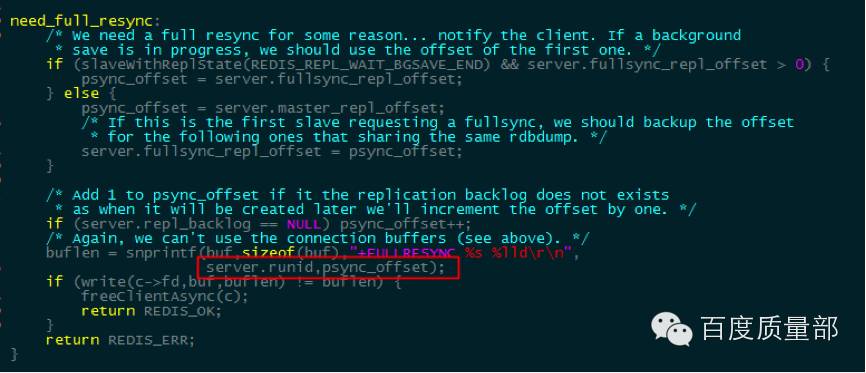
从接受到”+FULLRESYNC”响应后,更新offset:
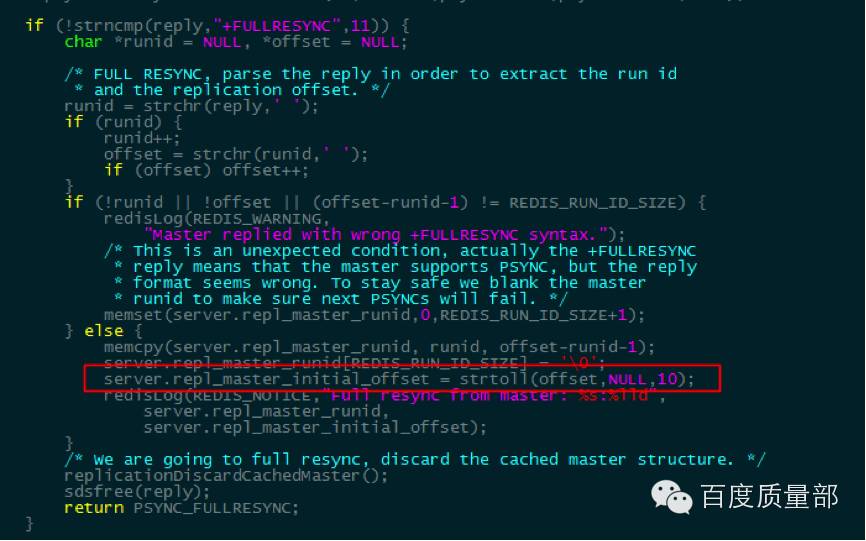
Offset更新:全量同步完成后,主从长连接正常同步时,每次请求offset均自增:

结合offset初始化和更新的代码逻辑,可以推断offset异常由主从全量同步引起,原因如下:
如背景所述,发生问题时主从连接断开,无法进行正常同步,因此不存在正常同步导致offset异常;
正常同步中offset只会比主少,不会比主多。
源码分析
分析redis主处理增量同步的代码逻辑,画出简化的流程图如下:
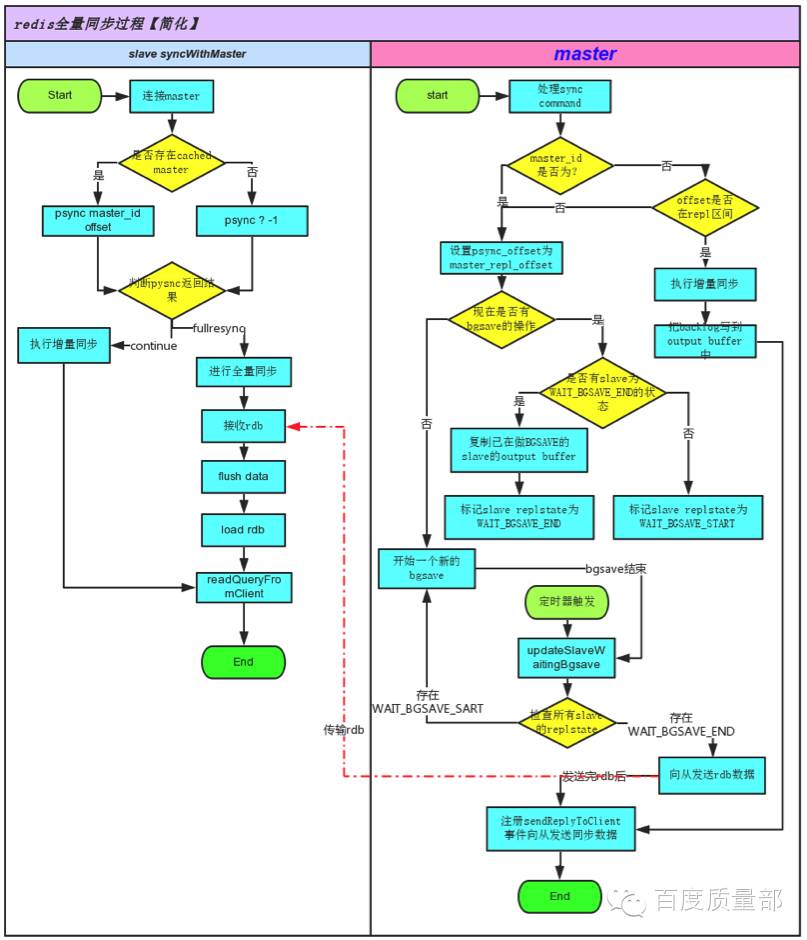
抽出master返回offset逻辑如下:
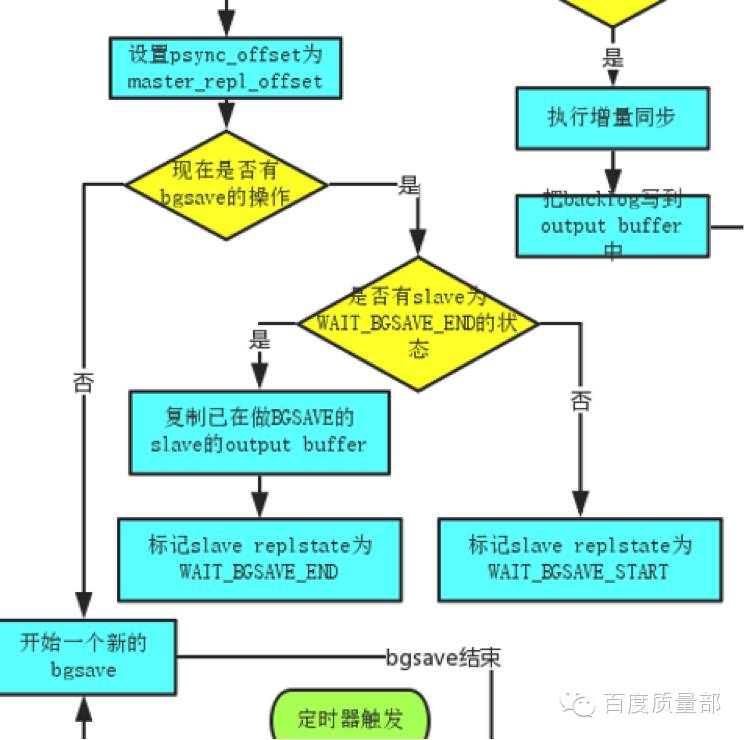
Master会先设置psync_offset(要发给从的offset)为master当前的offset,然后判断是否有在做bgsave操作,如果已经有从在做bgsave,则复制已经在做bgsave的从的outputbuffer(这个buffer会作为dump同步完后的新增数据发送给从)——至此,问题已出现:
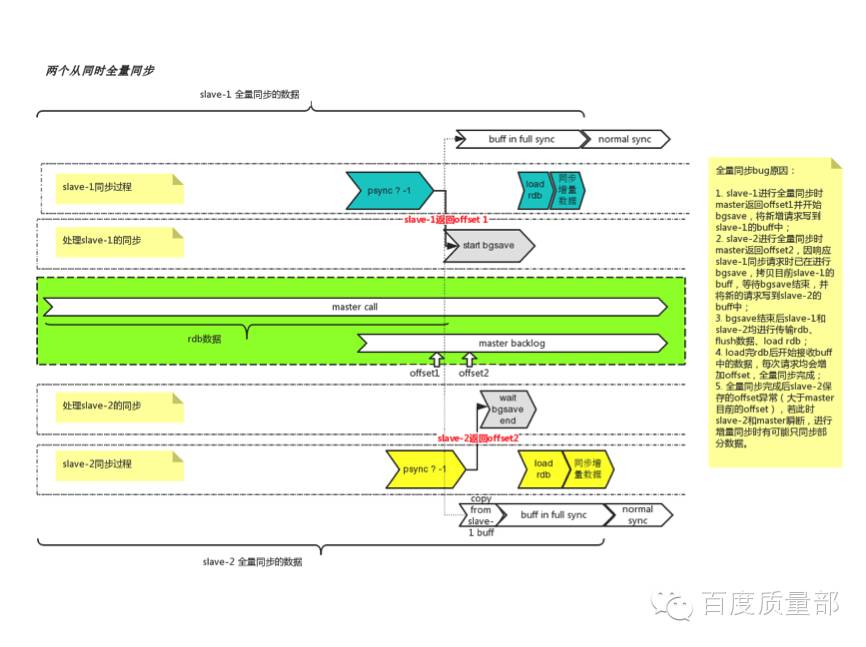
当第一个从进行全量同步时,主将它当前的offseto1返回给从,并且开始做bgsave同时将新增的写请求数据写入第一个从的repl_buffer中,同步完dump数据后,从repl_buffer中发送增量数据,此时o1+增量数据刚好等于master的offset;而在第一个从的bgsave未完成时,若第一个从申请全量同步,则主返回它当前的offset