基于surprise的图书电影推荐系统
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于surprise的图书电影推荐系统相关的知识,希望对你有一定的参考价值。
Blog: http://yishuihancheng.blog.csdn.net
推荐系统在我们日常生活中发挥着非常重要的作用,相信实际从事过推荐相关的工程项目的人或多或少都会看多《推荐系统实战》这本书,我也是读者之一,个人感觉对于推荐系统的入门来说这本书籍还是不错的资料。很多商场、大厂的推荐系统都是很复杂也是很强大的,大多是基于深度学习来设计强有力的计算系统,我在后面的文章中会介绍一下深度学习的推荐系统项目实践,今天主要是基于surprise模块来实现图书、电影的推荐系统设计与实现。
本文所用到的数据集可以从下面的链接处下载:
https://download.csdn.net/download/together_cz/10916350
关于surprise模块的相关介绍和实例可以参考下面的链接:
https://surprise.readthedocs.io/en/stable/getting_started.html
使用surprise来加载自己的数据集首先要定义一个数据读取器来格式化数据,简单的数据读取器实现如下:
#构建读取器
reader=Reader(line_format=data_format,sep=sep)
mydata=Dataset.load_from_file(data_path,reader=reader)
图书推荐系统设计示意图如下所示:
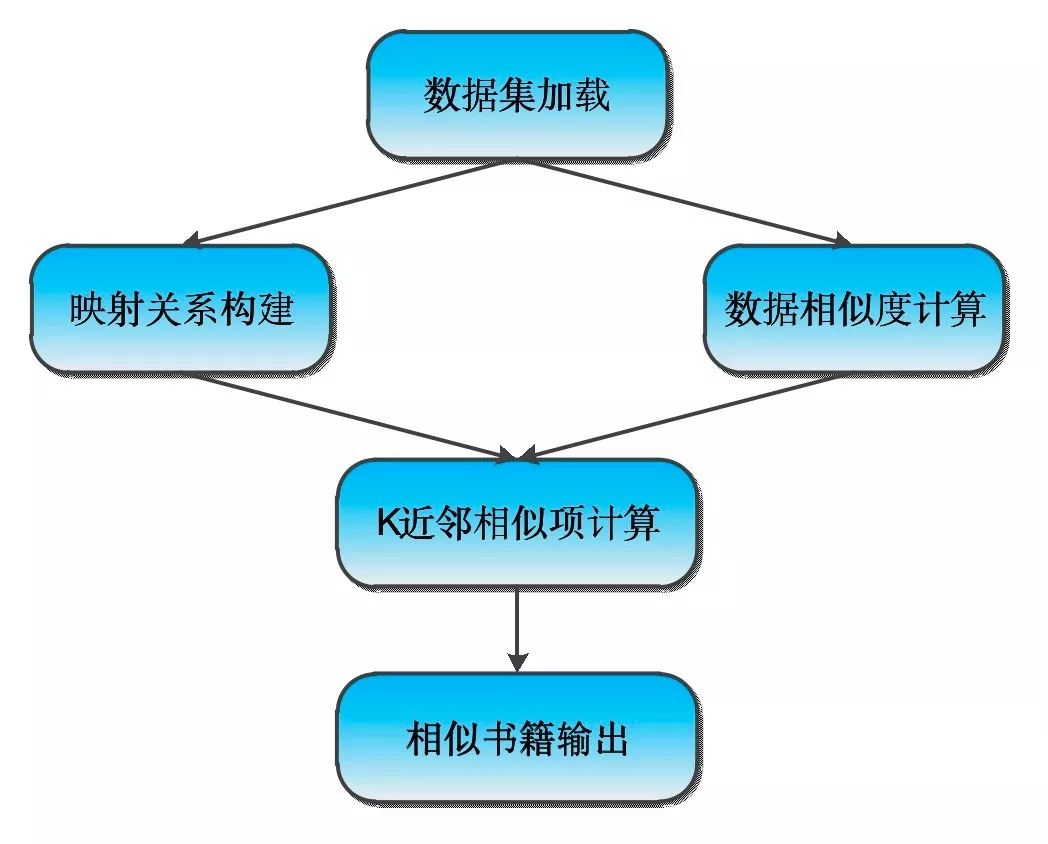
整体的设计思想很简单,并没有很难理解的节点,接下来看具体的代码实现:
def bookRecommendSystem(map_data='book.csv',train_data='rating.csv',data_format='book user rating',sep=',',flag='SVD',k=10):
'''
图书推荐系统
'''
id_name_dic,name_id_dic=bookDataMapping(map_data)
myModel,dataset=buildModel(data_path=train_data,data_format=data_format,sep=sep,flag=flag)
print '==================model Training Finished========================'
performace=evaluationModel(myModel,dataset)
print '==================model performace==================='
print performace
current_playlist_id='1239'
print u'当前的用户id:'+current_playlist_id
current_playlist_name=id_name_dic[current_playlist_id]
print u'当前的书籍名称:'+current_playlist_name
playlist_inner_id=myModel.trainset.to_inner_uid(current_playlist_id)
print u'当前的用户内部id:'+str(playlist_inner_id)
#以10个用户为基准推荐
playlist_neighbors=myModel.get_neighbors(playlist_inner_id,k=k)
playlist_neighbors_id=(myModel.trainset.to_raw_uid(inner_id) for inner_id in playlist_neighbors)
#把歌曲id转成歌曲名字
playlist_neighbors_name=(id_name_dic[playlist_id] for playlist_id in playlist_neighbors_id)
print("和用户<", current_playlist_name, '> 最接近的10本书为:\n')
for playlist_name in playlist_neighbors_name:
print(playlist_name, name_id_dic[playlist_name])
上面的函数实现了图书推荐系统,相应的注释都在里面,就不多解释了,下面对其中几个关键的函数实现进行说明。
模型初始化模块:
def initModel(flag='NormalPredictor'):
'''
多种推荐算法对比使用
'''
if flag=='NormalPredictor': #使用NormalPredictor
return NormalPredictor()
elif flag=='BaselineOnly': #使用BaselineOnly
return BaselineOnly()
elif flag=='KNNBasic': #使用基础版协同过滤
