如何只使用标签来构建一个简单的电影推荐系统
Posted AI派
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何只使用标签来构建一个简单的电影推荐系统相关的知识,希望对你有一定的参考价值。
编译:ronghuaiyang
使用基于内容的方法来找到最相似的电影。
No MIT chalkboard required
介绍
假设你正在推出下一个非常大的订阅视频点播(SVOD)流媒体服务,并且你已经获得了过去100年里发行的所有主要电影的流媒体权。祝贺你,这是不可思议的壮举!
现在你有了很多电影。如果没有推荐系统,你就会担心随着时间的推移,用户可能会被他们不关心的电影所淹没。这可能会导致客户流失,这是你最不想看到的!
所以你决定建立一个电影推荐系统。由于你的服务是新的,所以你还没有足够的数据来了解哪些用户正在观看哪些电影。这就是所谓的冷启动问题,它不能让你仅根据用户的历史收视记录来推荐电影。
幸运的是,即使没有足够的观看数据,我们仍然可以建立一个像样的电影元数据推荐系统。这就是MovieLens的作用所在。MovieLens提供了一个公共数据集,其中包含每个电影的关键字标签。这些标签信息量很大。例如,看看Good Will Hunting的最重要的社群标签。

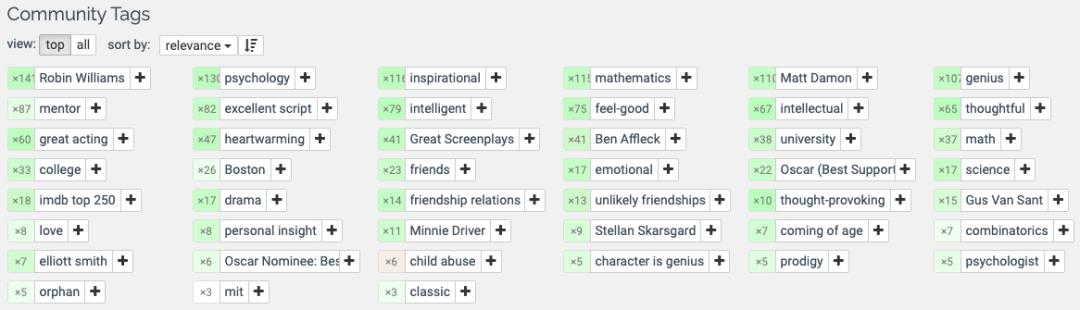
在这篇文章的其余部分,我将回答三个业务问题,这三个问题对于构建一个简单的基于内容的推荐系统非常关键,其中的标签来自MovieLens:
-
每部电影需要多少个标签? -
我们如何使用标签来衡量电影之间的相似性? -
我们如何使用标签为用户生成电影推荐?
这个分析的代码可以在这里找到:https://github.com/JohnsonKuan/movie-rec-tags,以及数据和Conda环境YAML文件,以便你轻松地复现结果。
1) 每部电影我们需要多少个标签?
