推荐系统主流召回方法综述
Posted 浅梦的学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统主流召回方法综述相关的知识,希望对你有一定的参考价值。
“ 本文主要梳理了近年来推荐系统中的主流召回方法,包括传统召回方法,基于表示学习的方法(Youtube DNN,DMF,DSSM,item2vec,graph embedding,MIND,SDM等),以及基于匹配函数学习的方法(TDM,NCF等),非常适合大家学习!”
前言:
传统召回方式与新式召回在业务中互为补充,传统召回(主要是cb和cf方法)往往是最直接的,成本最低的,效果非常显著的方法. 不过出于技术探索的原因, 笔者后面会只介绍一些相对“高阶”的方法, 权当抛砖引玉了.
1 Youtube DNN
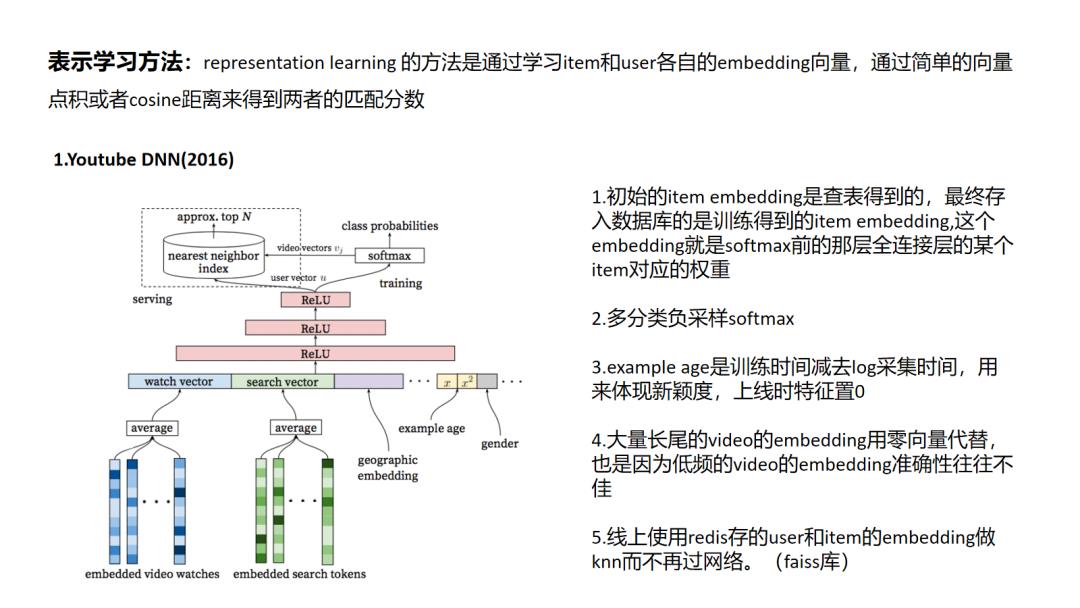 当前的主流方法的通用思路就是对于use和item的embedding的学习, 这也被称为表示学习; YoutbeDNN是经典的将深度学习模型引入推荐系统中,可以看到网络模型并不复杂,但是文中有很多工程上的技巧,比如说 word2vec对 video 和 search token做embedding后做为video初始embedding,对模型训练中训练时间和采集日志时间之间“position bias”的处理,以及对大规模多分类问题的负采样softmax。
当前的主流方法的通用思路就是对于use和item的embedding的学习, 这也被称为表示学习; YoutbeDNN是经典的将深度学习模型引入推荐系统中,可以看到网络模型并不复杂,但是文中有很多工程上的技巧,比如说 word2vec对 video 和 search token做embedding后做为video初始embedding,对模型训练中训练时间和采集日志时间之间“position bias”的处理,以及对大规模多分类问题的负采样softmax。
2 DeepMF
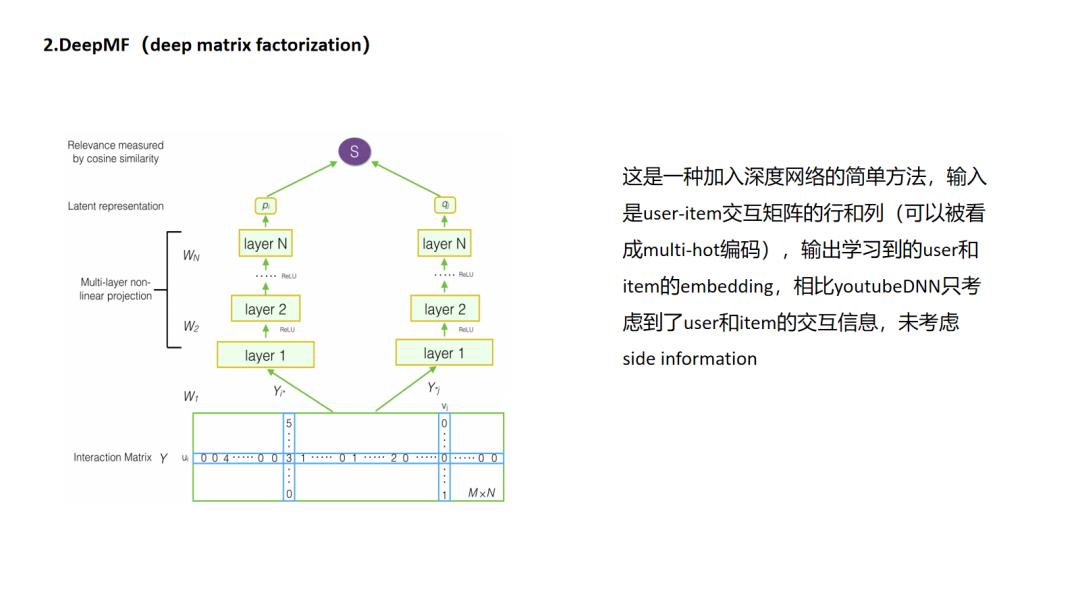 Deep MF方法与传统矩阵分解方式中的谈到的“分解”其实是有些区别的.如果把推荐视作填充矩阵的任务的话,传统MF的分解是把m(用户数)× n(物品数)的矩阵分解成m×k大小的用户抽象矩阵和n×k大小的物品抽象矩阵的乘积,实现把物品和用户分别映射到k维隐空间的目的. 而deepMF则使用了另外一种得到k维隐向量的方式,即先把用户交互矩阵分解出代表用户的行和代表物品的列,用一个NN模型去学习用户行和物品列的隐式表达.
Deep MF方法与传统矩阵分解方式中的谈到的“分解”其实是有些区别的.如果把推荐视作填充矩阵的任务的话,传统MF的分解是把m(用户数)× n(物品数)的矩阵分解成m×k大小的用户抽象矩阵和n×k大小的物品抽象矩阵的乘积,实现把物品和用户分别映射到k维隐空间的目的. 而deepMF则使用了另外一种得到k维隐向量的方式,即先把用户交互矩阵分解出代表用户的行和代表物品的列,用一个NN模型去学习用户行和物品列的隐式表达.