return KNNBasic()
elif flag=='KNNWithMeans': #使用均值协同过滤
return KNNWithMeans()
elif flag=='KNNBaseline': #使用协同过滤baseline
return KNNBaseline()
elif flag=='SVD': #使用SVD
return SVD()
elif flag=='SVDpp': #使用SVD++
return SVDpp()
elif flag=='NMF': #使用NMF
return NMF()
else:
return SVD()
推荐系统模型构建模块:
def buildModel(data_path='rating.csv',data_format='user item rating',sep=',',flag='KNNBasic'):
'''
推荐系统模型
'''
#构建读取器
reader=Reader(line_format=data_format,sep=sep)
mydata=Dataset.load_from_file(data_path,reader=reader)
#计算歌曲和歌曲之间的相似度
train_set=mydata.build_full_trainset()
print '================model training================'
model=initModel(flag=flag)
model.fit(train_set)
return model,mydata
数据集映射关系构建模块:
def bookDataMapping(data_path='book.csv'):
'''
加载原始的 "id,name" 数据来构建字典映射
'''
csv_reader=csv.reader(open(data_path))
id_name_dic,name_id_dic={},{}
for row in csv_reader:
id_name_dic[row[0]]=row[10]
name_id_dic[row[10]]=row[0]
return id_name_dic, name_id_dic
简单调用如下所示:
bookRecommendSystem(map_data='book.csv',train_data='RRR.csv',data_format='user item rating',sep=',',flag='KNNBasic',k=10)
默认采用了KNN算法,五折交叉验证计算,具体的结果输出如下:
------------
Fold 1
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9211
MAE: 0.7108
FCP: 0.7038
------------
Fold 2
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9211
MAE: 0.7093
FCP: 0.6996
------------
Fold 3
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9234
MAE: 0.7133
FCP: 0.7010
------------
Fold 4
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9210
MAE: 0.7119
FCP: 0.7017
------------
Fold 5
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9268
MAE: 0.7167
FCP: 0.6983
------------
------------
Mean RMSE: 0.9227
Mean MAE : 0.7124
Mean FCP : 0.7009
------------
------------
==================model performace===================
defaultdict(<type 'list'>, {u'fcp': [0.703847835793307, 0.6995619798679573, 0.7009530691688108, 0.7017142119961722, 0.6982634284783771], u'mae': [0.7107821167817494, 0.7093057204220446, 0.7132818148803571, 0.7119004793330316, 0.7167381500990199], u'rmse': [0.921100168545926, 0.9210542860057216, 0.9234120678271927, 0.9209873056186509, 0.9267740800608146]})
当前的用户id:1239
当前的书籍名称:Chronicle of a Death Foretold
当前的用户内部id:537