MovieLens标签数据集中大约有10K个不一样的电影和1K个不一样的标签。每部电影的每个标签都有一个相关分数,所以大约有1000万个电影标签对。相关性得分范围为0到1。
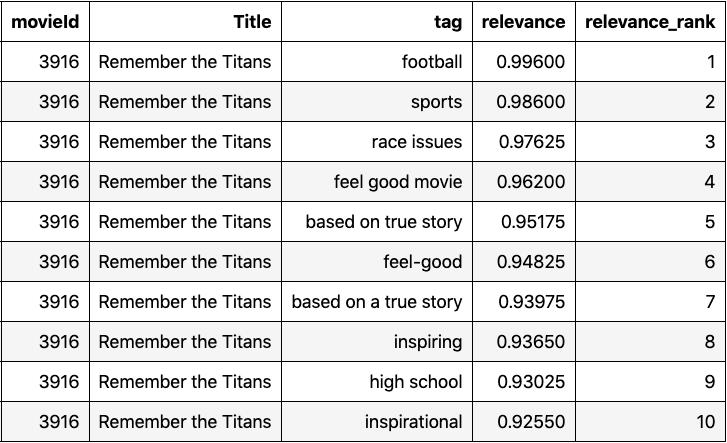
并不是每个标签都与电影相关,所以我们只需要保留最相关的标签。首先,我们可以根据相关评分对每部电影的标签进行排序。例如,下面是Remember the Titans的top10标签。请注意,相关性评分远远高于0.9,这表明它们是非常相关的标签。
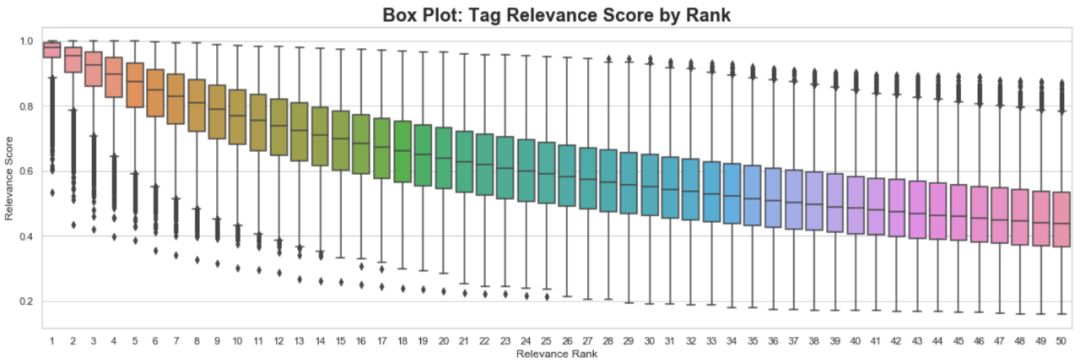
接下来,我们在下面的图中确认,电影的高排名标签往往具有较高的中值相关性得分。电影的排第一个的标签的中值相关度几乎是1。我们可以看到,当我们下降到第50位时,中值相关性得分逐渐下降。
为了找到与电影最相关的标签,我们可以根据相关性评分保留电影的前N个标签。在这里,我们需要仔细挑选。如果N很小,我们有非常相关的但是很少的标签。如果N很大,我们有很多标签,但是其中很多可能是无关的。
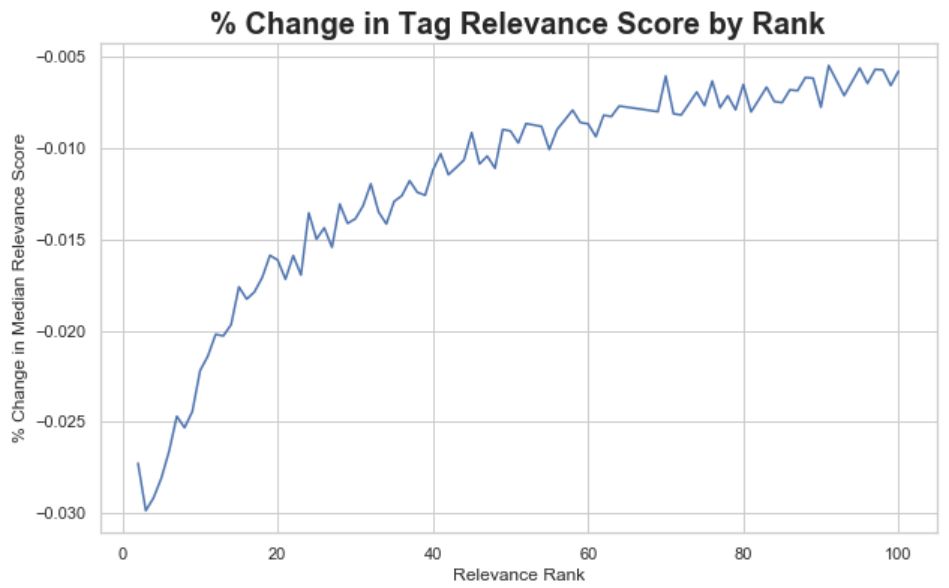
下面的图显示了从第1个标签到第100个标签的中值的变化百分比。当相关性得分开始变得更稳定时,我们看到在第50位附近有一个拐点。因此,我们可以选择N=50作为每个电影保留的合理数量的标签。注意,这是一个相当简单的“拐点方法”风格的方法,可以在以后进行优化。
现在我们可以得到每个电影的前50个标签的列表,我们将在下一节中使用它们。例如,Toy Story的前50个标签如下。

2) 我们如何使用标签来度量电影之间的相似度?
