推荐系统丨YouTube召回模型设计
Posted 脚本之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统丨YouTube召回模型设计相关的知识,希望对你有一定的参考价值。
脚本之家
你与百万开发者在一起


来源 | 博文视点 | 文末赠书
随着互联网行业的高速发展,人们获取信息的方式越来越多。人们对信息获取的有效性和针对性的需求随之出现,推荐系统也应运而生。推荐系统就是互联网时代的一种信息检索工具,推荐系统的任务就是连接用户和信息,创造价值。

YouTube是世界上最大的生产、分享、发现视频内容的平台。2016 年,YouTube 用深度神经网络完成了工业级的视频推荐系统,这帮助了10 亿多用户从不断增大的视频集中发现个性化的视频内容。
在推荐系统中,由于待推荐的物品数量非常巨大,推荐系统不可能对所有物品进行模型预估,因此需要使用召回方法,以便高效地从海量物品中筛选出一小部分符合要求的物品(耗时不超过50ms或者100ms)。
本文选自《推荐系统算法实践》,本文向大家介绍了YouTube 的召回模型,让我们一同看看它是如何实现实现从百万个视频中筛选出一小部分视频的。

要想了解YouTube的召回模型,需要依次掌握召回算法、召回模型网络结构,以及召回特征和样本设计。

为了生成候选集,需要从视频语料库中选出与用户相关的视频,可以将其看成一个极多分类问题(extreme multiclass classification problem)。
基于特定的用户U 和上下文C ,在时刻t 将指定的视频Wt 准确地划分到第i 类中,其中 (V 表示视频语料库),极多分类就是Softmax分类,公式如下:
(V 表示视频语料库),极多分类就是Softmax分类,公式如下:
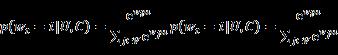
其中,用户向量u是由用户观看和搜索视频记录进行Embedding,再和上下文以及用户的其他特征组合而成的一个向量。
vju表示第j个视频的Embedding向量,这里每个视频都Embedding成一个向量。
假设存在百万个类别,训练这样的极多分类问题时会显得异常困难,需要对Softmax多分类问题进行优化加速。其解决方法采用负类采样(sample negative classes),通过采样找到数千个负类,将多分类问题变成二元分类问题,如此一来运行速度大大提升。

