实战部署Kylin读写分离
Posted 中兴大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战部署Kylin读写分离相关的知识,希望对你有一定的参考价值。
文 | 刘智江
概述
Apache Kylin™由eBay开源,来自中国的Apache顶级开源项目,是一个分布式分析引擎,在Hadoop平台之上实现传统数据仓库、商业智能的能力,使用SQL查询接口提供交互式的多维分析能力,并提供传统数据仓库技术所不能做到的超大规模数据集的快速查询。
Kylin的核心思想是预计算(以空间换时间),即对多维分析可能用到的维度和度量进行预计算,将计算好的结果保存成Cube,供查询时直接访问。把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询,这决定了Kylin能够拥有很好的快速查询和高并发能力。
Kylin非常适合读写分离,原因是Kylin的工作负载有两种:
Cube的计算:调用MapReduce进行批量、延时很长的计算,有密集的CPU和IO资源。
在线的实时查询计算:是只读的操作,要求响应快,延迟低。
社区提供的读写分离架构图如下: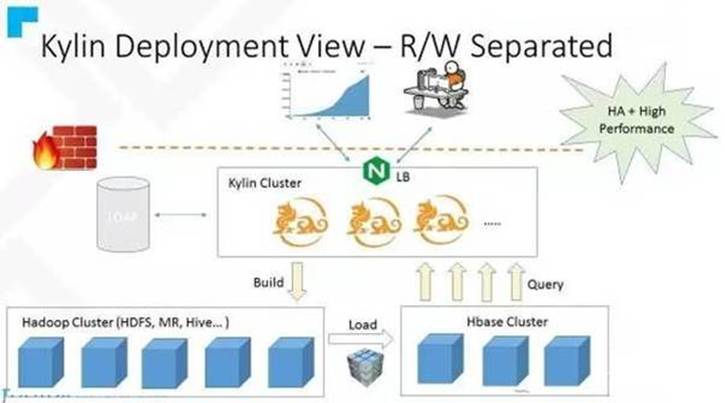
通过架构图可以看到Kylin会访问两个集群的HDFS,建议两个集群的NameService务必不能相同,尤其是集群启用NameNode HA时,相同的NameService会导致组件在跨集群访问HDFS时因无法区分NameService而出现问题。
环境
虚拟机环境:
硬件:内存16GB,CPU分配2核
操作系统: CentOSrelease 6.5
Jdk版本号:1.7.0_55
Ø Apache Hadoop版本号:2.7.3
Apache Hive版本号:2.1.1
Apache HBase版本号:1.1.10
ApacheZookeeper版本号:3.4.9
Apache Kylin版本号:1.6.0
两台主机分别为:
主机名为test23,ip为10.43.156.23
主机名为test24,ip为 10.43.156.24
两台主机分别在/etc/hosts文件中配置对方的主机名和ip,根据主机名可互访。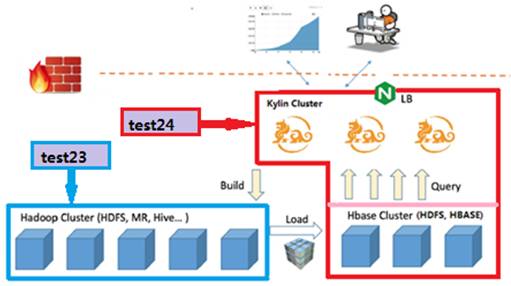
本案作为功能验证,使用2台虚拟机分别搭建两个Hadoop环境当做Hadoop集群,一个集群部署HDFS、Hive、MR、YARN作为计算集群,负责Cube构建。一个集群部署HDFS、YARN、HBase负责Cube存储。
test23为计算集群,安装HDFS、MR、Hive、YARN,HDFS的dfs.nameservices设置为ns23。
test24为存储集群,安装HDFS、YARN、HBase,HDFS的dfs.nameservices设置为ns24。
部署
1. 在test23上部署Hadoop(MapReduce计算集群,以下简称计算)集群,在test24单部署HBase(HDFS存储,以下简称存储)集群和Kylin,部署过程略。安装完毕后,需要验证除Kylin外各组件功能正常,其中计算集群必须启用JobHistoryServer进程。
本例中test23启动集群后,进程如下:
test24启动集群后,进程如下:
安装完毕后的目录结构图,本案使用MR用户安装组件到/home/mr目录下。
test23主机目录结构:
test24主机目录结构:
test24主机上的Hive作为客户端,不需要启动服务进程。
