阿里面试,为什么Kafka不支持读写分离
Posted 占小狼的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里面试,为什么Kafka不支持读写分离相关的知识,希望对你有一定的参考价值。
还在加班,收到一个小伙伴的吐槽:狼哥,阿里的面试太变态了,我只是在工作中用过kafka,然后简历上提了下,就被抓着一个劲的问,一些基础的问题,我还可以勉强答出来,但是问到“为什么Kafka不支持读写分离”,我就懵逼了。
说实话,这个狼哥也不知道,对于kafka,我也只会生产、消费。

一直没有接触过kafka相关的知识,为了拓展一下技术广度,找到了我厮大
为什么数据库、redis都支持了读写分离功能,而kafka却没有?
厮大也是狠人,直接打开源码从头开始讲,我一看这情况不对,按照这进度得讲到天黑了,蹭着厮大上厕所的空隙,我呲溜跑了~~~

厮大估计见我已经呲溜了,第二天就甩我一篇文章,还是热乎的,文末还有精华
从代码层面上来说,在 Kafka 中完全可以支持这种功能,但是会大大增加代码的复杂度,所以我们要从“收益点”这个角度来做具体分析。主写从读可以让从节点去分担主节 点的负载压力,预防主节点负载过重而从节点却空闲的情况发生。但是主写从读也有 2 个很明 显的缺点:
数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
延时问题。类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经 历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历网络→主节点内存→主节点磁盘→网络→从节 点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
现实情况下,很多应用既可以忍受一定程度上的延时,也可以忍受一段时间内的数据不一 致的情况,那么对于这种情况,Kafka 是否有必要支持主写从读的功能呢?
主写从读可以均摊一定的负载却不能做到完全的负载均衡,比如对于数据写压力很大而读 压力很小的情况,从节点只能分摊很少的负载压力,而绝大多数压力还是在主节点上。而在 Kafka 中却可以达到很大程度上的负载均衡,而且这种均衡是在主写主读的架构上实现的。我们来看 一下 Kafka 的生产消费模型,如下图所示。
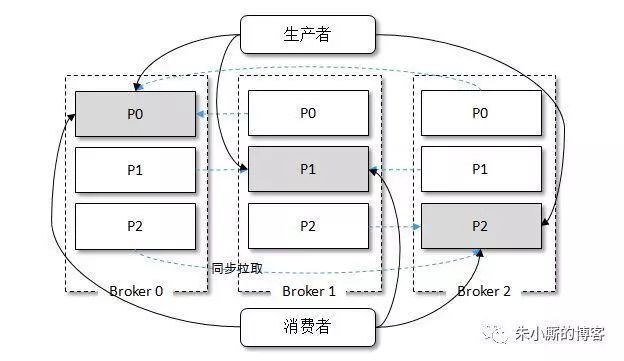
在 Kafka 集群中有 3 个分区,每个分区有 3 个副本,正好均匀地分布在 3个 broker 上,灰色阴影的代表 leader 副本,非灰色阴影的代表 follower 副本,虚线表示 follower 副本从 leader 副本上拉取消息。当生产者写入消息的时候都写入 leader 副本,对于图 8-23 中的 情形,每个 broker 都有消息从生产者流入;当消费者读取消息的时候也是从 leader 副本中读取 的,对于图 8-23 中的情形,每个 broker 都有消息流出到消费者。
我们很明显地可以看出,每个 broker 上的读写负载都是一样的,这就说明 Kafka 可以通过 主写主读实现主写从读实现不了的负载均衡。上图展示是一种理想的部署情况,有以下几种 情况(包含但不仅限于)会造成一定程度上的负载不均衡:
broker 端的分区分配不均。当创建主题的时候可能会出现某些 broker 分配到的分区数 多而其他 broker 分配到的分区数少,那么自然而然地分配到的 leader 副本也就不均。
生产者写入消息不均。生产者可能只对某些 broker 中的 leader 副本进行大量的写入操 作,而对其他 broker 中的 leader 副本不闻不问。
消费者消费消息不均。消费者可能只对某些 broker 中的 leader 副本进行大量的拉取操 作,而对其他 broker 中的 leader 副本不闻不问。
leader 副本的切换不均。在实际应用中可能会由于 broker 宕机而造成主从副本的切换, 或者分区副本的重分配等,这些动作都有可能造成各个 broker 中 leader 副本的分配不均。
对此,我们可以做一些防范措施。针对第一种情况,在主题创建的时候尽可能使分区分配 得均衡,好在 Kafka 中相应的分配算法也是在极力地追求这一目标,如果是开发人员自定义的 分配,则需要注意这方面的内容。对于第二和第三种情况,主写从读也无法解决。对于第四种 情况,Kafka 提供了优先副本的选举来达到 leader 副本的均衡,与此同时,也可以配合相应的 监控、告警和运维平台来实现均衡的优化。
所以,从某种意义上来说,主写从读是由于设计上的缺陷而形成的权宜之计。
昨天,厮大打磨2月的电子版悄然上线——“图解 Kafka系列”,其内容源自《深入理解Kafka》一书,相当于此书的电子版,内容基本一致,只是在内容编排上做了一定的修改,目前新上还打8折更便宜,扫码下方二维码即可。
以上是关于阿里面试,为什么Kafka不支持读写分离的主要内容,如果未能解决你的问题,请参考以下文章