自动特征工程在推荐系统中的研究
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动特征工程在推荐系统中的研究相关的知识,希望对你有一定的参考价值。
分享嘉宾:第四范式 罗远飞
内容来源:先荐推荐系统学院
发布平台:DataFunTalk
导读:第四范式资深研究员罗远飞针对推荐系统中的高维稀疏数据,介绍了如何在指数级搜索空间中,高效地自动生成特征和选择算法;以及如何结合大规模分布式机器学习系统,在显著降低计算、存储和通信代价的情况下,从数据中快速筛选出有效的组合特征。
以下是罗远飞的分享:
大家好!我是第四范式的罗远飞!
很高兴能有机会和大家一起交流关于自动机器学习方面的一些工作。我在第四范式的工作大都和自动机器学习相关,之前的精力主要集中在自动特征工程。虽然模型改进能够带来稳定的收益,但是更为困难。所以如果是在做一个新的业务,可以先尝试从做特征入手,特征工程往往能够带来更明显的收益。
AutoCross 的背景
本次报告所提及的自动机器学习,是针对表数据的自动机器学习。表数据是一个经典的数据格式,它一般包含多列,列可能对应离散特征或者连续特征。我们不能将用于图像、语音或者 NLP 中的模型直接拿过来用,需要做特定的优化。
本次报告提及的特征组合,特指 Feature Crossing,即两个离散特征的笛卡尔积。以 "去过的餐厅" 为例,我经常去麦当劳,那么我和麦当劳可以做为一个组合特征;再比如我去肯德基,则我和肯德基也可做为一个组合特征。
本次报告提及的自动特征工程,是指自动从上表数据中发现这些有效的组合特征。比如我是一位软件工程师,是一个特征;在第四范式工作,是另外一个特征。这两个特征是分成两列储存的,我们可以把这两列组合成一个新的特征,这个特征的指示性更强,更具有个性化。
为什么需要自动特征工程呢?
首先,特征对建模效果有着非常重要的作用。其次,客户的场景远比建模专家多,如我们的先荐业务有上千家媒体,我们不能给每个业务都配备一个专家,针对每一个场景人工去建模。最后,即使只有一个业务,数据也是多变的,面临的场景也是不停变化的,所以我们要做自动特征工程,不能让人力和我们的业务量呈正比。
AutoCross 的相关研究
自动特征工程主要分为两大类,一类是显式特征组合,另一类是隐式特征组合。
① 显式的特征组合
显式的特征组合有两个代表性工作,分别是 RMI [2] 和 CMI [3]。其中字母 "MI" 代表互信息 ( Mutual Information ),是一个经典的特征选择的方法。
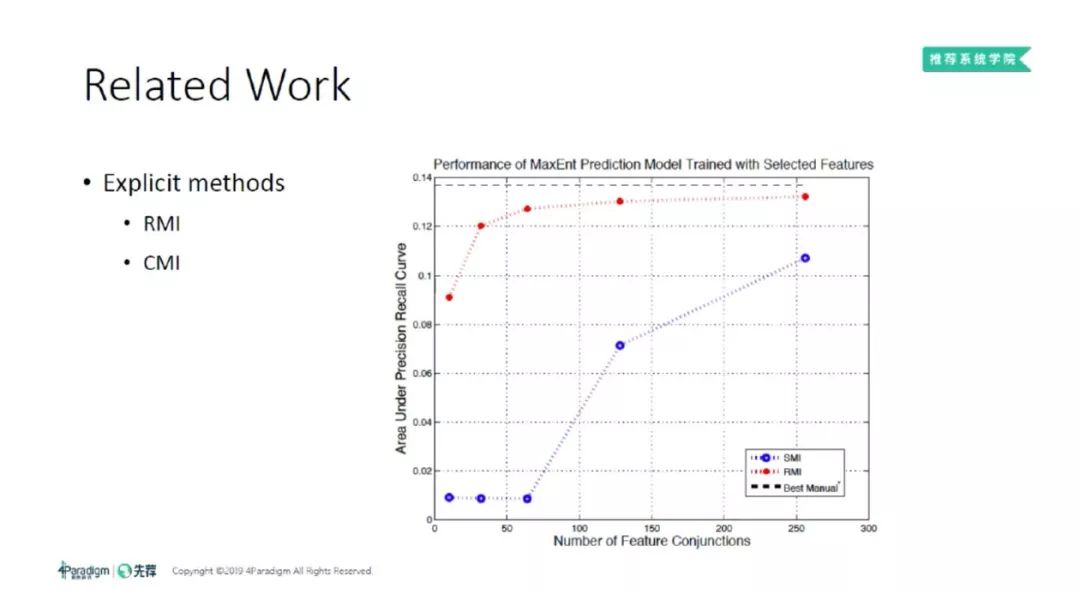