o2(必然比o1大),判断到slave1已在做bgsave,此时不再做bgsave,直接复制s1的repl_buffer到s2的repl_buffer中,并且master新增的数据也开始写到s2的repl_buffer中,同步完dump数据后,从repl_buffer发送增量数据并同步offset。
注意:
此时s1和s2的增量数据完全相同;
o2 > o1;
o1 + 增量数据 = master的offset;
因此从2的offset比主大。
四、问题修复
确定问题后,RD对代码进行了修复:需要做全量同步时,master不再返回当前的offset,而是返回首次做bgsave时保存的offset:

缓存server.fullsync_repl_offset,每次全量同步时返回同样的offset。
五、测试
问题已修复,需要回归测试,测试做CR时仔细核对主从同步过程,发现有如下逻辑:
若第一个从申请全量同步时,主已经在做bgsave(请注意,这里的bgsave是主自动触发的),这时会将从的offset标记为主当前的,并且标记从为WAIT_BGSAVE_START,等待bgsave结束后再次开启bgsave,而这时从的offset比主小。
六、新的问题
这种情况下,若主已在做bgsave:
从请求做全量同步,则主会返回从一个offset o1,并且标记从为WAIT_BGSAVE_START;
等bgsave结束后再次开启bgsave,记此时主的offset为o2,并将主的增量数据写到从的buffer中;
同步完dump的数据后同步增量数据,此时主的offset为o2+增量数据,而从的offset为o1+增量数据;
显然,o1<o2,这就造成同样的数据,从的offset比主小。