在为用户生成电影推荐之前,我们需要一种基于电影的前50个标签的相似性度量方法。在基于内容的推荐系统中,用户将被推荐与他们已经看过的电影相似的电影。
在这里,我会演示两种度量相似性的方法:
-
两个电影标签集合的 Jaccard Index -
基于标签的电影向量(即内容嵌入)的 余弦相似度 。
Jaccard Index
使用Jaccard Index的第一种方法度量两个集合A和B之间的相似性,即交集的大小除以并集的大小。在度量电影之间的相似性时,我们可以计算这两组电影标签的索引。

例如,我们有三个电影下面和他们的前3个标签:
-
电影A的标签 =(动作,空间,友情) -
电影B的标签=(冒险,太空,友谊) -
电影C的标签=(浪漫,喜剧,成长)
直观上,我们可以看出电影A与B更相似,而不是C。这是因为电影A和B共享两个标签(空间,友情),而电影A和C不共享任何标签。
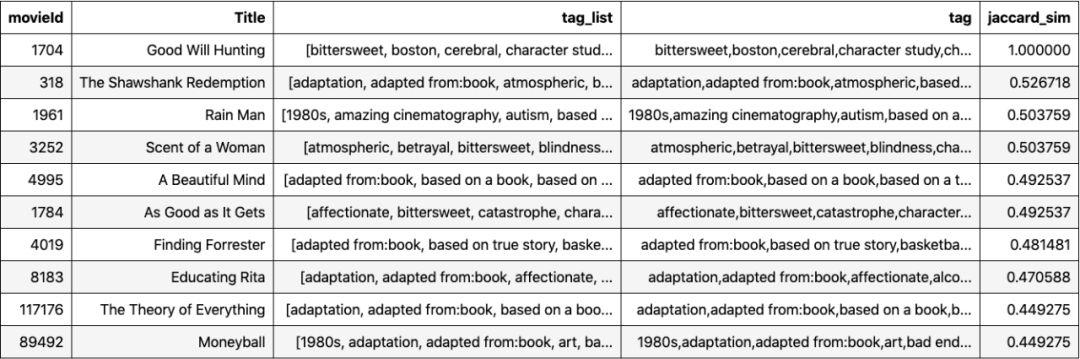
下面是基于Jaccard Index的与Good Will Hunting相似的10部电影。对于Good Will Hunting的观众来说,这些建议似乎是合理的。注意,我在列表中包括了Good Will Hunting,以显示在比较电影本身时Jaccard Index=1。
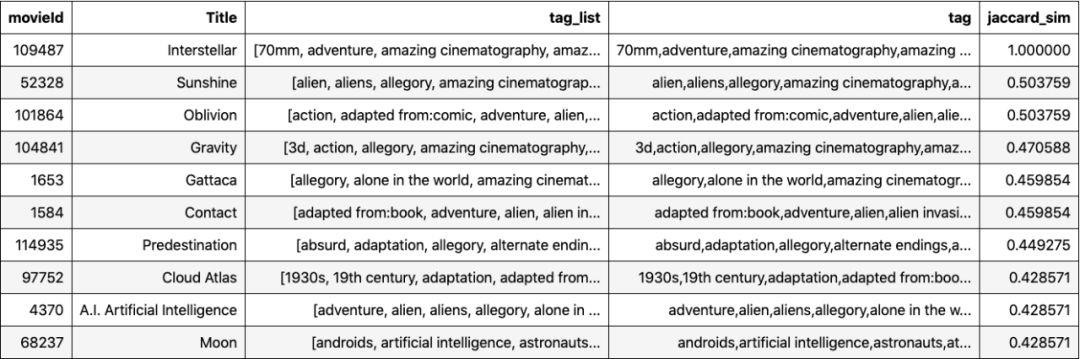
以下是10部与Interstellar相似的电影。对于Interstellar的观众来说,这些建议似乎也很合理。
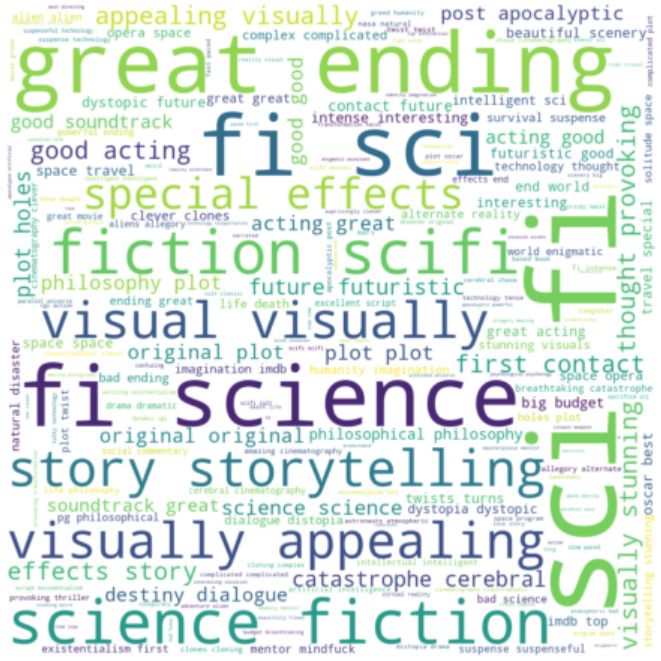
为了进一步说明Jaccard Index的有效性,请看下面基于和Interstellar相似的电影的标签频率的词云。在这里,我们可以看到哪些标签在相似性计算中更加突出(例如科幻小说,伟大的结局,反乌托邦的未来,哲学,大脑)。
电影向量(也就是内容嵌入)的余弦相似度
第一个使用Jaccard Index的方法帮助我们建立了一种关于与标签相似的含义的直觉。基于余弦相似度的第二种方法稍微复杂一点。它要求我们把电影表示成一个向量。这里,向量就是一组数字。