在Word2vec语言模型(CBOW)中,我们将各个词Embedding编码到一个向量,并将词的Embedding向量喂给前馈神经网络进行学习。受此方法启发,我们将每个视频都映射(Embedding)到一个向量,并且将视频的Embedding向量喂给神经网络,其中神经网络的输入需要为固定大小的向量。我们可以简单地将用户观看过的所有视频ID的Embedding做聚合操作(最大、最小、平均、累加等),其中平均操作的效果最好。
另外,视频的Embedding向量也可以通过正常的梯度下降反向传播更新与所有其他模型参数一同学习。召回模型的网络结构如下图所示。
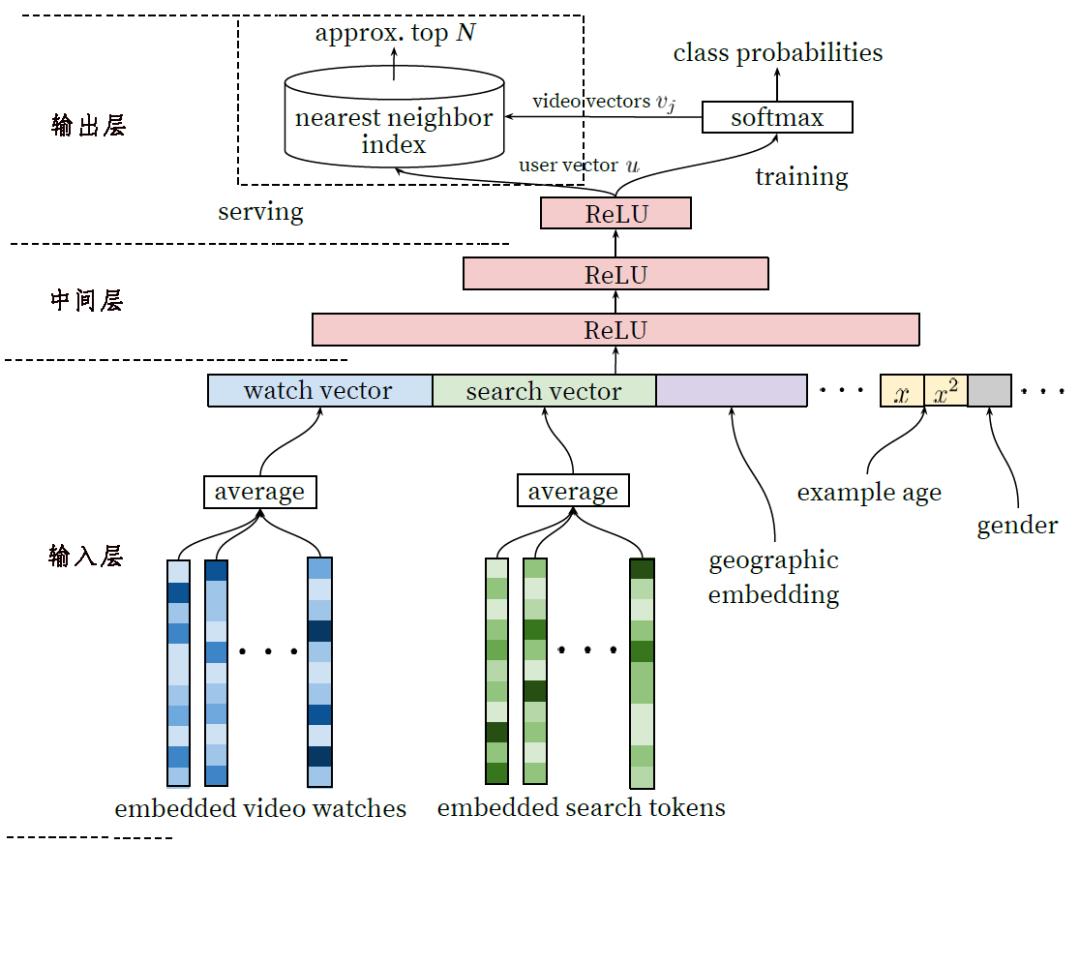
YouTube召回模型的网络结构包含多层神经网络:输入层、中间层(多层网络)、输出层。接下来对各层神经网络进行详细介绍。
▊ 输入层
在该网络结构中,输入数据都是一些异构数据,包括:
● 用户观看视频序列ID:对视频ID的Embedding向量进行累计并求平均值,得到观看向量(watch vector)。
● 用户搜索视频序列ID:对视频ID的Embedding向量进行累计并求平均值,得到搜索向量(search vector)。
● 用户地理特征和用户设备特征:均为一些离散特征。可以采用Embedding方法或者直接采用OneHot方法(当离散的维度比较小时),得到用户的地理向量(geographic embedding)和设备向量。
● 人口属性特征:可进行归一化处理。其中,人口统计特征(如example age、gender)可以提供丰富的先验信息,以实现比较好的对新用户的推荐效果。
▊ 中间层
中间层包括两层,其中每一层的激活函数为ReLU。
▊ 输出层
输出层的维度和视频ID的Embedding维度一致,最终得到用户向量u。
通过该网络结构的学习,最终可以得到所有视频的Embedding向量V,其维度为pool_size×k,其中pool_size为训练集视频资源池大小,k为Embedding的维度。我们还可以得到所有用户的输出向量u,其中每个用户向量的维度是k维,和物品的Embedding维度一致。
在线服务阶段,通过视频向量V和用户向量u,进行相似度计算,采用最近邻查询,取得Top相似视频作为召回候选集。