MI 是通过统计同一个数据中,两列特征的出现频率和共现频率计算得到。但是 RMI 的做法是在训练集合统计一部分信息,在另外一部分成为 reference 数据上统计另外一部分信息,这也是 "R" 的来源。上图来自于 RMI 的论文[2],表示随着不同的组合特征加进去,然后 AUC 逐渐地上涨。CMI 是另外一个经典的工作,CMI 通过分析对率损失函数,结合牛顿法,计算出每个特征的重要性。
它们都取得了不错的效果。但一方面,它们只考虑二阶特征组合;另外,它们均为串行算法,每次选择一个组合特征后,都需把其他特征重新训练一遍,是 O(n^2) 复杂度,其中 n 为特征数目。此外,MI 本身不允许一个特征下同时出现多个取值。
② 隐式的特征组合
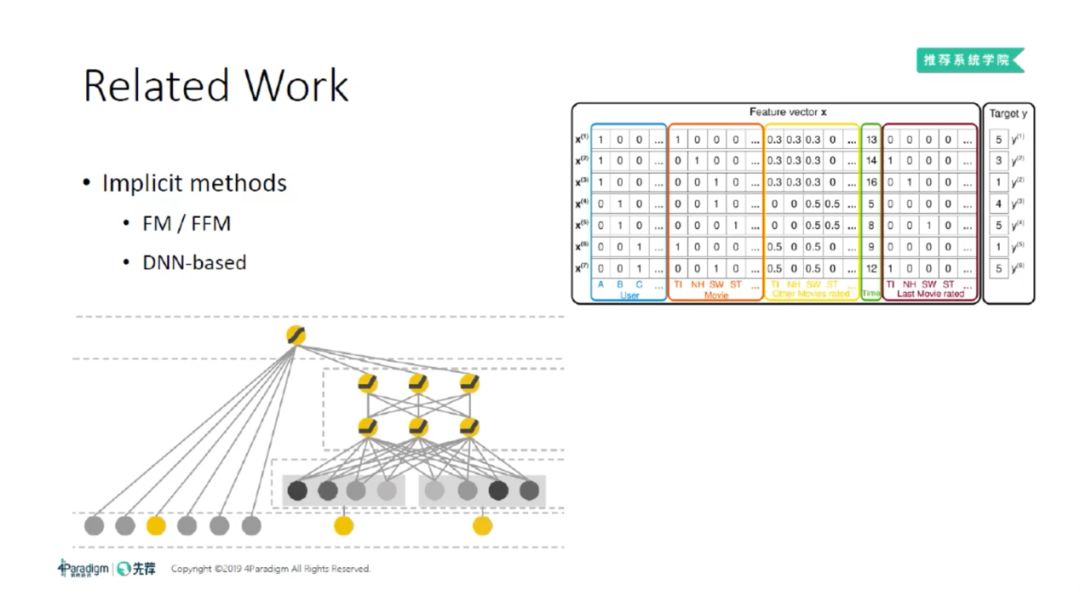
另外一类是隐式特征组合,大家可能更熟悉一些。FM[4] 和 FFM[5] 是枚举所有的二阶特征组合,它们组合方式是用低维空间中的内积去代表两个特征的组合,取得了很好的效果。随着 DL 的兴起,现在更流行基于 DNN 做隐式特征组合。但是它的可解释性不强,一直被大家诟病。
我们提出 AutoCross[1],它具有很强的可解释性,能够做到高阶特征组合,同时具有较高的 Inference 效率。
AutoCross 整体结构

从左往右看,AutoCross 的输入是数据和对应的特征类型,然后经过 AutoCross 的 Flow,输出一个特征生成器,能够把学到的特征处理方式应用于新数据。
Flow 里主要有三个部分,首先是预处理,然后是组合特征生成和组合特征选择的迭代过程。针对数据预处理,我们提出了多粒度离散化;针对怎么从指数级空间中有效的生成组合特征,我们用了集束搜索 ( Beam Search );针对如何有效且低代价地特征选择,我们提出了逐域对数几率回归 ( Field-wise LR ) 和连续小批量梯度下降 ( Successive Mini-batch GD ) 两种方法。
AutoCross 算法
下面我们看一下每个过程所涉及的算法。
首先是数据预处理,数据预处理的目的是补充缺失值,并将连续特征离散化。我们观察到,对于连续特征,在离散化的时候,如果选择的离散化粒度不一样,其效果会差别非常大。甚至在一个数据集上观察到 AUC 有10个百分点的差异。如果对每一个数据集都手动设置最优的离散化粒度,代价比较高,也不现实。
基于此我们提出了多粒度离散化方法,同时使用多种粒度去离散化同一个特征,比如特征 "年龄",我们按照年龄间隔为5的离散化一次,年龄间隔为10的离散化一次,年龄间隔为20的再离散化一次,同时生成多个不同的离散化特征,让模型自动去选择最适合它的特征。