例如,我们可以用三个实数来表示三个相同的电影:
-
电影A = (1.1, 2.3, 5.1) -
电影B = (1.3, 2.1, 4.9) -
电影C = (5.1, 6.2, 1.1)
直观上,我们可以再次看到电影A与B更相似,而不是C。这是因为电影A和B在每个维度上有更接近的数字(例如第一个维度是1.1 vs 1.3)。
为了找到一个好的向量表示的电影,我使用了Doc2Vec (PV-DBOW)技术,我们拿到一个电影(文档),并基于标签(文档中的词)学习一个到潜在K维空间的映射。我不会在这里深入讨论细节,但这是我们如何基于标签将电影表示为向量的方法。
一旦我们可以把每一部电影表示成一个向量,我们就可以计算向量之间的余弦相似度来找到相似的电影。我不会在这里详细介绍余弦相似度,但是在一个较高的层次上,它告诉我们电影向量彼此之间有多么相似,我们可以使用它来生成推荐。
下面我用UMAP在二维空间上可视化电影向量,这是一种流行的非线性降维技术。我们可以看到,在这个向量空间中距离较近的电影更加相似(例如Toy Story和Monsters等等)。
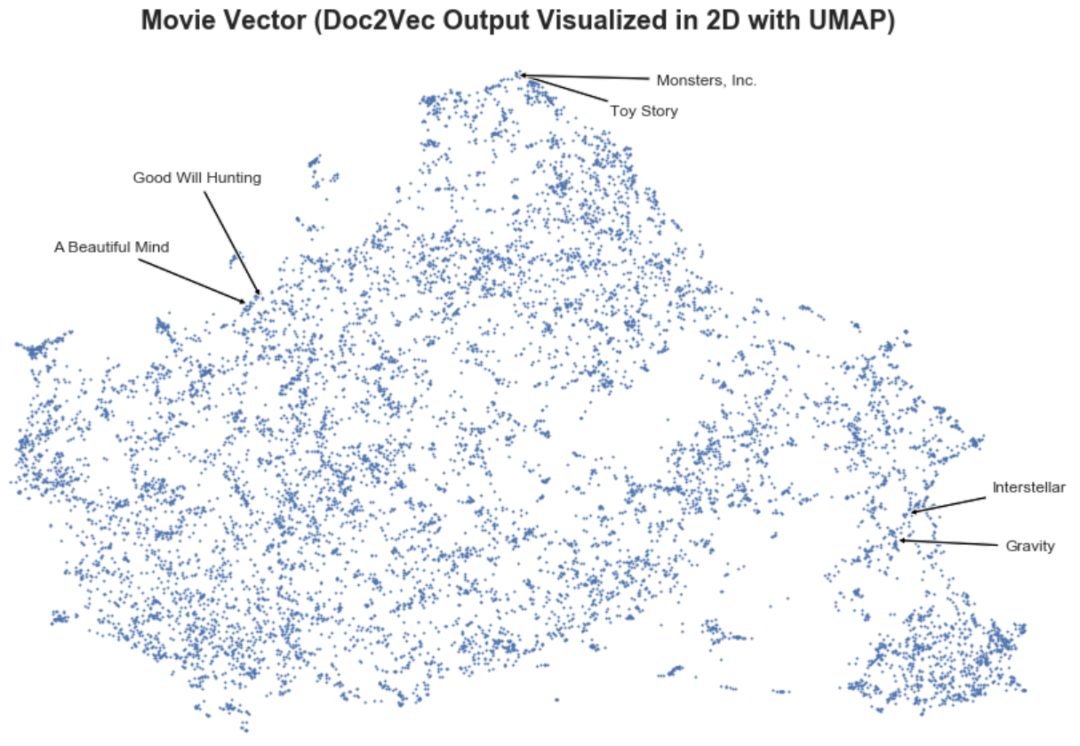
3) 我们如何使用标签为用户生成电影推荐?
现在我们可以使用标签来度量电影之间的相似性,我们可以开始为用户生成电影推荐。
请记住,在基于内容的推荐系统中,用户将被推荐与他们已经看过的电影相似的电影。如果用户只看过一部电影(如Good Will Hunting),我们可以像以前一样简单地使用Jaccard Index(或余弦相似度)来生成要推荐的类似电影的列表。
更实际的情况是,用户已经观看了一组电影,我们需要根据这些电影的组合属性来生成推荐。
一个简单的方法是计算一个用户向量,作为他们看过的电影向量的平均值。这些用户向量可以表示用户的电影偏好属性。
例如,如果用户只看过电影A和B:
-
电影A = (1,2,3) -
电影B = (7,2,1) -
用户向量=电影A和B的平均 = (4,2,2)
以下是我喜欢看的电影。我们如何使用这些电影的标签生成电影推荐?