2. 在test24服务器(存储集群)上,配置Hadoop(计算)集群的客户端配置文件。考虑到Kylin和存储集群部署合设,需要将计算集群的客户端配置文件单独存放到目录/home/mr/myetc中从而剔除计算集群客户端配置文件对存储集群的影响, 通过设置配置文件路径的环境变量来控制Kylin读取配置客户端配置文件的路径。
通过env.sh脚本实现重置环境变量的过程,脚本内容如下:
[mr@test24 myetc]$ cat env.sh
export HBASE_CONF_DIR=/home/mr/myetc
export HADOOP_CONF_DIR=/home/mr/myetc
export HIVE_CONF_DIR=/home/mr/myetc
export HIVE_CONF=$HIVE_CONF_DIR
export HCAT_HOME=/home/mr/hive-2.1.1/hcatalog
export HBASE_CLASSPATH=$HBASE_CONF_DIR
客户端配置文件列表如下: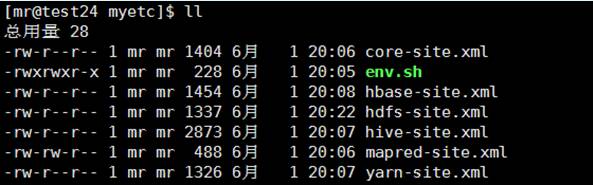
下面对配置文件做简要说明:
Kylin是通过HBase脚本进行加载,在Kylin运行时获取到的相关环境变量是通过HBase脚本传入,如果期望在Kylin提交作业到计算集群以及访问计算集群的Hive,需要修改HBase客户端配置中的core-site.xml,将默认dfs指向计算集群,同时需要修改hdfs-site.xml,使其能解析计算集群和存储集群的NameService。
core-site.xml为计算集群的配置文件,defaultFs指向计算集群的HDFS,便于Hive使用。如果两个集群中的本地路径不一致,需要手工修改该配置文件,将其与存储集群保持一致。
hbase-site.xml使用存储集群的配置,从test24的/home/mr/hbase-1.1.10/conf目录拷贝。
hive-site.xml使用计算集群的配置,从计算集群test23拷贝,需要注意按照test24中的目录修改hive-site.xml 中涉及本地路径的配置项,并在test24中创建对应的路径及赋予访问权限。
mpared-site.xml和yarn-site.xml使用计算集群的配置,直接从计算集群test23的/home/mr/hadoop-2.7.3/etc/hadoop中拷贝,如有涉及到本地文件的配置项,需要一并按照存储集群的目录进行修改。
hdfs-site.xml这个文件比较特殊,如果在两个集群中的组件访问HDFS时的url都配置的是主机名+端口的方式,只需要将计算集群的配置文件拷贝到存储集群即可,如有涉及到本地文件的配置项,需要一并按照存储集群的目录进行修改。
如果组件使用NameService进行访问需要进行文件合并,保证Kylin可以正确的使用存储集群或计算集群的NameService名称访问HDFS。
合并的方法是将存储集群中的NameService加入到集群集群客户端配置文件hdfs-site.xml的dfs.nameservices配置项中,并增加对NameService的解析,包括dfs.ha.namenodes、dfs.namenode.rpc-address、dfs.namenode.http-address、dfs.ha.automatic-failover.enabled、dfs.client.failover.proxy.provider等参数。
验证Hadoop ,HDFS , Hive ,mapred,YARN等命令可以访问计算集群test23上的服务和资源。
设置环境变量:
[mr@test24 myetc]$ source env.sh
在test24上测试HDFS命令,目录结构为test23上的资源:
[mr@test24 myetc]$ hdfs dfs -ls /
Found 5 items
drwxr-xr-x - mr supergroup 0 2017-05-31 16:38 /hbase
drwx-wx-wx - mr supergroup 0 2017-06-01 19:57 /hive
drwxr-xr-x - mr supergroup 0 2017-06-01 20:34 /kylin
drwx------ - mr supergroup 0 2017-06-01 21:52 /tmp
drwx-wx-wx - mr supergroup 0 2017-06-01 09:57 /user
在test24上测试Hive命令,目录结构为test23上的资源:
hive> show databases;
OK
default
test
Time taken: 1.036 seconds, Fetched: 2 row(s)
在test24上测试mapred命令,节点显示为test23上的资源:
[mr@test24 myetc]$ mapred queue –list

在test24上测试YARN命令,节点显示为test23上的资源:
验证HBase命令可以访问存储集群test24上的服务和资源。
设置环境变量:
[mr@test24 myetc]$ source env.sh
在test24上测试HBase命令,list命令执行成功,无异常:
[mr@test24 myetc]$ hbase shell
hbase(main):001:0> list
TABLE
0 row(s) in 0.1080 seconds
3. 配置Kylin参数。修改test24上Kylin的配置文件/home/mr/kylin-1.6.0/conf/kylin.properties,设置 kylin.hbase.cluster.fs 为HBase集群HDFS的url。本例为kylin.hbase.cluster.fs=hdfs://test24:9000
4. 在test24上重启Kylin服务实例:
[mr@test24 bin]$ source /home/mr/myetc/env.sh
[mr@test24 bin]$ cd /home/mr/kylin-1.6.0/bin
[mr@test24 bin]$ ./kylin.sh stop
[mr@test24 bin]$ ./kylin.sh start
验证
执行sample.sh脚本插入测试数据:
[mr@test24 bin]$ cd /home/mr/kylin-1.6.0/bin
[mr@test24 bin]$ ./sample.sh
使用http://10.43.156.24:7070/kylin访问Kylin的WebUI,在System菜单中重新加载元数据:
在Model中选择kylin_sales_cube构建Cube,可以在test23上查看到MR作业已运行: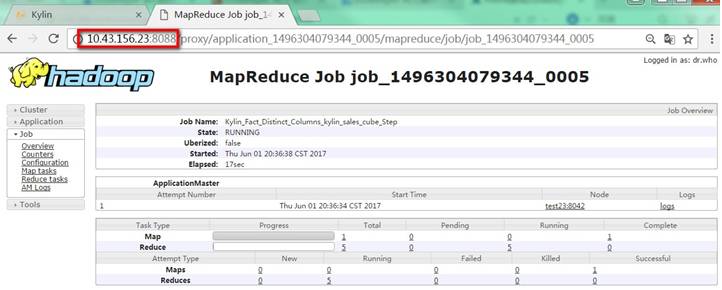
Cube构建成功: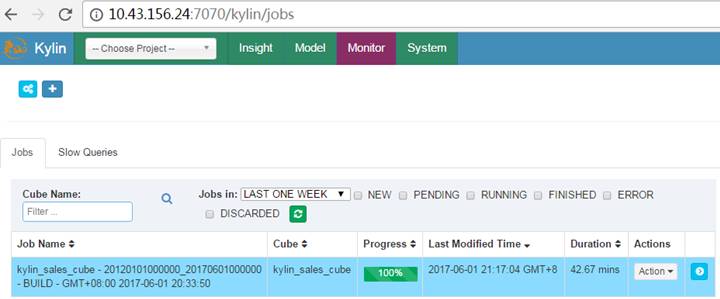
验证原始数据存储在test23的集群中:
验证Cube存储在test24的集群中: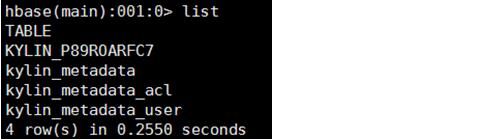
Kylin通过test23计算集群存储Hive数据及进行MR计算,通过test24存储集群在HBase中存储Cube,读写分离验证成功。
扩展阅读:
长按二维码关注
以上是关于实战部署Kylin读写分离的主要内容,如果未能解决你的问题,请参考以下文章