推荐系统背后的冷思考
Posted 阅读以明智
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统背后的冷思考相关的知识,希望对你有一定的参考价值。
1月份在苏宁分享的文字版整理出来了,结合「“推荐系统背后的冷思考”」ppt分享给大家。推荐系统的概念这几年非常火爆,给很多公司带来了实实在在的收益,但如果想将其作为公司「增长飞轮」中的一环,那其实背后有非常多的点需要我们深思挖掘。如果不足和错误之处,还望「大家批评指正」,enjoy。

▌1.提纲与目录
以上是此次分享的目录和主题
首先是「业务介绍」,其次是「宏微观看增长」,再者结合具体「案例」介绍宏微观的若干点,最后是本次分享的总结。
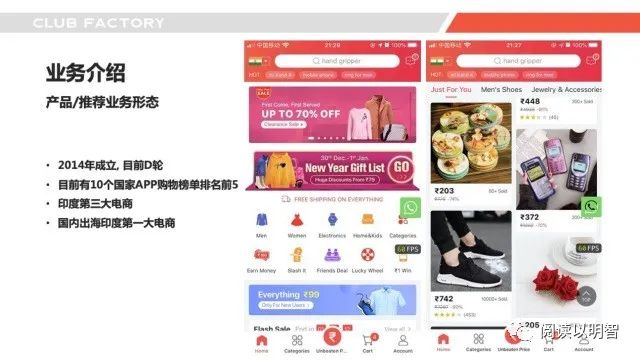
▌2.1业务介绍-产品形态
那我先来介绍一下我们公司的业务的产品,我们公司是一家「出海2c电商」,2014年成立的,去年初融了D轮,目前每日有流量和订单的国家和地区超过30多个,但主要的用户还是来自印度,我们是目前印度的第三大电商,国内出海印度第一大。目前公司有2大业务模式,「自营和平台模式自营和平台模式」,自营是国内商品跨境卖给印度用户,平台则是印度商家入驻卖给印度用户,右边是我们公司的app,我们公司还有一个特色,就是我们技术+大数据占公司接近「50%」,运营占比在30%以下,所以很多问题一上来就是以「技术和数据驱动」为主的,为了提高人效,初期我们就一直关注如何建立一套「可循环可迭代」的系统。这个有利有弊,但是算是走出了一条不一样的跨境出海之路。
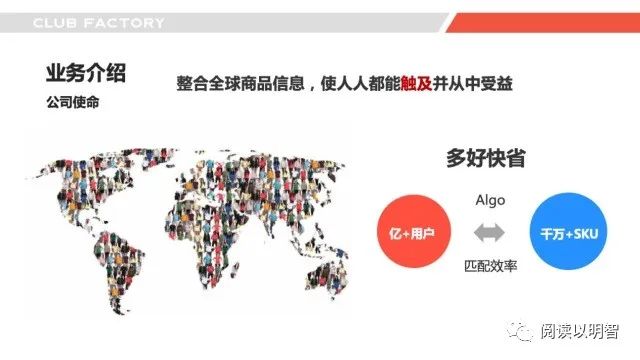
▌2.2业务介绍-使命
这个是我们公司的使命,「“整合全球商品信息,使人人都能触及并从中受益”」,其实落到我们推荐算法这一块,我的理解其中的“触及”两字是核心,让用户看到和感知到「多快好省」,提升「流量匹配效率」,其实这几个字都非常重要考察了电商的很多核心能力,我们稍后再做一些讨论。

▌2.3业务介绍-挑战
当然这里面也有很多挑战,比如推荐侧来说,「场景多,目标多,往往不是完全一致的」,而且「没有ground truth」,「用户购物链路长」;数据闭环侧来说,你需要考虑的用户「全流程体验」,商品的「起量和衰退」,商家的「成长和分级」。公司作为商业机构,也会考虑业务模式的平衡,用户、商家、商品的平衡。比较不一样的点,印度相对中国用户「兴趣分层」(中国一二线与四五六线城市的需求差异)还未这么明显,对价格折扣异常敏感,海外购物因为信任 、支付等问题转化低,正反馈更加稀疏。「用户群需求差异越大,推荐能够发挥效果的空间越大」。