3. DSSM
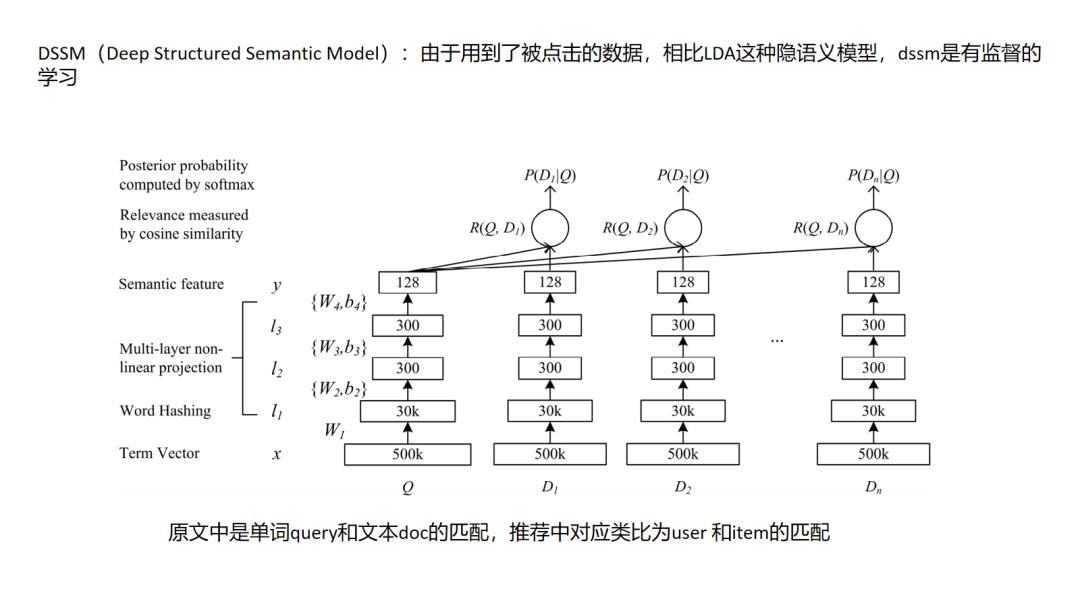
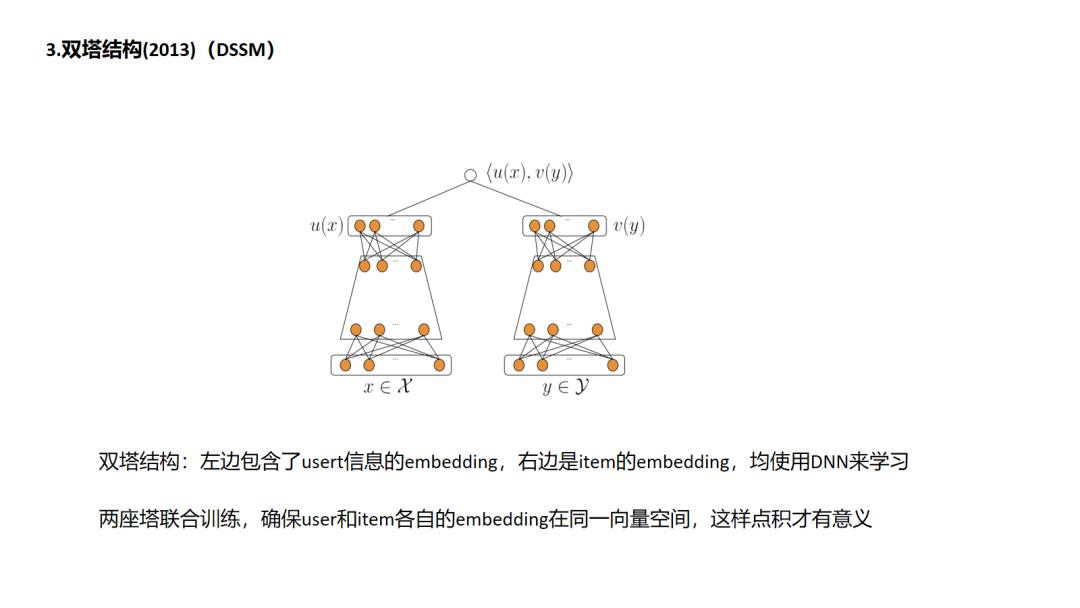

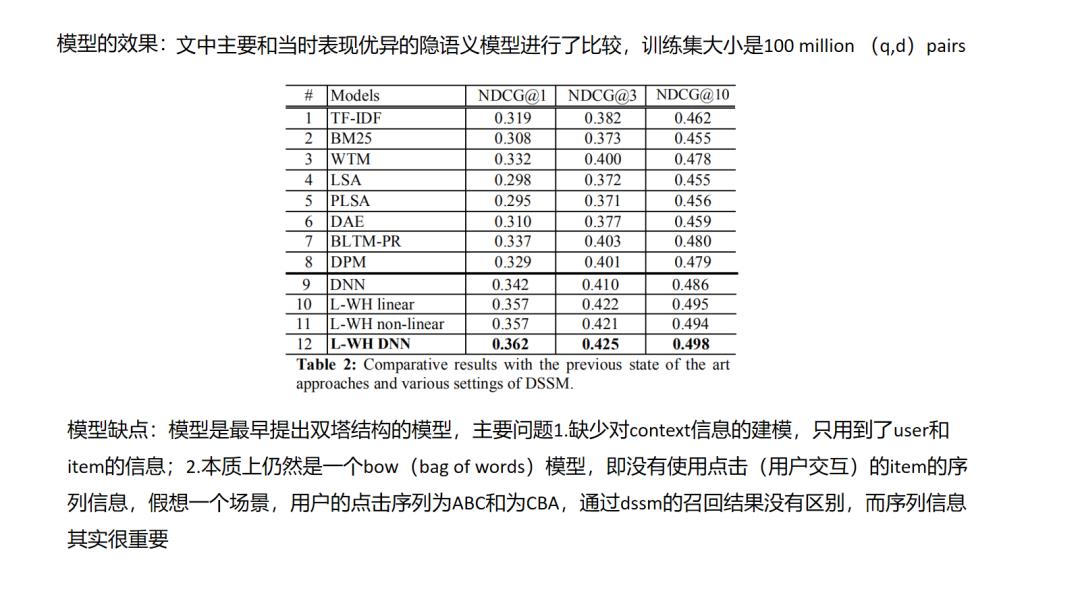 双塔结构DSSM是应用十分广泛的深度方法,搜索场景中,点击的日志中包含了用户搜索query和用户搜索当前query下点击的doc,以此来构建正样本,对每一个正样本(query,doc)对,随机选择一些该query下曝光未点击的doc构建负样本,属于有监督信息的学习,同时注意的是对于每一座doc塔的参数是共享的.在DSSM的基础上演化出一些有用的变种,如MV-DSSM,融合不同域的特征进行学习.
双塔结构DSSM是应用十分广泛的深度方法,搜索场景中,点击的日志中包含了用户搜索query和用户搜索当前query下点击的doc,以此来构建正样本,对每一个正样本(query,doc)对,随机选择一些该query下曝光未点击的doc构建负样本,属于有监督信息的学习,同时注意的是对于每一座doc塔的参数是共享的.在DSSM的基础上演化出一些有用的变种,如MV-DSSM,融合不同域的特征进行学习.
4.Item2vec

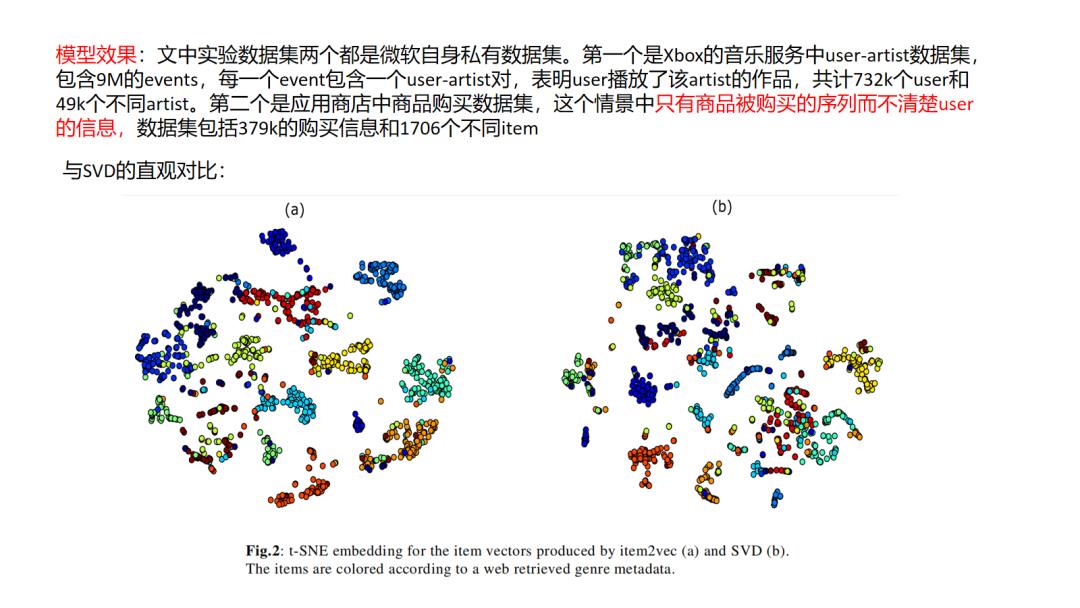
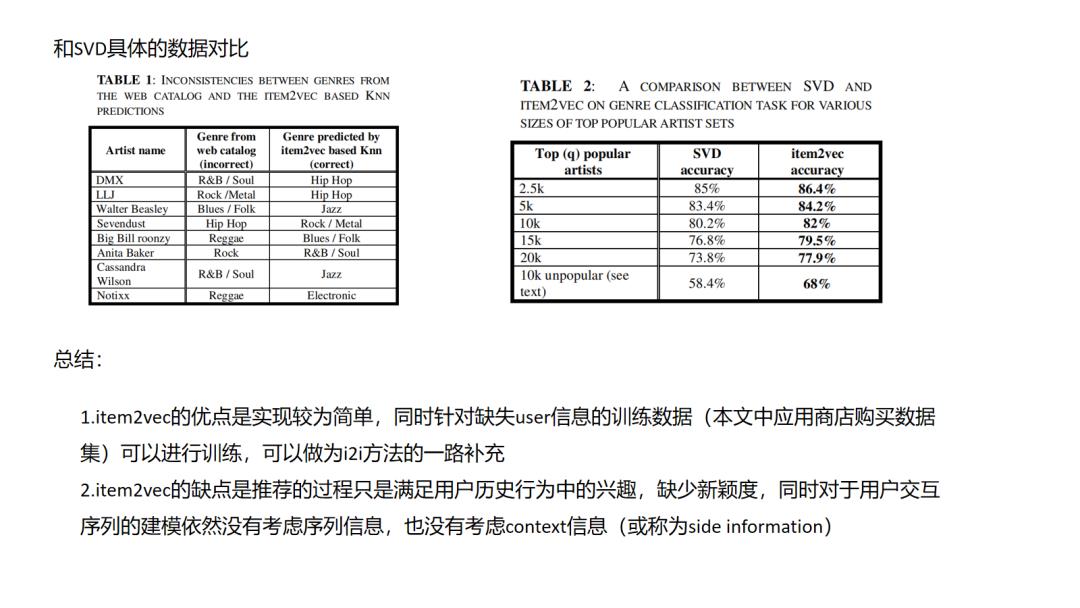 本质上来说item2vec是一种利用item彼此共现信息的缺少监督信息的学习,它的一个隐含假设是同一个session中共现的item往往是相关的,可以被互相推荐的,但实际场景中,们需要思考这种先验是否能够满足,比如session序列中是否存在多兴趣行为导致共现的item其实并没有什么联系,再比如session划分的依据该如何权衡,划分过长势必会引入不相关的item成为噪音,划分过短又会降低item在不同session序列中出现频率,也会对训练效果造成困难.
