SAP Hybris电商系统与阿里云联合测试系列十读写分离
Posted 架构与技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SAP Hybris电商系统与阿里云联合测试系列十读写分离相关的知识,希望对你有一定的参考价值。
关系型数据库Scalability一直是互联网和电商应用的难点,分库分表与读写分离成为架构师们手中的利器,实现方式通常有下面两种:代理模式和应用直连模式。
Hybris内置支持应用直连方式的读写分离,无须借助第三方中间件就可以实现读写分离(详见数据库可扩展性预研文档 https://github.com/colorzhang/hybris)
读写分离架构
在对数据库有少量写请求,但有大量的读请求的应用场景下,单个实例可能无法抵抗读取压力,甚至对主业务产生影响。为了实现读取能力的弹性扩展,分担数据库压力,RDS 支持在某个地域中创建一个或多个只读实例,利用只读实例满足大量的数据库读取需求,以此增加应用的吞吐量。(需要应用支持读写分离)
读写分离是Scale out Read的常见方式,如下图所示:
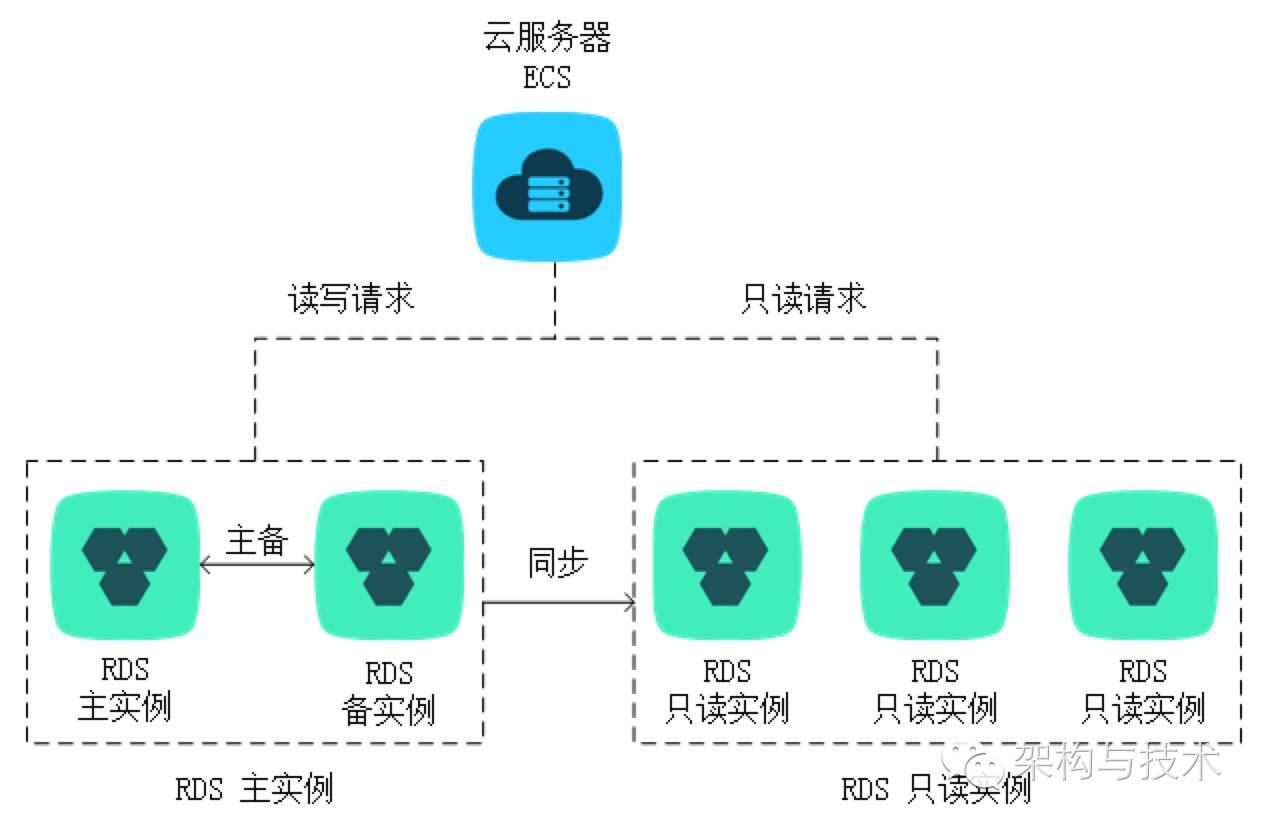
只读实例为单个物理节点的架构(没有备节点),采用 mysql 的原生复制功能,将主实例的更改同步到所有只读实例。
读写分离主要功能
读写分离通常具有如下功能,请勿与Hybris提供的功能一一对照:)
Feature list:
All transactional db call, go master (can force to slave) 强读走写
All non-transaction db call, go slave (can force to master) 弱读走读
Always master (numseries generator) 强制走写
Always slave 强制走读
Round robin balance slave
Delay and retry interval
If slave down, switch to master automatically
If master down, fail
Can specific which tables are splitting (inclusive or exclusive)
Supports all databases 支持所有hybris支持的数据库(Oracle, MySQL, SQL Server, HANA)
本次测试在阿里云上构建RDS-mysql主从部署如下:
配置Hybris启用读写分离
1)设置主从数据源(可以一主多从,本次测试是一主一从)
2)启用读写分离Filter
测试结果与分析
读写分离流量切割与应用密切相关,有些操作是不允许读写分离的比如序列生成器等,我的测试场景主要是浏览前端页面,在点击过程中读写分离流量比例能达到5:1(有一些背景SQL执行),总体流量接近1:1(按执行SQL数量计算)
潜在问题及对策
1)延迟问题,目前测试环境数据量和压力很小,利用率和延迟很小。
2)RDS目前限制,其实也是优势->简单
只读实例有以下功能限制:
1 个主实例做多可以创建 5 个只读实例
备份设置:不支持备份设置以及临时备份
数据迁移:不支持数据迁移至只读实例
数据库管理:不支持创建和删除数据库
账号管理:不支持创建和删除账号,不支持为账号授权以及修改账号密码功能
实例恢复:不支持通过备份文件或任意时间点创建临时实例,不支持通过备份集覆盖实例
创建只读实例后,主实例将不支持通过备份集直接覆盖实例来恢复数据
重要的事情说三遍:RDS使用真简单,真方便,上云后DBA要失业了!!!
本篇是Hybris@AliCloud测试号外,大部分场景已经测试完了,突发奇想测试一下云上读写分离,于是乎半天时间搞定后,就有了今天这篇文章。
顺带公开我的测试站点 https://hybris.space/yacceleratorstorefront/ 请勿搞破坏:)
周末愉快!
以上是关于SAP Hybris电商系统与阿里云联合测试系列十读写分离的主要内容,如果未能解决你的问题,请参考以下文章
SAP 电商云 Spartacus UI SSR 单元测试里的 callFake