接下来介绍召回模型输入层的特征处理,以及如何进行样本的设计和如何选择模型参数。
▊ 异构信息处理
包括如下内容。
● 视频ID向量化:基于此向量,可以得到用户的曝光视频向量、观看视频向量、搜索视频向量等(得到用户的各种视频行为向量)。
● 用户画像特征归一化处理:如地理位置、设备、性别、年龄、登录状态等连续或离散特征都被归一化为[0,1],并和用户视频行为向量做连接(concat)。
● example age(视频生命周期特征):该特征表示视频被上传之后的时间。在YouTube上,每秒都有大量视频被上传。推荐这些最新视频对于YouTube来说是极其重要的。通过持续观察,可知用户更倾向于被推荐那些尽管相关度不高但却为最新的视频。推荐系统往往会利用用户过去的行为预测未来。对于历史行为,推荐系统通常能够学习到一种隐式的基准。但是这对于视频的流行度分布往往是高度不稳定的。为了解决这个问题,这里的推荐策略是,将example age作为一个特征拼接到DNN的输入向量,在训练时,时间窗口越靠后,该值越接近于0或者一个绝对值小的负数。加入example age特征后,模型效果和观测到的实际数据更加逼近,参见下图。
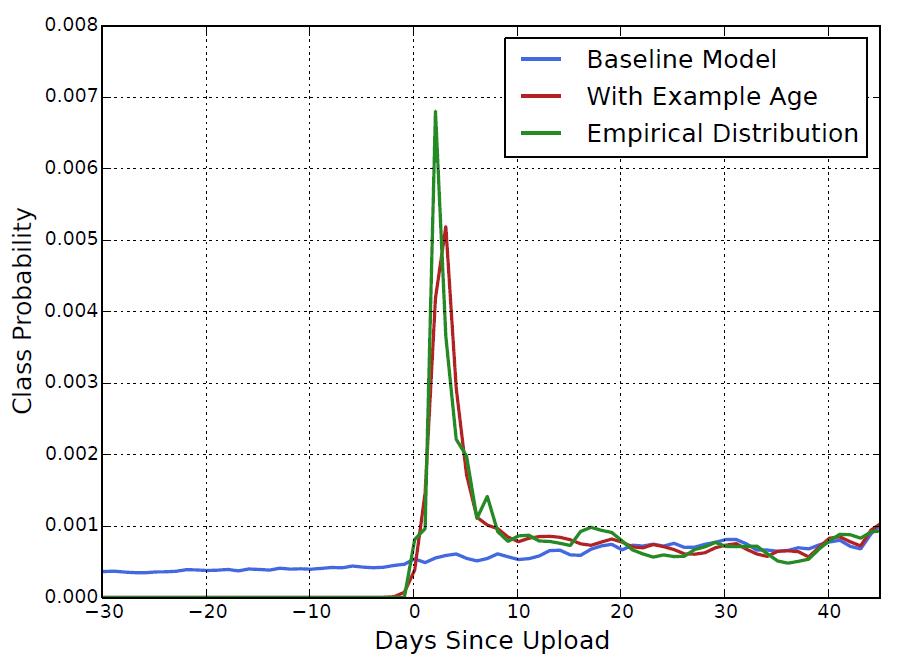
加入example age特征后的效果示例
这里在训练时将训练样本的example age值作为一个特征进行训练学习;而在线上进行在线推荐服务时,会将example age这个特征值设置为0(或绝对值比较小的负数),以反映模型正在训练窗口的末端进行预测。
▊ 样本选择和上下文选择
包括如下两项内容。
 上下文选择对比效果示例
上下文选择对比效果示例
▊ 神经网络深度参数选择
通过增加特征数量和神经网络的深度,可以显著提高准确性,如下图所示。
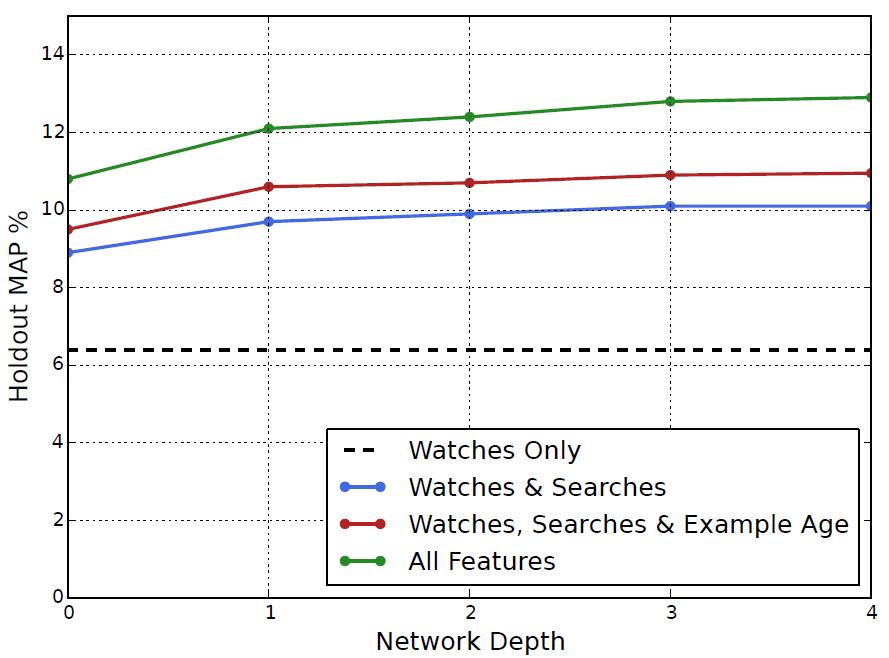
神经网络深度参数对比示例
在上图的实验中,总共有数以百万计的视频和搜索词汇,我们取最多50个观看视频和50个最近搜索视频,映射成256维的float数组。最后一层网络的输出是一个256维的向量,其中最后的输出结果会通过一个Softmax函数,计算得到1MB视频的得分,即分类结果。模型基于所有YouTube用户数据进行训练,直至收敛。网络结构呈一个常见的塔状,底部的网络最宽,每往上一层节点数就减半。深度为0的网络和之前的推荐系统非常相似,是一个高效的线性分解模型。
● 深度为0:这时网络会把连接起来的输入层转换一下,和Softmax的256维输出对应起来。
● 深度为1:第一层为256个节点,激活函数是ReLU。
● 深度为2:第一层为512个节点,第二层为256个节点,激活函数都是ReLU。
● 深度为3:第一层为1024个节点,第二层为512个节点,第三层为256个节点,激活函数都是ReLU。