本质上来说item2vec是一种利用item彼此共现信息的缺少监督信息的学习,它的一个隐含假设是同一个session中共现的item往往是相关的,可以被互相推荐的,但实际场景中,们需要思考这种先验是否能够满足,比如session序列中是否存在多兴趣行为导致共现的item其实并没有什么联系,再比如session划分的依据该如何权衡,划分过长势必会引入不相关的item成为噪音,划分过短又会降低item在不同session序列中出现频率,也会对训练效果造成困难.
5.Airbnb Embedding

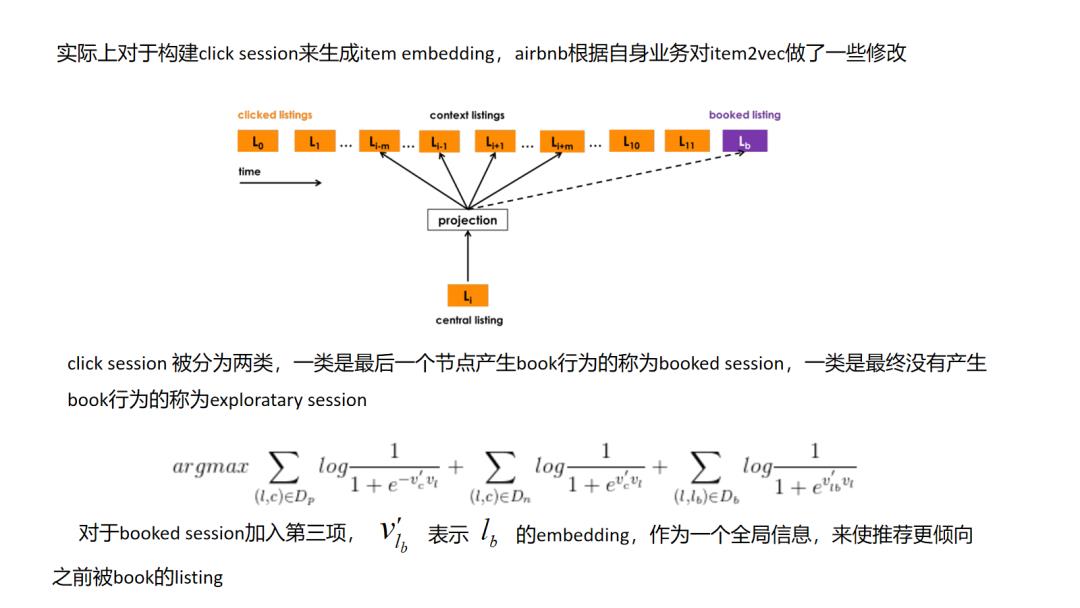
 airbnb embedding实际上是一篇针对item2vec方法,结合自己业务进行创新的方式,其中让我最惊艳的是对于book 序列稀疏性的处理,一个user_id并非我起初设想的对应一个user_type,而是在user长期的book历史行为中随着划分type的那些特征的改变而改变(比如我一年前用小米,现在用苹果,那我的user_type是改变了的),同时文中提到用(user_type,item_type)元组来表示一个节点,同时在训练的时候将元组扁平化成一种“异构”序列,达到在一个空间里学习user_type和item_type的目的,这个比一般item2vec方式有很大的创新,其让我想到了后面要讲到的类似node2vec和metapath2vec同构图和异构图的关系一样,让人耳目一新.
airbnb embedding实际上是一篇针对item2vec方法,结合自己业务进行创新的方式,其中让我最惊艳的是对于book 序列稀疏性的处理,一个user_id并非我起初设想的对应一个user_type,而是在user长期的book历史行为中随着划分type的那些特征的改变而改变(比如我一年前用小米,现在用苹果,那我的user_type是改变了的),同时文中提到用(user_type,item_type)元组来表示一个节点,同时在训练的时候将元组扁平化成一种“异构”序列,达到在一个空间里学习user_type和item_type的目的,这个比一般item2vec方式有很大的创新,其让我想到了后面要讲到的类似node2vec和metapath2vec同构图和异构图的关系一样,让人耳目一新.