▌3.1宏微观看增长-公式
接下来我们从宏微观分别论述一下我们对增长问题的见解,一般大家遇到增长问题喜欢「拆解」,这里我把规模分别拆解成了流量乘以转化乘以回访和复购,回访和复购我称之为「x因素」,因为其实他比转化更难把握,转化更加短期更加当下,但是x因素才是企业最终能够笑到最后的「本质」,相信大家也听过1.01的365次方和0.99的365次方的故事,「复利思维」可以带来恐怖的增长或衰退。

▌3.2宏微观看增长-宏观冰山模型
宏观来看,规模依赖底层的「用户体验、供应链能力、组织、财务、数据算法能力」的高低,这里用户体验很好理解,在电商场景下就是让其感知多快好省,这背后供应链是感知层的上流,必须有够好、够省、够多的商品,够快是组织能力,财务、数据算法是「闭环能力」,如何让飞轮高效、健康地转起来。这里刚好举一个例子讲讲如何通过技术和数据快速构建起电商的「多和省」,我把它称之为“站在巨人肩膀上”,多是爬虫可以帮助快速找到海外受欢迎的货,省还是通过爬虫可以对同一批货找到多个供应商,必然可以带来省。受欢迎的货可以从amazon和flipcart找,然后去1688拿,这里用到了爬虫和图像技术,再加一个翻译就可以机器上货了。这里还有很多非推荐相关的,如数据选品、智能定价、智能营销等,此次分享不过多展开,后期有机会跟大家再交流。

▌3.3宏微观看增长-微观冰山模型
微观我们来看看转化这个点,个人提炼了几点,外层是算法、数据、产品的「闭环」,中间是数据、特征和算法、底层依赖商品、用户、商家理解,微观转化层面后面刚好涉及,我先不过多展开。
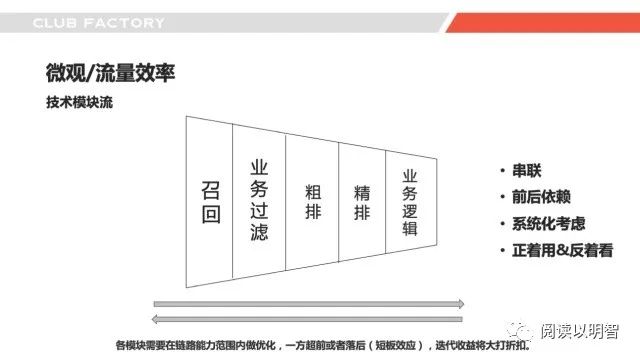
▌4.1微观-技术模块拆解
接下来我们进入微观/流量效率这个模块进行一些细粒度地探讨,上面这个图是做推荐的人再熟悉不过的了,从召回到最终展现,层层筛选商品,最终用户根据结果进行反馈,大模块间「串联、前后依赖」,这里我想分享自己的一些感悟是数据流是漏斗从大到小的,我们是正着用,但是往往很多时候我们没有系统化细粒度地去观察和理解,我称之为「反着看」。何解呢,就是门当户对的概念,今天你死命优化召回,但是排序太弱了,没效果,今天你死命优化排序,召回太弱了,没效果。推荐系统因为串联和前后依赖的原因,「短板效应」非常明显,一方超前和落后迭代效果都是不明显的,我们结合具体实例进行讲解。

