主从同步延迟导致的数据不一致性分析
Posted 系统工程实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主从同步延迟导致的数据不一致性分析相关的知识,希望对你有一定的参考价值。
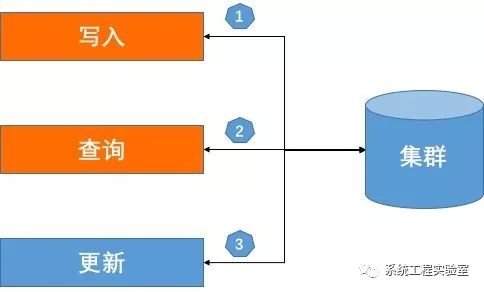
在实际项目中,后端的mysql集群采用主从模式进行读写分离,典型的主从模式如下图所示:
主库:写请求全部打到主库从库:从主库同步数据,并处理所有的读请求通过主从结构部署,可以在MySQL层面实现读写库的分离部署,读库可以独立伸缩,能够极大的提高系统的读性能。主从结构的问题在于主从数据同步存在延时写请求写入主库,新写入数据同步到从库存在一定的延时,即使常规情况下的延时是毫秒级的,但依然会存在主从数据不一致的时间周期。在主库数据未同步到从库之前,读请求会在从库读取到脏数据,由此导致数据不一致。“数据不一致” 不一定会导致业务上的严重问题,要依业务情况具体分析。数据不一致导致问题的条件是:单系统单个请求内的读写依赖
场景:单个系统的同一个请求内,先写库后读库的场景方案:
需要考虑是否真的需要查库,还是所需数据已经存在与内存中?
如果业务场景要求强一致,则业务层查询强制直接读主库。
单系统不同请求间的读写依赖
场景:同一系统的不同请求间的读写依赖,请求2查询请求1更新的数据方案:
业务上是否有强一致性要求,是否能接受最终一致性的延时?如果无强一致性要求,则读从库即可,并在适当延时后达成最终一致。
如果有强一致性要求,因为来自不同请求,在并发量不高的情况下,对特定业务进行读主库的处理。
也可以考虑缓存,在请求一更新数据后同时写入缓存,请求2从缓存拉取数据。
第三方系统间的读写依赖
场景:系统A更新DB后,通过消息中间件发送信号(比如包含数据记录的主键信息)给第三方系统,第三方系统以消息内容的数据主键为参数回调系统A提供的数据拉取接口。该种通信方式的好处是简单,系统A提供数据拉取的信号给第三方系统,第三方通过回调接口拉取最新数据进行数据同步。缺点是上下游相互耦合,存在回调的闭环接口。方案:如果有强一致性要求
如果发量不高的情况下,则查询接口在业务层可以读主库
如果并发量比较高,则系统A可以提供缓存方案
或发送消息除了包含Key之外,至少包含类版本例如更新时间等信息,用于回调接口在查询时可以感知到主从延时问题,并在调用方或被调用方任意一侧进行重试。
如果没有强制性要求
接收延时直接读从库
也可以选择发送全量消息:
在可靠的消息中间件基础之上,为了避免接口回调,系统A可以选择发送全量消息到消息中间件,并保证同一个Key的消息有序,且消息投递成功。第三方系统有序消费消息,并做幂等性处理。
总结处理主从不一致问题的关键原则是:具体情况具体分析。分析在特定的场景下,业务上是否允许出现不一致的情况。例如,如果用户在界面上进行了用户信息的更新操作,随即查询从库出现不一致导致UI展示出现的是旧数据,这种情况是不可接受的,极大影响用户体验。当然这种情况可以通过前端回写最新数据而不需要重新查库来解决。又比如,用户A更改了课程数据,用户B在同一时刻查看数据从进行了从库查询,导致用户B的UI上展示的是旧数据,这种情况下适当的延时可能是能接受的。
以上是关于主从同步延迟导致的数据不一致性分析的主要内容,如果未能解决你的问题,请参考以下文章