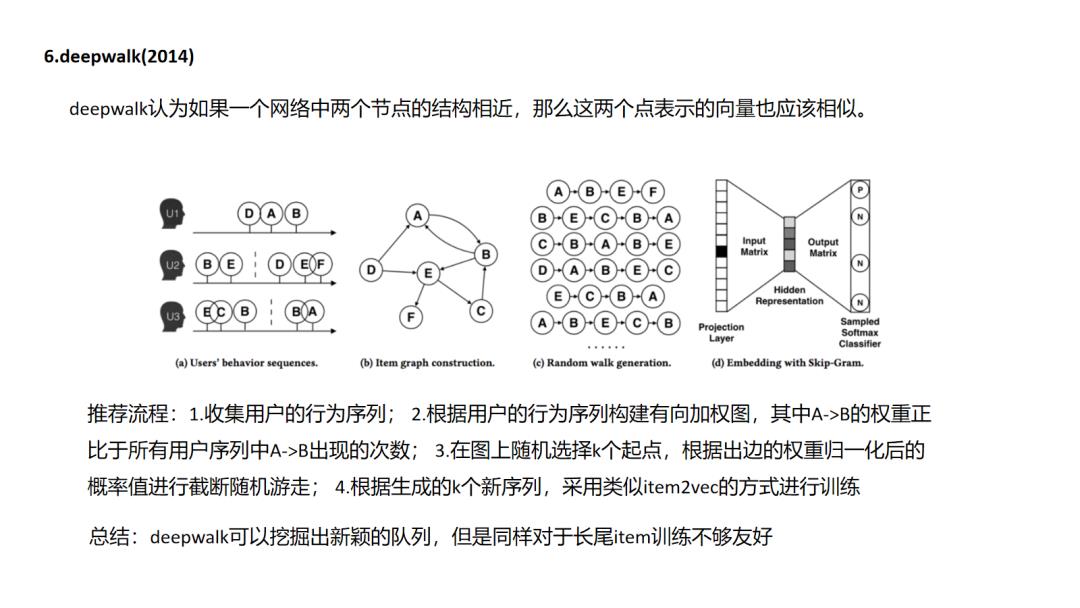
6.DeepWalk
7.Node2Vec
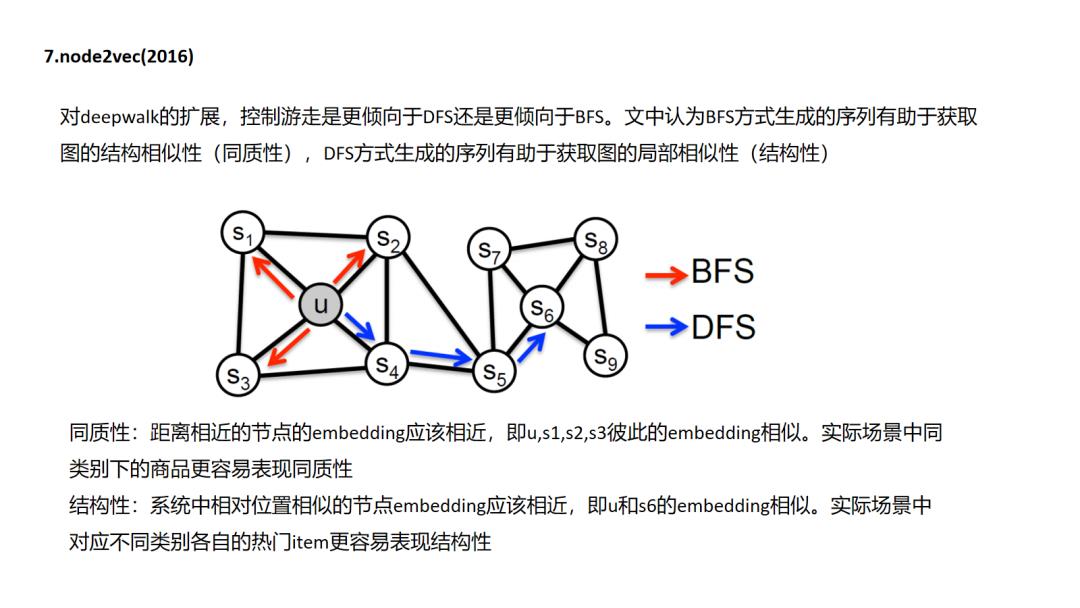
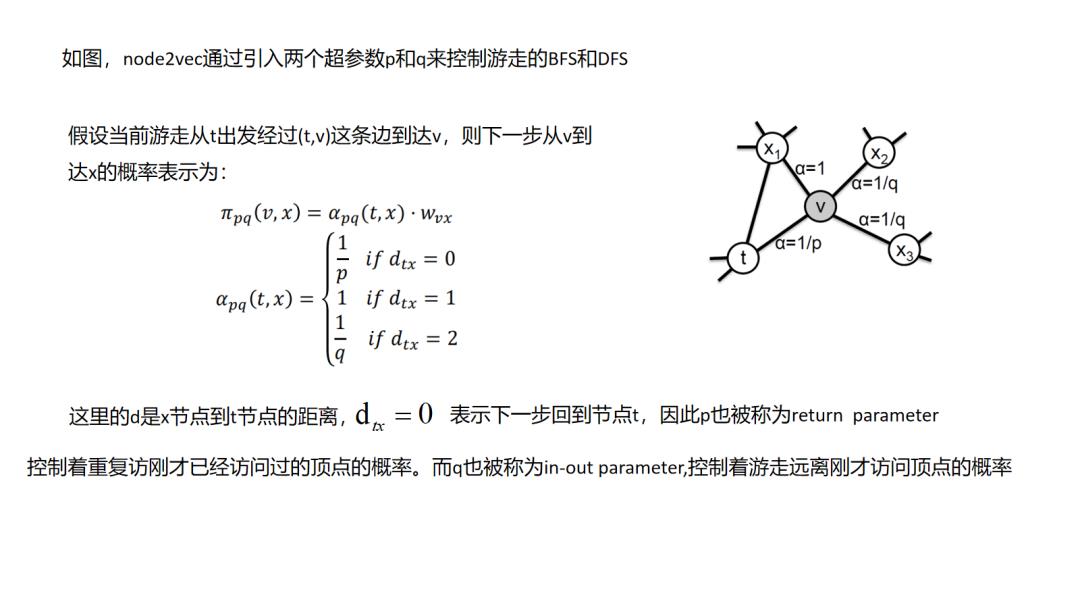
 deepwalk和node2vec其实就像item2vec一样都是基于“连接即可推荐”的先验的,这里面其实没有判断“推荐是否正确”的强标签信息,在item2vec中是通过两个item在多个session中共现次数的频率来体现item的信息的,而图随机游走embedding中是通过把这种共现次数编辑成边的权重,由边权控制游走概率来反映不同item的信息(这点很重要,设想一个场景中生成的图是一个各向同性的图,那么这个图是学不出来什么东西的).图中包含的信息一个是图结构的复杂度(连接是否稠密),一个是图的边权重(item之间共现频率分布是否有大的差异),因此在实际使用中,我们往往需要对自己的场景做上面两个维度的评估和调优.
deepwalk和node2vec其实就像item2vec一样都是基于“连接即可推荐”的先验的,这里面其实没有判断“推荐是否正确”的强标签信息,在item2vec中是通过两个item在多个session中共现次数的频率来体现item的信息的,而图随机游走embedding中是通过把这种共现次数编辑成边的权重,由边权控制游走概率来反映不同item的信息(这点很重要,设想一个场景中生成的图是一个各向同性的图,那么这个图是学不出来什么东西的).图中包含的信息一个是图结构的复杂度(连接是否稠密),一个是图的边权重(item之间共现频率分布是否有大的差异),因此在实际使用中,我们往往需要对自己的场景做上面两个维度的评估和调优.
8.EGES
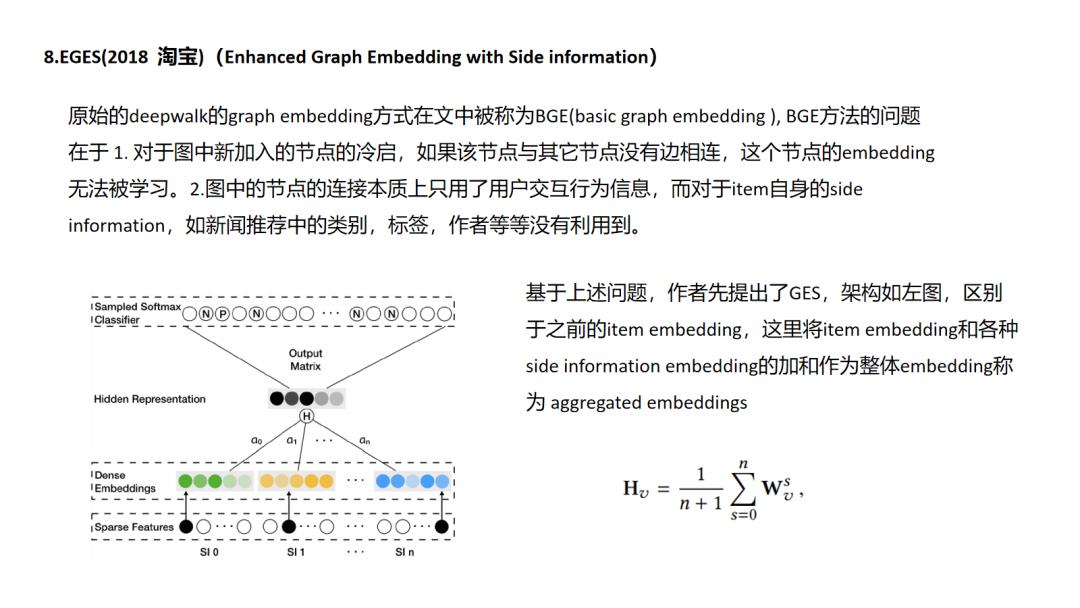

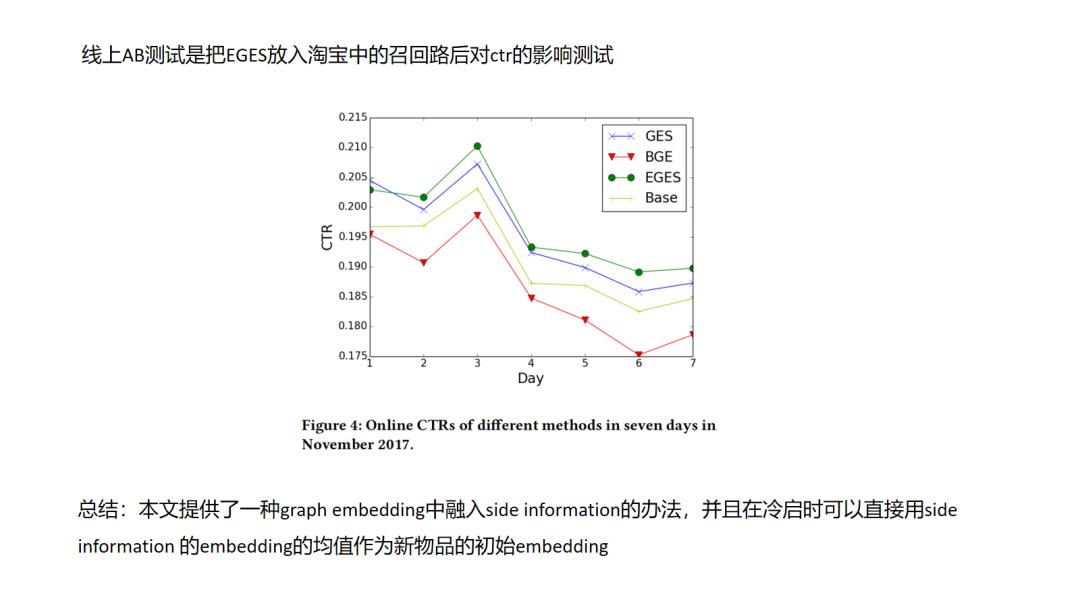 EGES主要两个创新点一个side information的融入,一个是attention机制,原始的graph embedding正如我前面说到的主要利用节点之间的共现信息,只是利用节点自身的id特征,那么像文中这样在得到id的图embedding之后如何与其它side information的embedding结合是一个很自然的想法.
