从零开始写简易读写分离,不难嘛!
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始写简易读写分离,不难嘛!相关的知识,希望对你有一定的参考价值。
#点击图片进入报名#
最近在学习Spring boot,写了个读写分离。并未照搬网文,而是独立思考后的成果,写完以后发现从零开始写读写分离并不难!
我最初的想法是: 读方法走读库,写方法走写库(一般是主库),保证在Spring提交事务之前确定数据源.
保证在Spring提交事务之前确定数据源,这个简单,利用AOP写个切换数据源的切面,让他的优先级高于Spring事务切面的优先级。至于读,写方法的区分可以用2个注解。
但是如何切换数据库呢? 我完全不知道!多年经验告诉我
当完全不了解一个技术时,先搜索学习必要知识,之后再动手尝试。
--温安适 20180309
我搜索了一些网文,发现都提到了一个AbstractRoutingDataSource类。查看源码注释如下
/**
Abstract {@link javax.sql.DataSource} implementation that routes {@link #getConnection()}
* calls to one of various target DataSources based on a lookup key. The latter is usually
* (but not necessarily) determined through some thread-bound transaction context.
*
* @author Juergen Hoeller
* @since 2.0.1
* @see #setTargetDataSources
* @see #setDefaultTargetDataSource
* @see #determineCurrentLookupKey()
*/
AbstractRoutingDataSource就是DataSource的抽象,基于lookup key的方式在多个数据库中进行切换。重点关注setTargetDataSources,setDefaultTargetDataSource,determineCurrentLookupKey三个方法。那么AbstractRoutingDataSource就是Spring读写分离的关键了。
仔细阅读了三个方法,基本上跟方法名的意思一致。setTargetDataSources设置备选的数据源集合。 setDefaultTargetDataSource设置默认数据源,determineCurrentLookupKey决定当前数据源的对应的key。
但是我很好奇这3个方法都没有包含切换数据库的逻辑啊!我仔细阅读源码发现一个方法,determineTargetDataSource方法,其实它才是获取数据源的实现。源码如下:
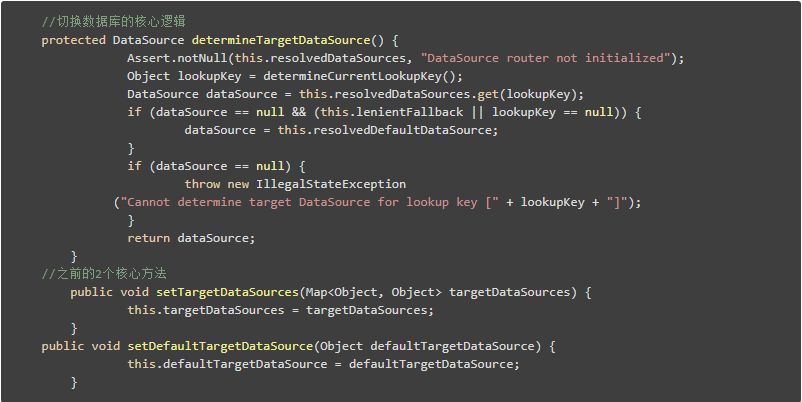
简单说就是,根据determineCurrentLookupKey获取的key,在resolvedDataSources这个Map中查找对应的datasource!,注意determineTargetDataSource方法竟然不使用的targetDataSources!
