Redis系列--主从同步
Posted 奇涛技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis系列--主从同步相关的知识,希望对你有一定的参考价值。
主从同步机制的配置还是比较简单的:在slave节点的redis.conf配置文件中配置slaveof masterip masterport选项或者直接使用slaveof masterip masterport命令(在Redis 5.0版本后,使用replicaof命令),我们还可以配置slave节点的只读性:slave-read-only yes。
需要注意的是:在主从同步模式下,即便master节点宕机了,slave节点也不会变为master节点进行写操作,必须配合哨兵机制或者集群模式来实现高可用,主从同步只是高可用的基础。
以多个数据副本冗余的方式,实现数据的热备份。
避免了单点故障的数据安全问题。
读写分离,负载均衡,提高性能及并发性。
slave节点只归属一个master节点,数据单向流动。
全量同步:也叫快照同步,一般发生在slave节点初始化阶段,或者slave节点与master节点连接断开,重新连接后,有可能需要把master节点的全部数据复制一份。
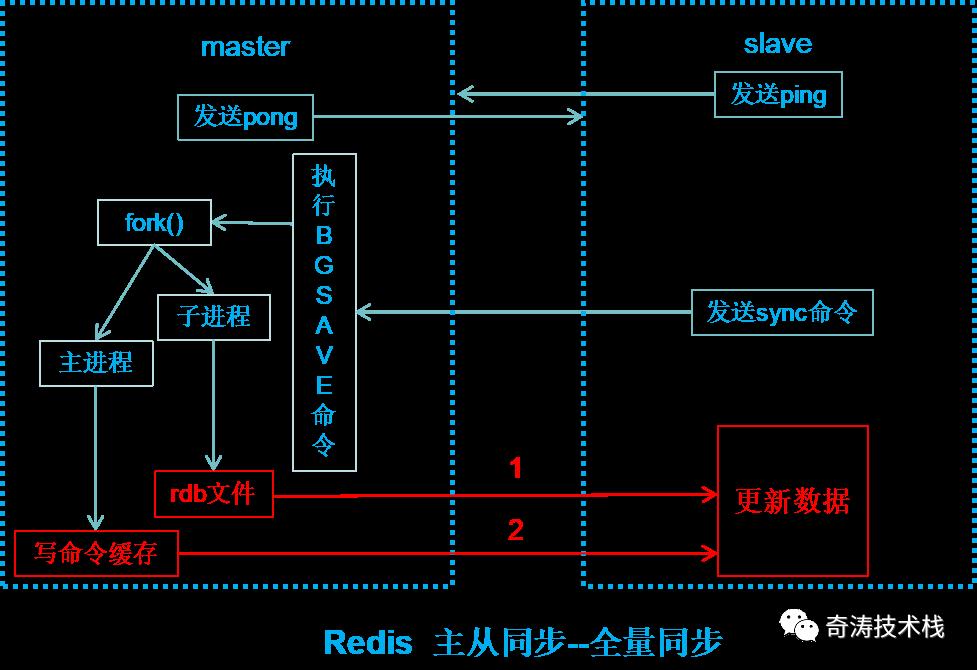
slave向master发送sync命令。
master执行bgsave命令生成rdb文件,并将后续接收到的命令写缓存区。
bgsave执行完毕,master将rdb文件发送给slave,slave载入rdb文件。
master将缓存区的命令发送给slave执行。
命令传播:在完成全量同步后,slave节点就和master节点的状态保持一致了,但是当master节点接收了写命令,状态变为不一致,master节点需要将导致状态不一致的命令发送给slave节点去执行,将状态恢复成一致。
增量同步:在2.8版本之前,slave节点与master节点断线重连后,需要进行全量同步,这种做法是非常低效的,为了解决这个问题,Redis 2.8版本实现了psync命令。
psync命令有两种模式:
完整增量同步(full resynchronization):过程和全量同步基本一致,主要用来完成slave节点的初次数据同步。
部分增量同步(partial resynchronization):主要用在slave与master断线重连后,master将断线期间的写命令发送给slave节点执行,保持状态一致。
增量同步的实现:
组成部分:
复制偏移量offset:master和slave上分别维护一个复制偏移量,通过比对偏移量就可以知道master和slave状态是否一致。
复制缓冲区:由master维护的一个固定长度的FIFO队列,存放写命令,因为长度固定,所以只能存放最近的命令,后入队的命令会将先入队的命令弹出队列。
实例ID:master和slave都有一个运行ID。
实现细节:
master进行命令传播时,除了将写命令发送slave之外,还将写命令放入复制缓冲区。
master每执行一次写命令,就将自己的offest+N,N为写命令占用的字节数,复制缓冲区会为队列上的每个字节记录相应偏移量。
slave每次接收一条写命令,也会将自己的offset+N,N为写命令的字节数。如果master和slave上的offset一致,说明两者状态是一致的,反之则不一致。
当slave断线重连后,发送psync命令,向master报告自己当前的offset,master判断报告的offset是否还在复制缓冲区内,如果在则发起部分增量同步,发送位于offset之后的写命令即可,如果不在,说明命令丢失,发起完整增量同步。
实例ID在节点启动时产生,由40个随机的16进制组成,当slave首次从master复制数据时,master将自己的ID发送给slave,由slave保持;当slave断线重连时,会将自己保存的ID发送给重连接的master,master判断ID与自己的ID是否一致,如果一致,说明master没改变,尝试部分增量同步,如果不一致,说明master已经改变,需要完整增量同步。
复制缓冲区的大小:
复制缓冲区的大小默认为1M,当master执行大量写命令或者slave断线时间较长时都会使队列溢出,从而导致增量同步的无效,因此需要预计和设置复制缓冲区的大小,才能使增量同步发挥作用。
以上是关于Redis系列--主从同步的主要内容,如果未能解决你的问题,请参考以下文章