EGES主要两个创新点一个side information的融入,一个是attention机制,原始的graph embedding正如我前面说到的主要利用节点之间的共现信息,只是利用节点自身的id特征,那么像文中这样在得到id的图embedding之后如何与其它side information的embedding结合是一个很自然的想法.
9.LINE
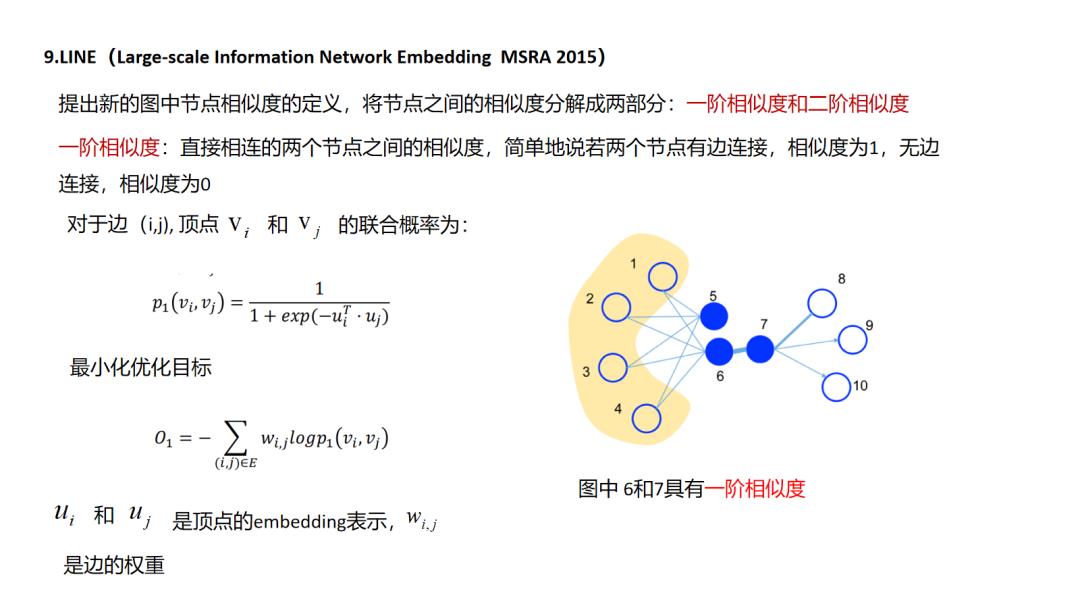
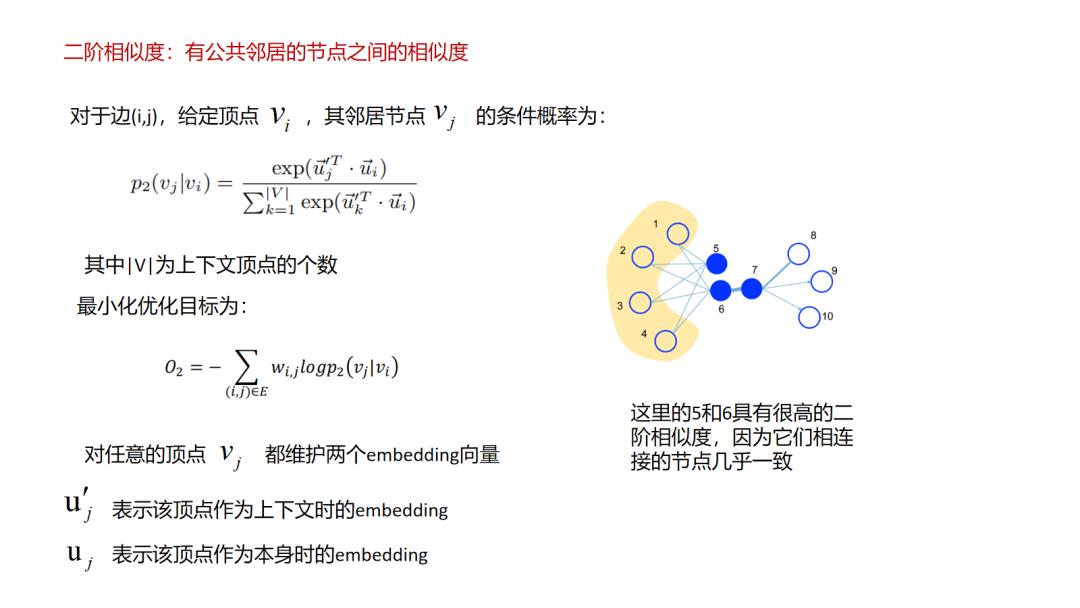

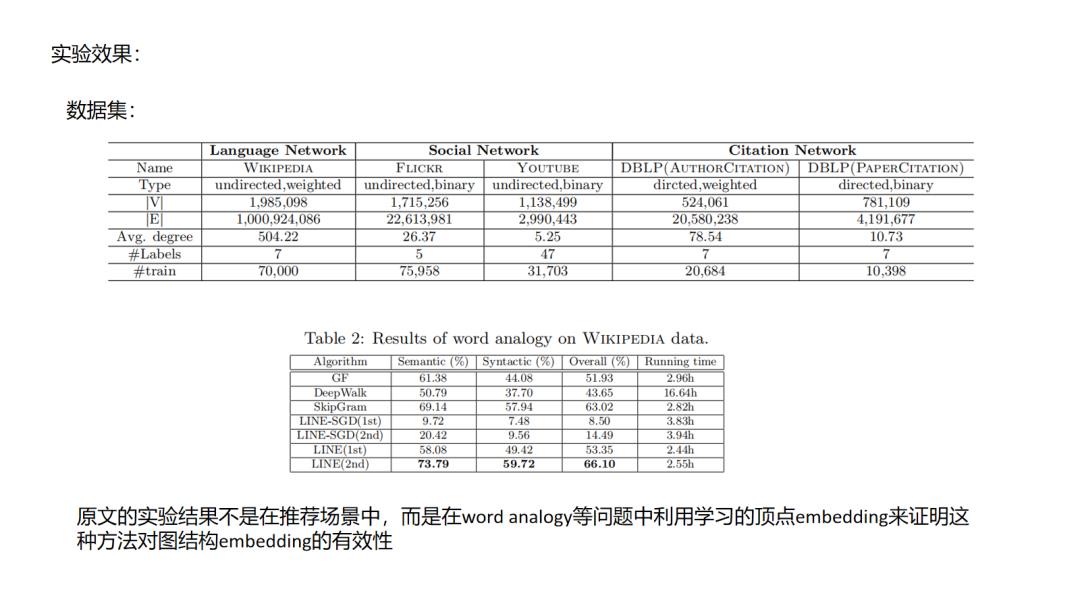 LINE方法其实是对前面所说的deepwalk这种emdedding使用“连接而推荐”的一种改进了,文中把这种直接连接的关系定义为一阶相似,引入了间接相连的二阶相似,这样的好处是提升了拓展性,使得原来不直接相连的节点也有了更直接的二阶相似度,类似的我们或许可以定义更高阶的相似性,但这样的问题就是推荐会变得发散,在如相关性推荐的场景中就会增加badcase的比例.