(u'\u548c\u7528\u6237<', 'Chronicle of a Death Foretold', u'> \u6700\u63a5\u8fd1\u768410\u672c\u4e66\u4e3a\uff1a\n')
('Frostbite (Vampire Academy, #2)', '384')
('The Call of the Wild', '375')
('The Knife of Never Letting Go (Chaos Walking, #1)', '1050')
('The Neverending Story', '877')
('Lord of the Flies', '28')
('Olive Kitteridge', '930')
('Twenty Thousand Leagues Under the Sea', '699')
("1st to Die (Women's Murder Club, #1)", '336')
('The Big Short: Inside the Doomsday Machine', '985')
('The Black Echo (Harry Bosch, #1; Harry Bosch Universe, #1)', '902')
下面我使用Suprise内置的电影数据集来构建电影的推荐模型,这里数据集使用的是内置的数据集ml-100k。
首先,构建id、name的映射关系字典,方法如下:
def dataMapping(data='item.txt'):
'''
构建id和name的映射关系字典
'''
id_name_dict,name_id_dict={},{}
with open(data) as f:
data_list=[one_line.strip().split('|') for one_line in f.readlines() if one_line]
for one_list in data_list:
id_name_dict[one_list[0]]=one_list[1]
name_id_dict[one_list[1]]=one_list[0]
return id_name_dict,name_id_dict
其余的推荐工作与book推荐类似,这里就不再详细解释了,这里直接上代码:
def movieRecommendSystem():
'''
电影推荐系统
'''
#构建训练数据集与KNN模型
movie_data=Dataset.load_builtin('ml-100k')
trainset=movie_data.build_full_trainset()
algo=KNNBasic()
algo.train(trainset)
#构建id、name映射关系
id_name_dict,name_id_dict=dataMapping(data='item.txt')
#电影推荐
#以电影Army of Darkness (1993)为基础
raw_id=name_id_dict['Army of Darkness (1993)'] #获得raw_id
inner_id=algo.trainset.to_inner_iid(raw_id) #转换为模型内部id
neighbors=algo.get_neighbors(inner_id,10) #模型推荐电影(默认10个推荐结果)
res_ids=[algo.trainset.to_raw_iid(_id) for _id in neighbors] #模型内部id转换为实际电影id
movies=[id_name_dict[raw_id] for raw_id in res_ids] #获得电影名称
print u"========================10个最相似的电影:========================"
for movie in movies:
print name_id_dict[movie],'==========>',movie
推荐结果如下:
Done computing similarity matrix.
========================10个最相似的电影:========================
242 ==========> Kolya (1996)
486 ==========> Sabrina (1954)
88 ==========> Sleepless in Seattle (1993)
603 ==========> Rear Window (1954)
20 ==========> Angels and Insects (1995)
479 ==========> Vertigo (1958)
1336 ==========> Kazaam (1996)
673 ==========> Cape Fear (1962)
568 ==========> Speed (1994)
623 ==========> Angels in the Outfield (1994)
以上是关于基于surprise的图书电影推荐系统的主要内容,如果未能解决你的问题,请参考以下文章