在本文下方留言,发表您在学习过程中的经验感想,机会总是靠自己去争取来的!小编将对留言进行精选,被精选的留言才会在留言区显示并获得相应的楼层(由于微信留言功能限制,最多只能显示100条)。
踩楼送书活动获奖须知:
1、活动结束时踩中指定楼层的精选留言将获得《推荐系统算法实践》一本,共6名中奖者
百度云链接:
https://pan.baidu.com/s/1bWdv5DR_POKXItUy2xIWsw
提取码: iska


更多精彩
查看更多优质内容!
女朋友 | 大数据 | 运维 | 书单 | 算法
大数据 | javascript | Python | 黑客
AI | 人工智能 | 5G | 区块链
机器学习 | 数学 | 留言送书
脚本之家官方书店
觉得不错,请把这篇文章分享给你的朋友
转载 / 投稿请联系:Panda-nian
更多精彩,点击菜单栏“文章”进行查看
●
●
●
●
●
●
●
●
●
●
●
以上是关于推荐系统丨YouTube召回模型设计的主要内容,如果未能解决你的问题,请参考以下文章
结合论文看Youtube推荐系统中召回和排序的演进之路(中)篇
结合论文看Youtube推荐系统中召回和排序的演进之路(上)篇
推荐系统[八]算法实践总结V0:腾讯音乐全民K歌推荐系统架构及粗排设计
推荐系统[八]算法实践总结V0:腾讯音乐全民K歌推荐系统架构及粗排设计