▌4.2微观-四象限
每个模块我自己梳理了几个点,「相关,新鲜、多样、流行、商业需求」等,如果前置模块没有做好,那甭想后面的模块做的多好。

▌4.3微观-评估举例
举个召回的例子来说,我们可以看看评估方式,这里介绍2种,比如i2i的评估,我们可以去看命中率,a的相似为b、c、d,用户点了a后点了d、e、f,则命中率为三分之一,这里还可以结合位置等因素,当然我们还可以评估i2i的「准确率、召回率、F1、覆盖率、零结果率、深度」等等。
还有的评估方式其实普适性更强,就是我们用「后一轮」的用户反馈结果来「评估」「前一轮」效果,比如上图,我们用下一轮的推荐结果来看跟上一轮的结果的效果,当然这里有一个大的问题,用户想要的小于用户随意看的小于用户看得到的,用户没看到的肯定他无法表达想要给予正反馈,所以很多公司会在这里给予random,这个细节我们后面几页ppt再做探讨,假设无影响的情况下,这算是一个「自洽的评估方式」,当然应该会有更合适的评估方式。当我们有了一套合适的评估方式,那我们就可以期待离线的数据提升可以大概率带来线上的效果提升,如果发现离线评测效果提升明显,但线上效果不显著,可以「排查特征和用户分布是否出现很大不一致」。
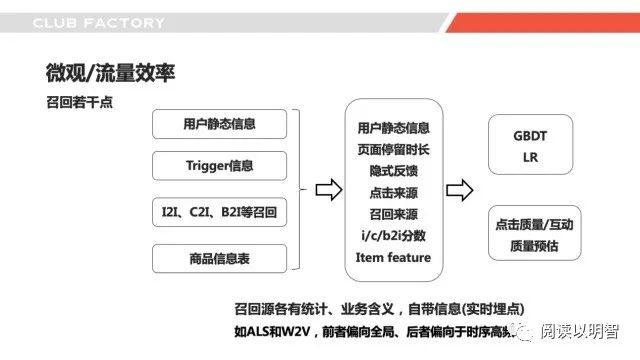
▌4.4微观-召回要点
这里我们根据召回模块进行细粒度的拆解,我们不过多介绍类似如何利用word2vec或者als计算i2i的逻辑,这里介绍一下「召回源的融合」,包括i2i、c2i、tag2i等,不同的场景不同的迭代阶段也会有不一样的逻辑,可以离线融合也可以在线融合。
这里介绍离线重一些的模式,线上只做查询,不做融合。首先我们需要一些信息,比如用户的静态信息,包含了用户国家、性别、设备等,这个的出发点是不同的人其实也会有差异,i2i召回的时候可以用用户静态信息加item_id进行召回;trigger信息,在商详可能是商详的主商品,在个性化推荐场景则可能是用户的行为,trigger可以包含商品id,也可以包含行为时间,也可以包含行为类目;召回源信息,则是这个商品来自于word2vec、als还是swing,不同的召回源会有不一样的业务假设,这里面的信息量也比较多,比如ALS和W2V,前者偏向全局、后者偏向于时序高频,当然这些可能需要结合埋点,需要将召回逻辑埋入日志,供提取数据和特征;商品信息则好理解一些,就是商品的静态、动态特征,比如类目、点击率、转化率等。下一步就是通过用户真实的反馈进行数据、特征的构建,配合不同模型的选取来进行融合预估。
这里我想讲的是其实光召回侧,其实我们就可以在性能范围内进行多维度的考虑,尽量满足我们对于这个模块的诉求,最终类似BP的思路,既要正向流转,又要反向传播,把误差往前传修正前置的依赖。保留「越多的信息」越好,数据收集的「越仔细」越好。
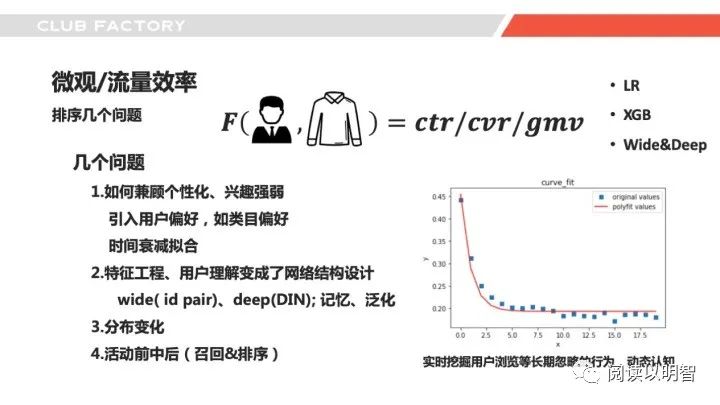
▌4.5微观-排序模块拆解
讲完召回我们再讲讲排序,排序我们也是按照业界的常规思路,尝试了lr、xgb、wide&deep等模型,这里面挑了几个问题点来讲,这里的工作集中在「数据清洗」构建「契合实际场景」的样本,构建丰富的用户、商品、上下文特征来预估点击率、转化率。