① 集束搜索 ( Beam Search )
如前文所述,假设有 n 个原始特征,那么可能的 k 阶特征有 O(n^k) 个,这是一个指数级增长的过程。如何在这个空间中有效地去搜索、生成、组合特征呢?如果都生成,在计算和存储上都不太可行。
我们借鉴集束搜索 ( Beam Search ) 的方法来解决该问题。它的工作原理是,先生成一部分二阶组合特征,然后用效果好的二阶组合特征去衍生三阶组合特征,并非生成所有的三阶组合特征,相当于一种贪心的搜索方法。
② 逐域对数几率回归 ( Field-wise LR )
我们通过多粒度离散化对数据进行预处理,之后通过集束搜索缩减搜索空间。
但生成的特征依然数量众多,怎么才能快速、低代价地从生成特征中选出有效的特征呢?对此,我们提出了逐域对数几率回归 ( Field-wise LR ) 算法,固定已选特征对应的模型参数,然后计算候选特征中哪个特征加进来,能够最大程度的提升模型效果。这样做能够显著节约计算、通信和存储上的开销。

③ 连续小批量梯度下降 ( Successive Mini-batch GD )
为了进一步降低特征评估成本,我们又提出了连续小批量梯度下降 ( Successive Mini-batch GD ) 方法。在小批量梯度下降的迭代过程中,逐渐淘汰不显著的候选特征,并给予较重要的特征更多批的数据,以增加其评估准确性。
AutoCross-System 优化
下面介绍我们在系统上做的一些优化。
① 缓存特征权重
从算法上来看,我们的系统是一个指数空间的搜索问题,即使能够降低其复杂度,它的运算代价依然很大。因此我们会对数据采样,并序列化压缩存储。
之后,当运行逐域对数几率回归时,系统会把已经计算过的特征权重缓存下来。如果按照以前的方法,我们需要先从参数服务器上获取已经生成特征的权重,这一步会带来网络开销;获取之后要做运算,并生成该特征及预测 ,这一步会产生计算开销;生成特征之后,再存储到硬盘中,进一步会产生存储成本。但是,我们把之前的那些特征的权重都给缓存下来,通过直接查表,就能够降低网络、计算、存储的开销。
② 在线计算
除了缓存特征权重之外,我们还进行了在线计算。我们在做特征生成的同时,有独立的线程去序列化数据和生成特征。
③ 数据并行
此外,数据并行也是系统优化的常用方法。系统的每个进程中都有一份计算图,并通过主节点,或者参数服务器,保证它们之间有序地在进行各个操作。
AutoCross 实验
下图是我们的实验结果。
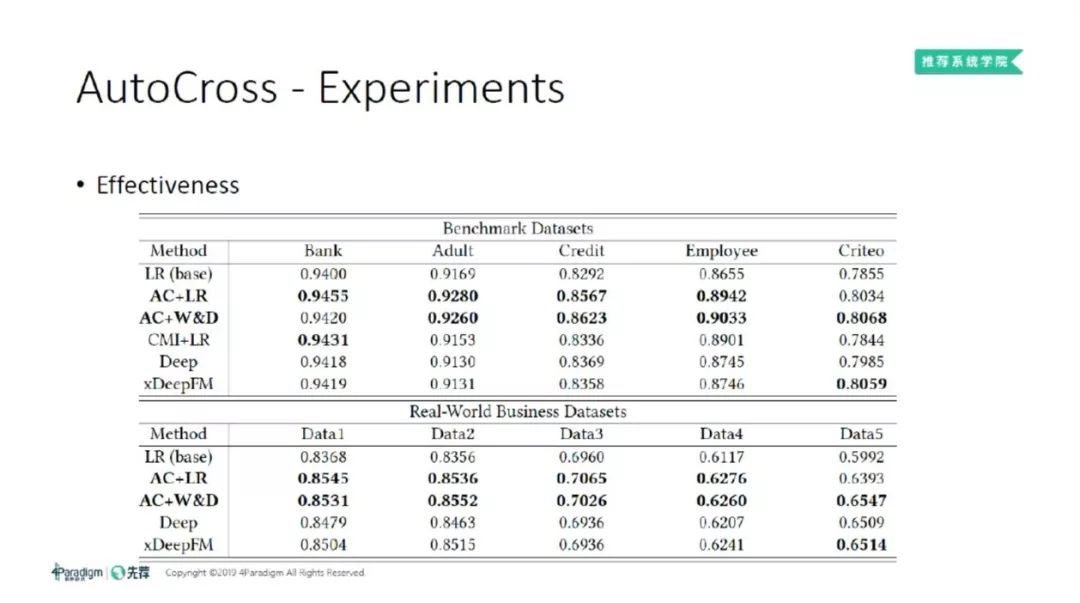