LINE方法其实是对前面所说的deepwalk这种emdedding使用“连接而推荐”的一种改进了,文中把这种直接连接的关系定义为一阶相似,引入了间接相连的二阶相似,这样的好处是提升了拓展性,使得原来不直接相连的节点也有了更直接的二阶相似度,类似的我们或许可以定义更高阶的相似性,但这样的问题就是推荐会变得发散,在如相关性推荐的场景中就会增加badcase的比例.
10.SDNE
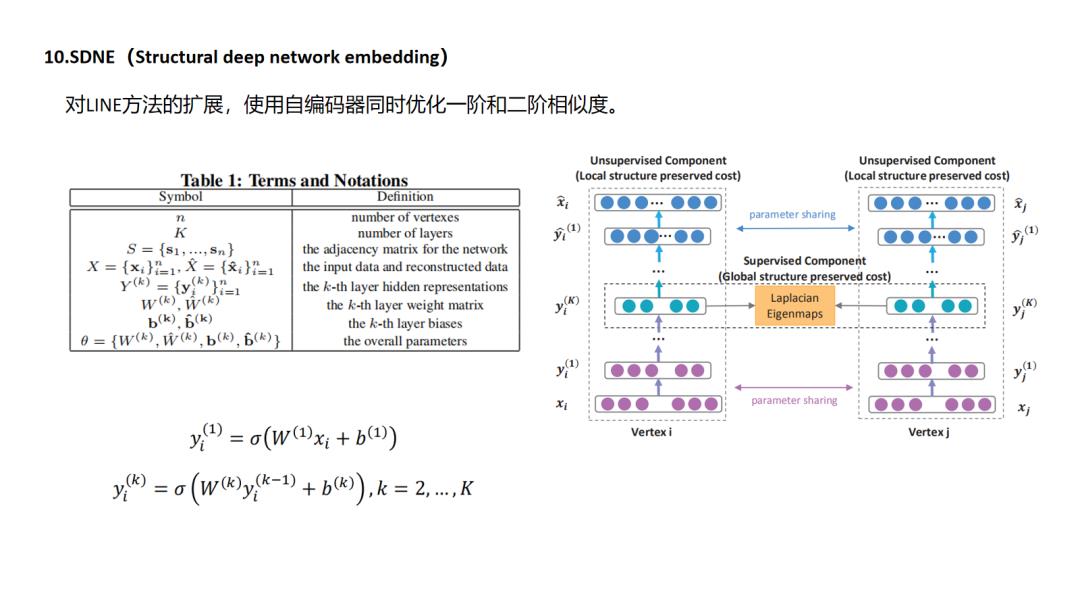
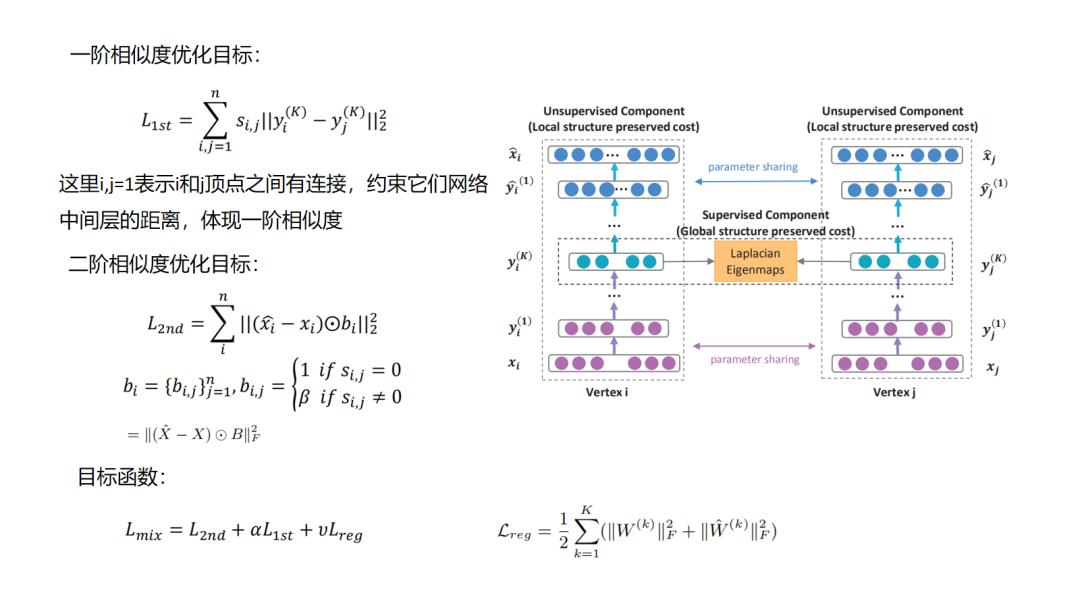
11.GraphSAGE
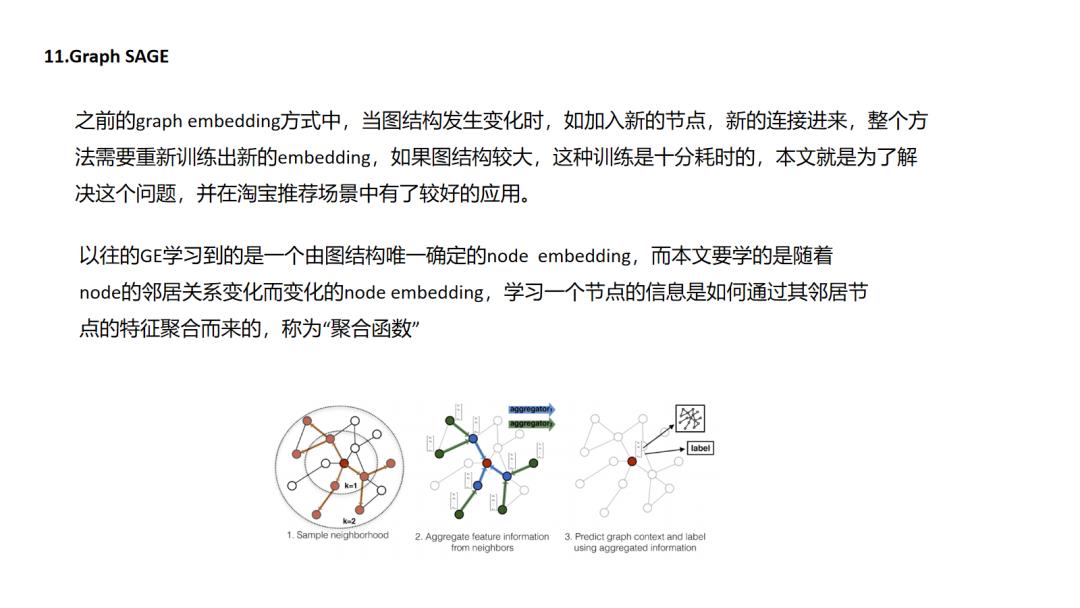

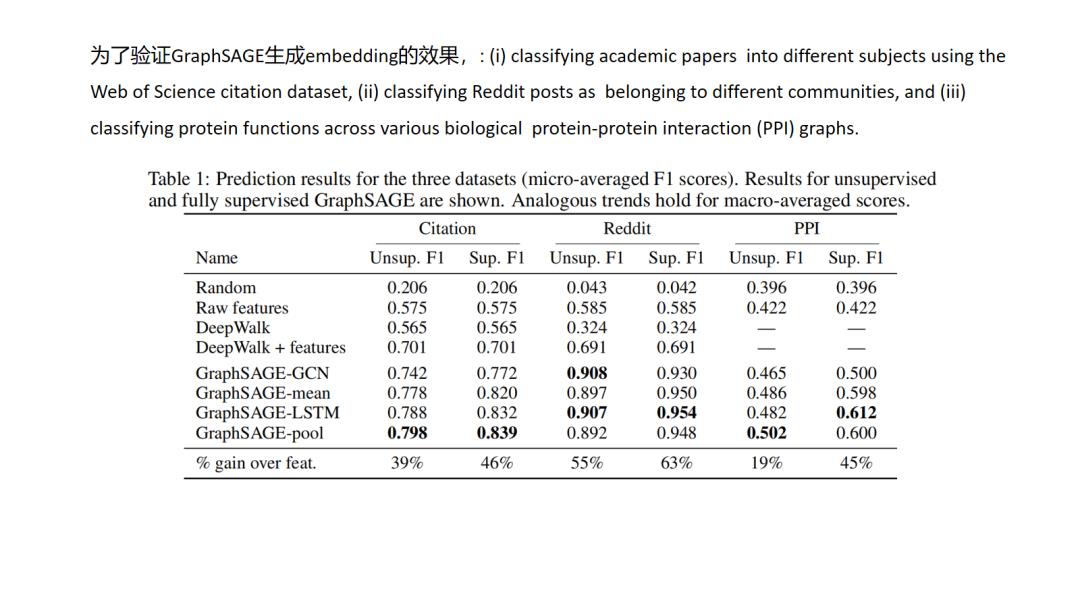 GraphSAGE非常惊艳的是转换了graph embedding问题的研究对象,以前我们是对节点建模,但是对于节点建模,而节点信息是依赖于整个图拓扑结构的,图结构的改动就会影响我们节点表征的结果,而本文则转换研究对象为对局部拓扑结构,通过学习局部拓扑结构与节点表征之间的映射函数间接的得到节点的表征,而实际场景中局部拓扑结构会相对稳定.