「第一个」讲的问题就是「个性化问题」,个性化元素是比较重要且核心的一个点,如何将个性化做到恰到好处,根据兴趣强弱影响整个排序结果是一个可以探讨一下的点,比如我们可以将用户兴趣落到具体的类目、品牌、标签上,然后在做完点击率、转化率预估后,将个性化分在最外层与两者融合,也可以作为特征放入排序模型中,这里的方法是通过一层「建模对用户兴趣进行了降维表达」,具有可解释性,但也会「丢失一定的信息」。还有一种方式其实就是将用户行为序列作为特征放入模型,通过「网络结构去学习用户偏好」,比如din,通过类似gru这种rnn的结构进行兴趣建模,后期的dien也是类似的诉求。前者其实就会涉及如何构建合理的衰减因子,其实就是捞取用户真实的行为,拟合其兴趣偏好的冷却过程,这就是依赖人做了一些工作,但是效果还不差,至少在推荐系统演进的初期,是一个快速拿结果的方式。这种方式比较千人一面,具有统计泛化的同时就丢掉了个性。还有就是我们在迭代过程中,如何通过构建wide模型来完成deep模型的结构,比如我们可以将用户对某个商品的点击与否,结合时间节点前的点击序列构建特征,比如对a点或者没点,在这个反馈行为前用户点了c,d,e,则特征就可以是a&c、d&c、e&c的id pair对构建 one hot作为特征,比纯id特征就可以构建用户兴趣,其实也有一些i2i的意思。din就不过多解释了。「记忆和泛化」是两种方式,都可尝试。
这里为什么讲个性化,因为这个是一个重要的因子,也是现在很多模型都去构建相关的网络结构对其进行建模的初衷。
「第二个」排序中想讲的问题就是「分布变化的问题」,前面讲了推荐的召回和排序等等模块会影响用户看到的,然后用户看到的又会影响用户的反馈,用户反馈又会影响样本分布,就会影响模型,循环了,那怎么去解决呢,这里尝试可以尝试引入随机因子,「完全随机和部分随机」,保证预留一定的空间可以让分布更加自然,当然这里面有很多学问,需要考虑和平衡。我举个我们遇到的问题,比如i2i召回很依赖用户的行为序列,看了又看的pair对数据,当大促期间,某些折扣商品会有较大的曝光,然后也就影响了看了又看,整体i2i就因为折扣因子影响,噪声带来了i2i的不稳定,如何平衡也是可以持续研究的。类似的商品折扣在活动中和活动后都会影响排序,因为大部分模型在排序特征中会利用商品的历史点击率,这时候往往会「低估」商品的流量效率,活动后则会「高估」。并且有时这部分商品可能没有召回,更加没法排序了。这时候我们可能需要引入「实时特征、在线学习、流量调控」等手段,历史的表现作为先验,结合实时特征和表现,进行流量调控,折扣的力度可以作为初期流量分配多少的「依据」。总之推荐是一个系统,要具有「鲁棒性」。
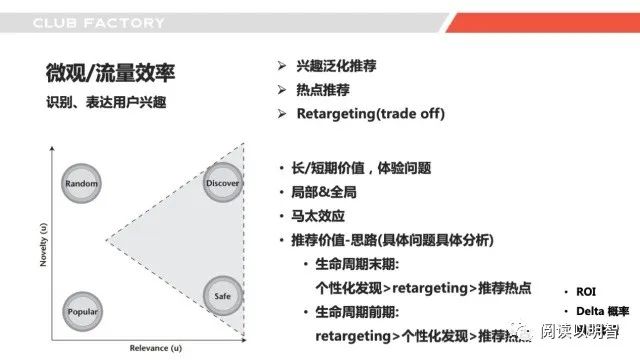
▌4.6微观-用户兴趣识别与表达
接下来我们再来探讨一下识别和表达用户兴趣,这里面其实在推荐召回来说也是三种召回形态,兴趣泛化的召回、热点的召回、retargeting召回,兴趣泛化可以是类目、标签维度的,在看牛仔裤的用户推荐类似的牛仔裤,在看连衣裙的推荐类似的连衣裙,热点就是热门,retargeting其实就是交互过商品的召回,比如用户收藏、加购了某个商品,还是推荐这些商品,三者在推荐场景中均有不错的收益,前面两个比较好理解,最后一个retargeting也比较有用,常常在推荐和push中使用,尤其是个性化推送,作为规则触发有不错的收益。在某些推荐产品、业务、时间节点中其实非常有用,比如电视剧这种长视频推荐场景、比如双十一当天尤其。但是如果我们仔细想想,其实这种推荐也会存在「流量浪费和体验差」的问题,并且这里对用户的兴趣探索也有伤害。比如电视剧场景,你不推《庆余年》,用户可能也会在其它场景看到,你各个场景都去推,重复会非常多,第二个收益不大,但是如果是生命周期的初期,刚开始看,其实这个收益就会更大,生命周期的末期,我们需要评估用户行为延续性和留存,我们希望能在用户离开前找到下一个可以留下的剧。这中间需要平衡用户快速找到信息的体验和用户兴趣探索延续的任务,比如我们可以建模一个「delta收益」,ratargeting的用户收看的概率减去不做召回用户收看的概率,或者「全场景的推荐策略信息透传、串联」去构建全局的收益。