那一定存在resolvedDataSources与targetDataSources的对应关系。我接着翻阅代码,发现一个afterPropertiesSet方法(Spring源码中InitializingBean接口中的方法),这个方法将targetDataSources的值赋予了resolvedDataSources。
源码如下:
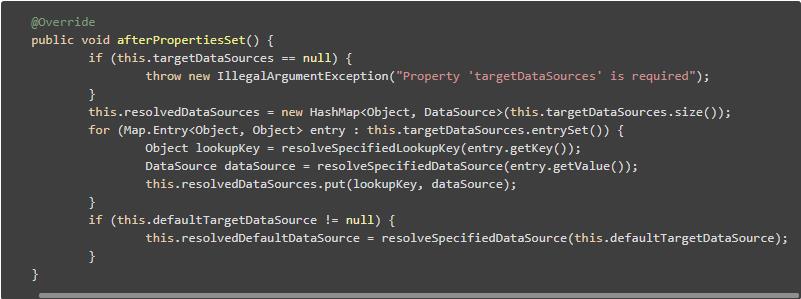
afterPropertiesSet 方法,熟悉Spring的都知道,它在bean实例已经创建好,且属性值和依赖的其他bean实例都已经注入以后执行。
也就是说调用,targetDataSources,defaultTargetDataSource的赋值一定要在afterPropertiesSet前边执行。
AbstractRoutingDataSource简单总结:
AbstractRoutingDataSource,内部有一个Map<Object,DataSource>的域resolvedDataSources
determineTargetDataSource方法通过determineCurrentLookupKey方法获得key,进而从map中取得对应的DataSource。
setTargetDataSources 设置 targetDataSources
setDefaultTargetDataSource 设置 defaultTargetDataSource,
targetDataSources和defaultTargetDataSource 在afterPropertiesSet分别转换为resolvedDataSources和resolvedDefaultDataSource。
targetDataSources,defaultTargetDataSource的赋值一定要在afterPropertiesSet前边执行。
进一步了解理论后,读写分离的方式则基本上出现在眼前了。(“下列方法不唯一”)
先写一个类继承AbstractRoutingDataSource,实现determineCurrentLookupKey方法,和afterPropertiesSet方法。afterPropertiesSet方法中调用setDefaultTargetDataSource和setTargetDataSources方法之后调用super.afterPropertiesSet。
之后定义一个切面在事务切面之前执行,确定真实数据源对应的key。但是这又出现了一个问题,如何线程安全的情况下传递每个线程独立的key呢?没错使用ThreadLocal传递真实数据源对应的key。