Interstellar, Good Will Hunting, Gattaca, Almost Famous, The Shawshank Redemption, Edge of Tomorrow, Jerry Maguire, Forrest Gump, Back to the Future
我的用户向量是上述9部电影的电影向量的平均值。我可以使用我的用户向量,找到我还没有看过的最相似的电影(基于余弦相似性)。下面是我的电影推荐,这是令人惊讶的好,考虑到我们在这里只是使用了电影标签!
The Theory of Everything
Cast Away
Dead Poets Society
Charly
Rain Man
Groundhog Day
Pay It Forward
A Beautiful Mind
E.T. the Extra-Terrestrial
Mr. Holland's Opus
On Golden Pond
It's a Wonderful Life
Children of a Lesser God
The Curious Case of Benjamin Button
Star Trek II: The Wrath of Khan
Cinema Paradiso
Mr. Smith Goes to Washington
The Terminal
Her
The World's Fastest Indian
The Truman Show
Star Trek: First Contact
The Family Man
下面总结一下我们基于内容的推荐系统。请注意,如果我们将系统部署为API,我们可以在批处理过程中预先计算用户向量和相似分数,以加快推荐的提供。
-
输入:用户向量(从标签中学习到的电影向量的平均值) -
输出:基于用户和电影向量的余弦相似度,与用户相似的电影列表
英文原文:https://towardsdatascience.com/how-to-build-a-simple-movie-recommender-system-with-tags-b9ab5cb3b616
完)
以上是关于如何只使用标签来构建一个简单的电影推荐系统的主要内容,如果未能解决你的问题,请参考以下文章