▌4.7微观-场景串联&用户旅程
这也就是我下一页ppt想讨论的,我们首先得在「产品心智和业务诉求」层面先对推荐产品进行功能划分和作用识别,我们希望商品list页中搜索可以更强调收敛,首页可以强调发散,但是也可以根据用户「意图的差异进行策略的切换」,比如搜索iphone 6s 128g 黑色就是非常强的意图,如果只是裙子则意图较弱,可以相对发散让用户有一定的选择空间,首页类似,搜索根据搜索词走,首页跟着用户行为序走。同理下面的各个场景不做过多的讨论。
最终我们也可以通过技术手段实时地识别用户的旅程,然后根据旅程在各个推荐场景进行推荐策略的调整,来「最大化全局收益」。

▌5.1系统&全局生态-方向与外围
最后我们讨论几个大一些的问题,我们公司也在尝试解决,公司维度有几个大的目标。
第一个是「生态闭环」,商家流量和成长的平衡,流量分配,运营机制,我们需要引入更多的商家提供更多的商品和服务,这时候新入驻的商家我们需要给予一定的流量带来出单,保证一直有新鲜血液融入其中,同时我们也希望好的商家有更多的流量,保证他们保证他们有足够的利益,建立更强的对「平台依赖」。平台维度希望用户的回访、复购更好,带来更高的LTV,这中间就是需要建立netgmv的诉求,我们希望逆向更少,正向是商品从商家流进用户,逆向是用户不满意拒收、退货等。如果当天卖了100件,几天后退了80%,那其实net gmv异常的低,这不是我们想要的,这种优化更加「偏长期」,更加「多因子」。
第二个是「商品理解和建设」,我们会通过一些站外和友商数据对我们的新品进行预估,是否会在平台卖爆,当我们现在有100w商品的时候我们知道展示的优先级,并且结合一些bandit的算法进行高效的新品测试。这时候在推荐过程中,商品维度的explore时可以更加高效。这中间就是典型的「双边市场」,越丰富的商品带来更大的选择空间,带来越好的体验,转化就会变高,持续的流量也大,这时候商家也会有更多的收益,吸引更多的商家加入,最终带来「良性循环」。
第三个是「用户理解、智能投放,低延时高效展现」,这里面很多在前面有一定的介绍不做过多的介绍