GraphSAGE非常惊艳的是转换了graph embedding问题的研究对象,以前我们是对节点建模,但是对于节点建模,而节点信息是依赖于整个图拓扑结构的,图结构的改动就会影响我们节点表征的结果,而本文则转换研究对象为对局部拓扑结构,通过学习局部拓扑结构与节点表征之间的映射函数间接的得到节点的表征,而实际场景中局部拓扑结构会相对稳定.
12.MIND


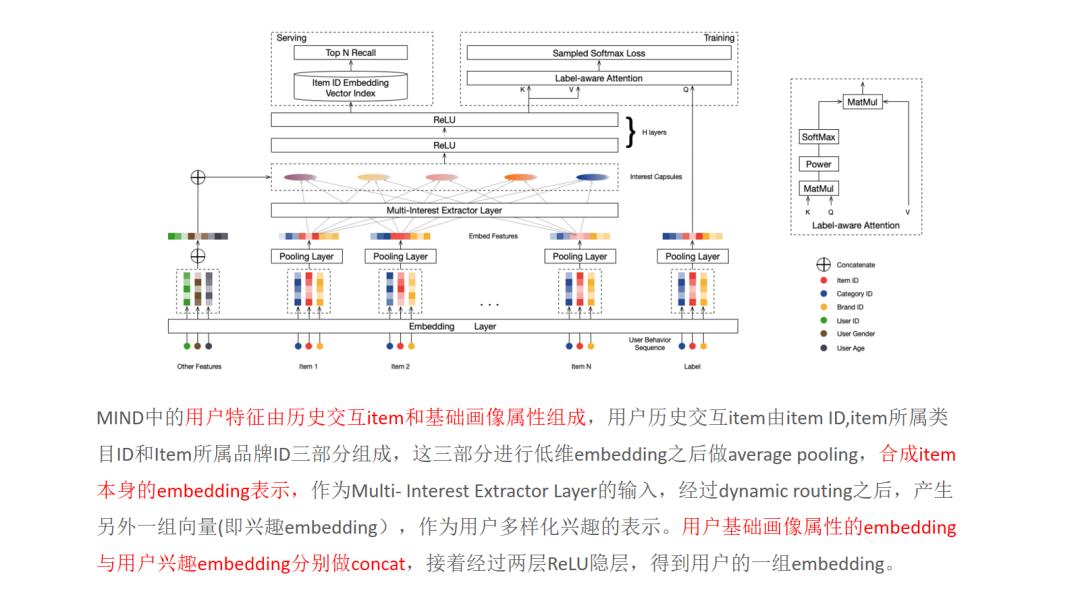
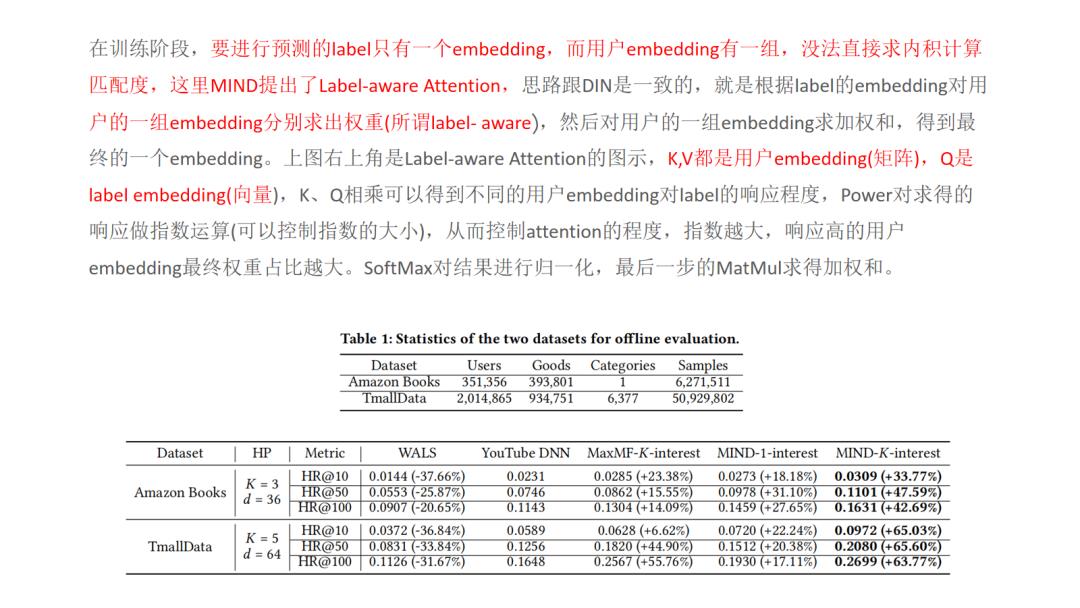
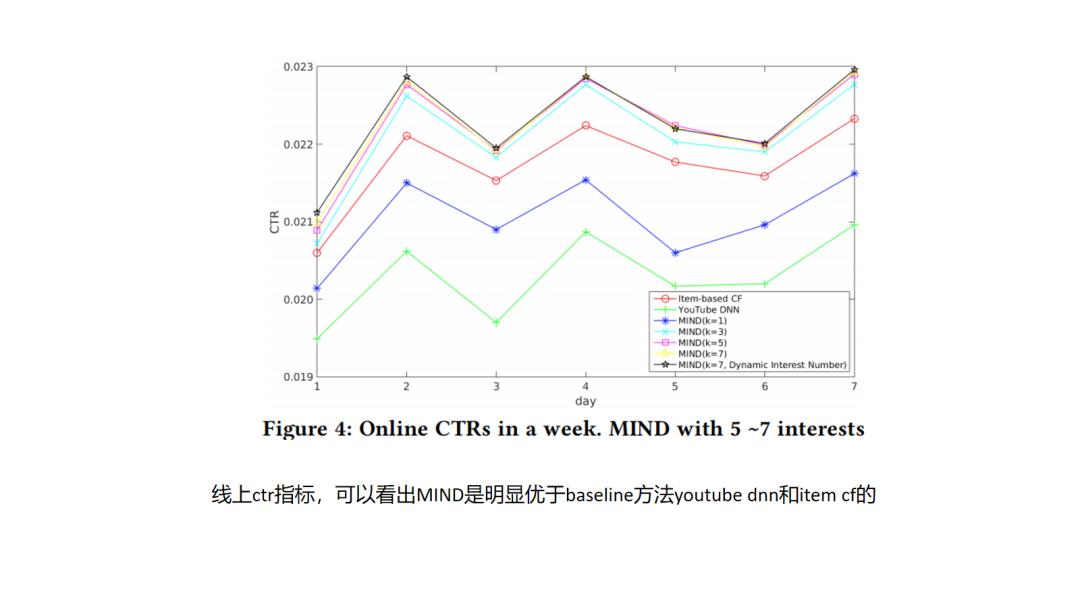
13.SDM

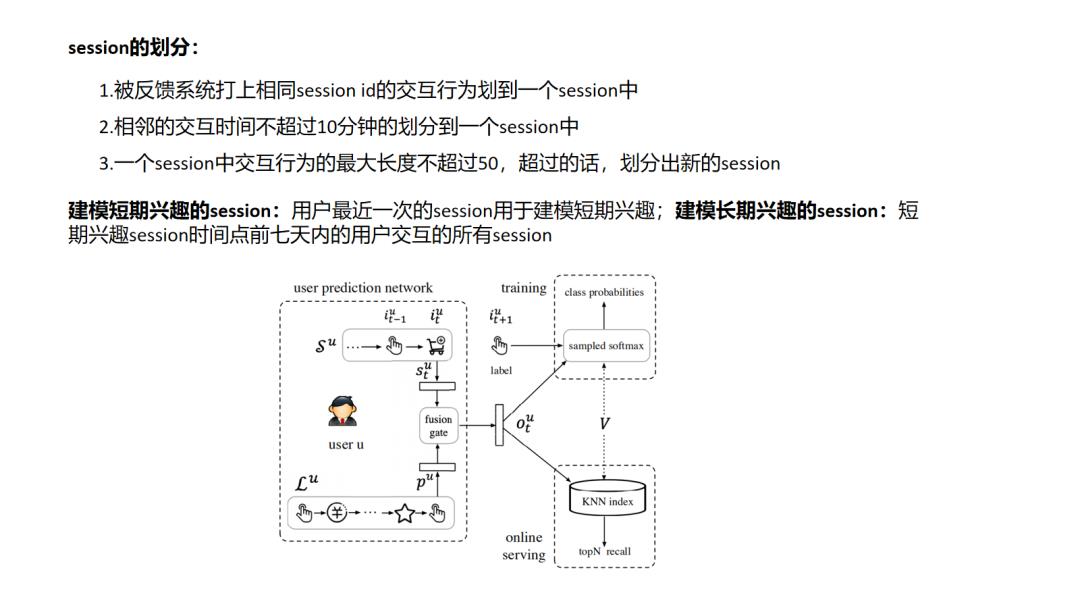
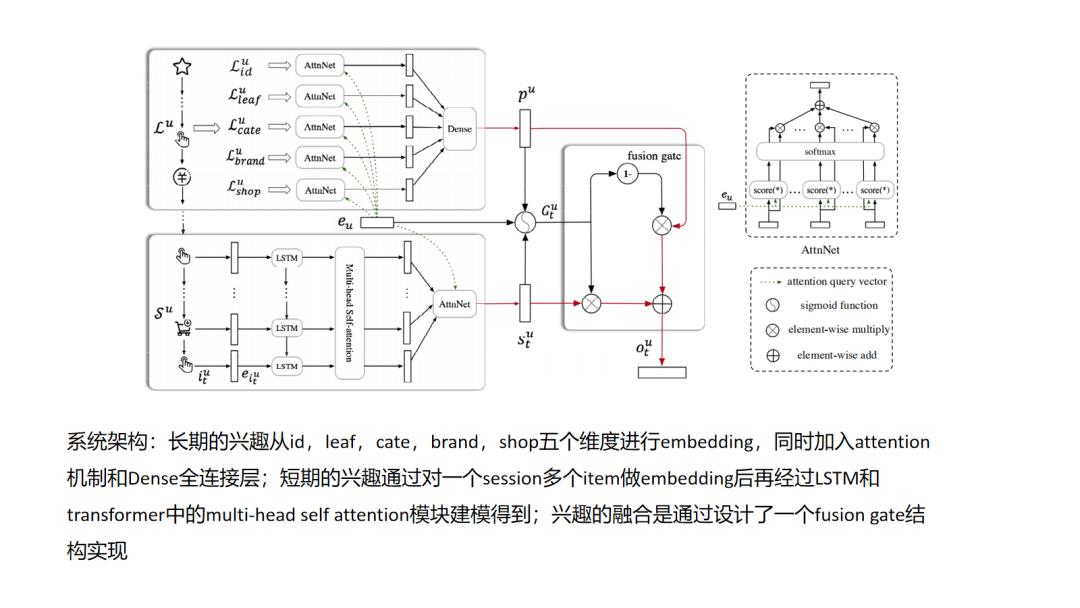
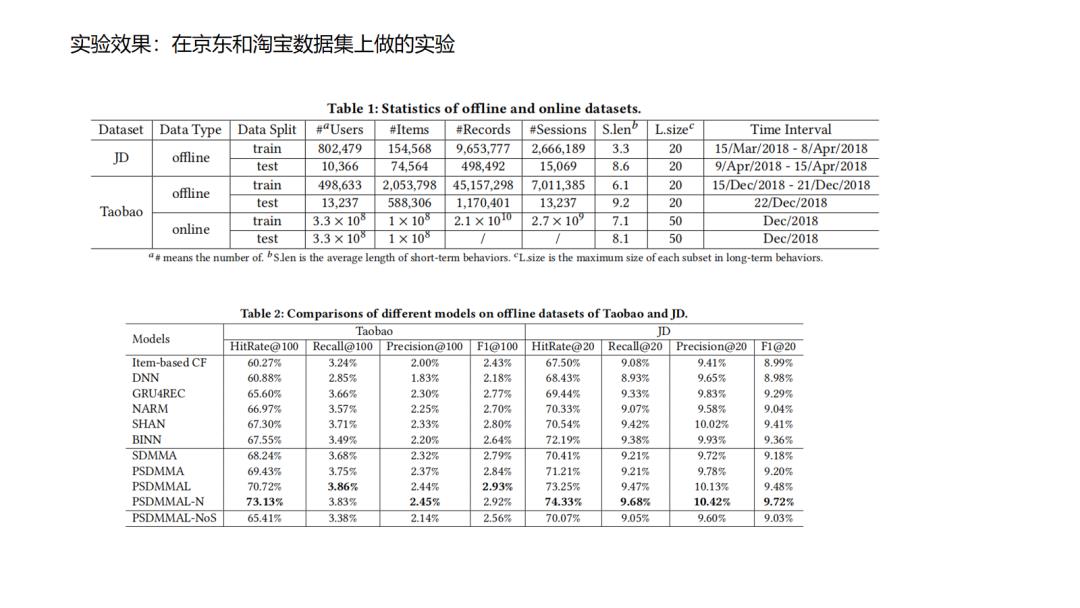
14.DeepFM