ThreadLocal,Thread的局部变量,确保每一个线程都维护变量的一个副本
到这里基本逻辑就想通了,之后就是写了。
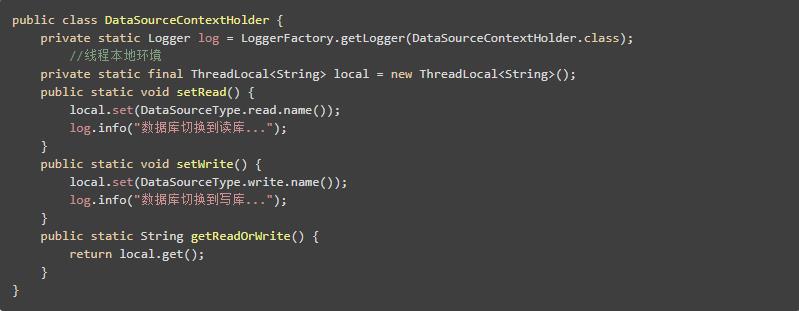
DataSourceContextHolder 使用ThreadLocal存储真实数据源对应的key
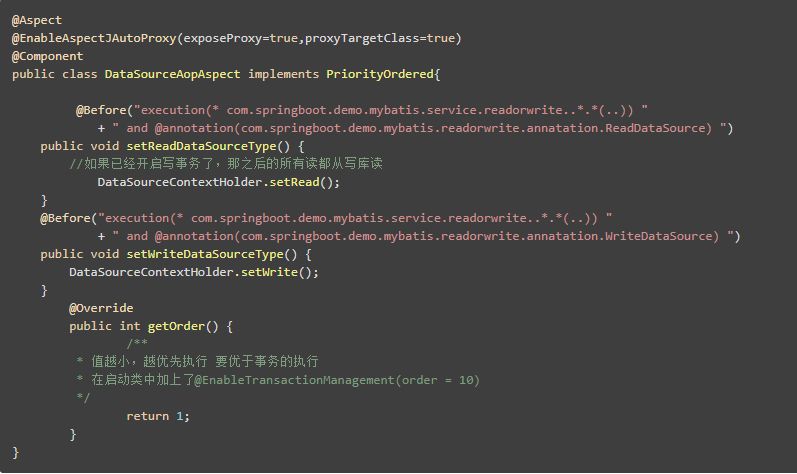
DataSourceAopAspect 切面切换真实数据源对应的key,并设置优先级保证高于事务切面
RoutingDataSouceImpl实现AbstractRoutingDataSource的逻辑
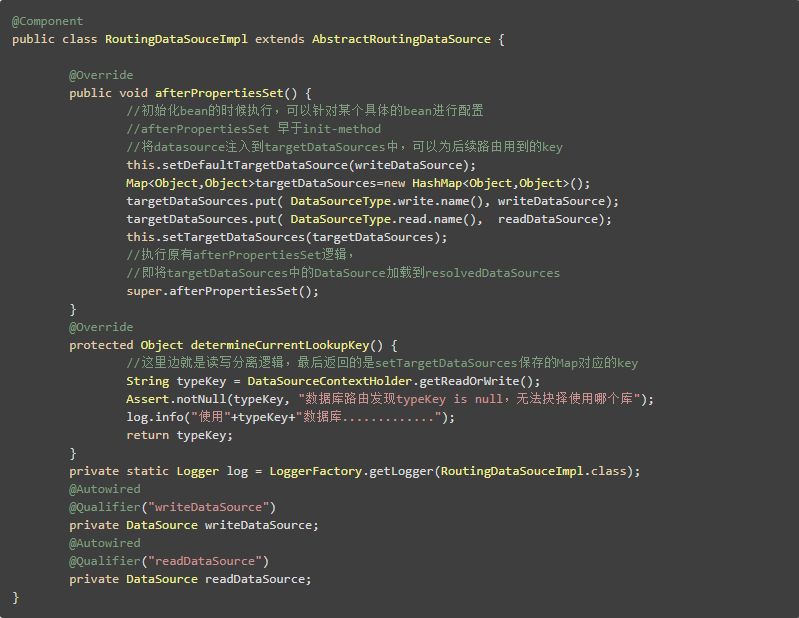
基本逻辑实现完毕了就进行,通用设置,设置数据源,事务,SqlSessionFactory等
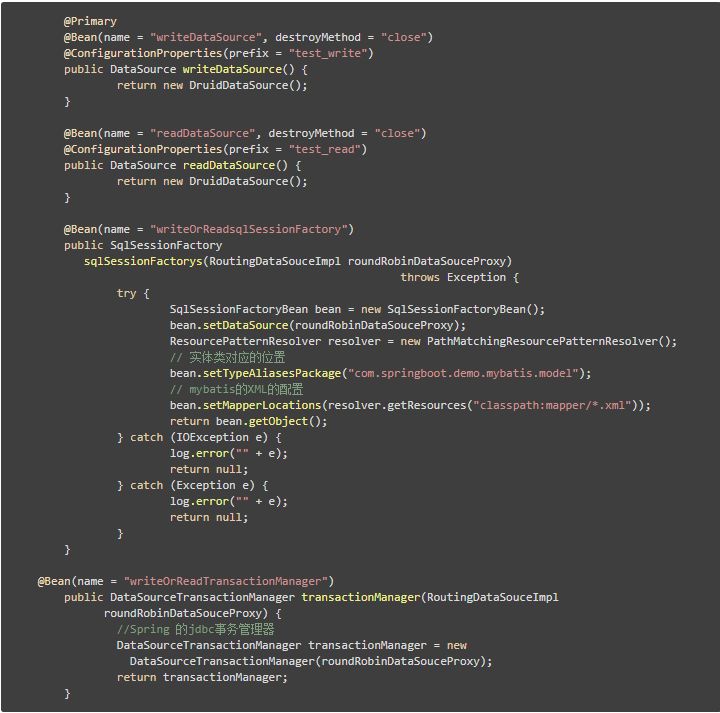
其他代码,就不在这里赘述了,有兴趣可以移步完整代码。
使用Spring写读写分离,其核心就是AbstractRoutingDataSource,源码不难,读懂之后,写个读写分离就简单了!。
AbstractRoutingDataSource重点回顾:
AbstractRoutingDataSource,内部有一个Map<Object,DataSource>的域resolvedDataSources
determineTargetDataSource方法通过determineCurrentLookupKey方法获得key,进而从map中取得对应的DataSource。
setTargetDataSources 设置 targetDataSources
setDefaultTargetDataSource 设置 defaultTargetDataSource,
targetDataSources和defaultTargetDataSource 在afterPropertiesSet分别转换为resolvedDataSources和resolvedDefaultDataSource。
targetDataSources,defaultTargetDataSource的赋值一定要在afterPropertiesSet前边执行。
这周确实有点忙,周五花费了些时间不过总算实现了自己的诺言。
完成承诺不容易,喜欢您就点个赞!

以上是关于从零开始写简易读写分离,不难嘛!的主要内容,如果未能解决你的问题,请参考以下文章