▌5.2系统&全局生态-多目标
「视觉窄化」最近谈论比较多,刚好结合这页ppt讲讲,就是我们会遇到很多问题或者目标,这些目标大逻辑都在围绕「用户、商家、平台展开」,大循环是三者的,每个模块内部也会有很多问题,比如用户维度的视觉窄化和平台维度马太效应类似,如何缓解这些问题,我的建议是初期就尽量「top down」的思考整个问题,尽量从三个角度都建立「一套评估指标」。并在各种产品、算法、业务迭代中如观察或者甚至「融入这些指标」,只要指标设立的是正确相对「全面」的,那么跑起来后就是「健康」的。当然这不仅仅是个「技术活」,也是个「艺术活」,不是纯技术范畴的事情。我们公司也在摸索尝试中,目前有一些收益。

▌6.1几点总结
最后做几点总结
第一点,「业务效果好的算法不一定是复杂算法」,基于假设、分析后的策略迭代开发评估才会带来好的效果。包括系统地思考整个架构和体系,不要虎头蛇尾的优化局部模块
第二点,我们要时常「回顾案发现场」,增加埋点,将整个推荐策略中黑盒的埋进去,比如某个商品展现给用户,他从哪个召回源来的,用户当时的行为偏好是怎么样的,这个召回源的效果如何,都可以从埋点中溯源,并且还可以作为模型的特征
第三点,迭代思路上我有一个觉得非常不错的点,就是「逆向看」,比如我们可以去溯源每个场景高流低转的商品,结合第二点的埋点,去分析他是来自于哪个召回源,经过怎么样的排序,最终展现给用户的,可以便于我们排查定位问题。
第四点,「全局收益」,场景打通了看,平衡局部最优和全局最优,举个例子就是往往很多产品在推荐的初期,个性化场景非常相似,因为都是根据用户的行为,利用现有最优的模型进行排序,往往结果相近或者类似,但是忘记了用户购物需求很多时候是有上限的,不会因为你推荐的好我就会买很多,有些场景应该重短期转化有些场景应该重回访、复购等长期指标,最终构建接近全局最优的推荐方法论。
第五点,最重要的就是建立合理的指标,推荐、搜索、广告等等都是子系统,我们得建立生态维度更加健康的指标。方向比努力更重要。
好了,今天的分享就到这里,感谢各位的聆听,谢谢。

其它文章资源
姚凯飞:推荐&搜索&广告&用户画像&深度学习整理
zhuanlan.zhihu.com 姚凯飞:万字长文解读电商搜索——如何让你买得又快又好(5篇合集)
zhuanlan.zhihu.com
姚凯飞:万字长文解读电商搜索——如何让你买得又快又好(5篇合集)
zhuanlan.zhihu.com 姚凯飞:数据算法改变世界-电商相关应用介绍
zhuanlan.zhihu.com姚凯飞:校招没有讲的话-送给快毕业的同学
zhuanlan.zhihu.com
姚凯飞:数据算法改变世界-电商相关应用介绍
zhuanlan.zhihu.com姚凯飞:校招没有讲的话-送给快毕业的同学
zhuanlan.zhihu.com
以上是关于推荐系统背后的冷思考的主要内容,如果未能解决你的问题,请参考以下文章