这里的 baseline 有两个。我们首先看 AutoCross 产生的特征对 LR 的帮助。当我们把 AutoCross 的特征放进 LR 之后,其效果变化很明显 ( 第1行和第2行 )。同时,我们对比了 AutoCross 和 CMI 两种方法 ( 见第2行和第4行 )。经过对比后发现,AutoCross 始终优于 CMI。
为验证 AutoCross 产生的特征是否会对深度模型有帮助,我们同样把 AutoCross 的特征和 W&D 模型结合 ( 见第3行 )。我们发现,当我们把特征给 W&D 之后,W&D 模型也取得了很不错的效果,在10个数据集上效果均能和当前最好的深度学习模型相媲美。
参考文献
[1] Yuanfei, Luo, Wang Mengshuo, Zhou Hao, Yao Quanming, Tu WeiWei, Chen Yuqiang, Yang Qiang, and Dai Wenyuan. 2019. “AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications.” KDD.
[2] Rómer Rosales, Haibin Cheng, and Eren Manavoglu. 2012. Post-click conversion modeling and analysis for non-guaranteed delivery display advertising. WSDM.
[3] Olivier Chapelle, Eren Manavoglu, and Romer Rosales. 2015. Simple and scalable response prediction for display advertising. TIST.
[4] Rendle, Steffen. “Factorization machines.” 2010. ICDM.
[5] Yuchin Juan, Yong Zhuang,Wei-Sheng Chin, and Chih-Jen Lin. 2016. Field-aware factorization machines for CTR prediction. In ACM Conference on Recommender Systems.
[6] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. IJCAI.
——END——
文章推荐:
DataFunTalk:
专注于大数据、人工智能技术应用的分享与交流。
一个「在看」,一段时光! 以上是关于自动特征工程在推荐系统中的研究的主要内容,如果未能解决你的问题,请参考以下文章