事实上,这个问题若出现,将比上一个问题影响更大:从的offset比主小,只要网络瞬断,则从的数据必然异常,并且会重复写一部分数据(o2-o1对应的数据段),造成线上主从数据不一致。
七、修复方案
可幸的是,在我们发现第二个问题后,redis官方给出了这一系列问题的解决方法:https://github.com/antirez/redis/commit/bea1259190a9f3c3850b074ef7d0af0bc3ea36a7
官方的解决方法为:从申请做全量同步时,不再立即返回主的offset,而是放在buffer中作为增量数据发送。
八、总结
这个bug算是隐藏很深的一个超大bug了,在作者修复前,开源社区使用redis的公司应该都或多或少的受到了这个问题的影响。
目前来看,底层服务的这种bug很难发现:
功能测试实在无法覆盖层出不穷的异常场景,redis开源社区已有的自动化case数已达200多项,然而这个bug还是隐藏了很久;
QA和RD没有足够的精力去CR整个服务的代码。
测试中应注意的问题
测试应加大CR力度,对代码足够了解才能写出足够完善的case;
CR时应尽可能分析代码的所有逻辑,避免出现特殊情况;对QA来说,CR不只是阅读代码逻辑,也要检查代码逻辑的问题——CR代码时尽量画出一个流程图(至少大脑里要有一个),之后分析代码逻辑:
检查各个变量的初始化及调用位置,判断是否会有脏值;
检查动态内存的申请和释放位置,判断是否会内存泄漏或者使用野指针;
检查代码分支,不同的分支是否能做正确的响应;
问题定位应注意的问题:
分析bug产生的原因,尽可能详细到变量或者函数;
阅读代码逻辑,查看变量/函数的初始化位置/调用位置或改变位置;
分析变量/函数出错可能的原因,检查对应的代码逻辑;
以上是关于百度QA金BUG集锦之《Redis主从同步失败案例的步步深入》的主要内容,如果未能解决你的问题,请参考以下文章