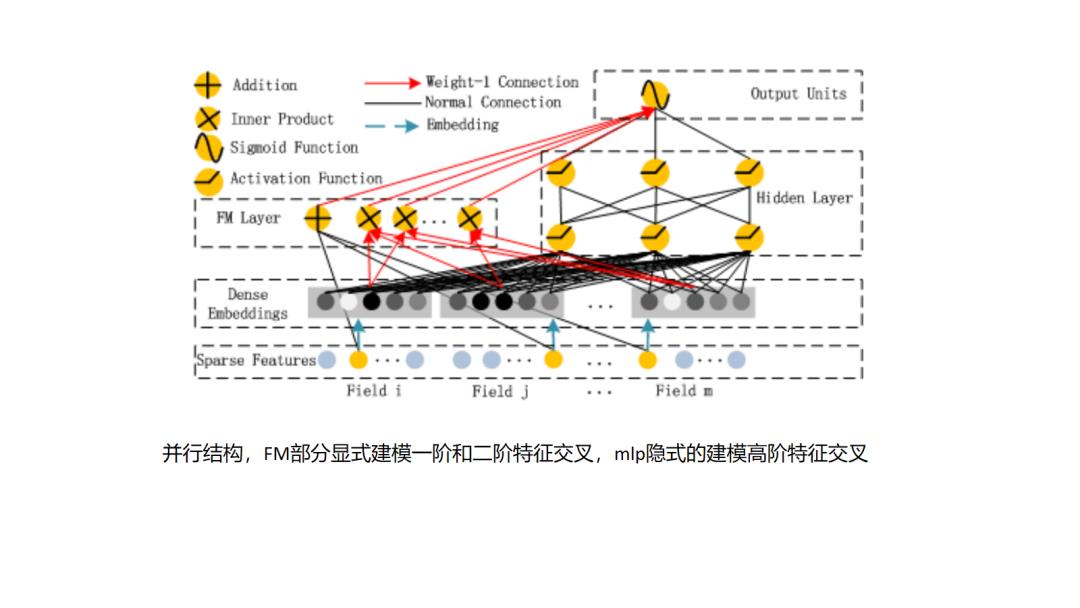 其实用FM或者说DeepFM做排序模型,大家是较为熟悉的,那么如何用FM或者DeepFM做召回有什么特别的地方,一般而言召回过程中FM可以不考虑user特征集合内部的特征之间的交叉,以及item特征集合内部的特征交叉,那么这样对于存入的user embedding 可以直接取user特征集合各个特征embedding的特征加和即可,item embedding直接取item特征集合各个特征embedding的特征加和即可,此时user embedding和item embedding的内积就已经体现了user特征和item特征之间的特征交叉,模型较排序使用的FM更为简化.
其实用FM或者说DeepFM做排序模型,大家是较为熟悉的,那么如何用FM或者DeepFM做召回有什么特别的地方,一般而言召回过程中FM可以不考虑user特征集合内部的特征之间的交叉,以及item特征集合内部的特征交叉,那么这样对于存入的user embedding 可以直接取user特征集合各个特征embedding的特征加和即可,item embedding直接取item特征集合各个特征embedding的特征加和即可,此时user embedding和item embedding的内积就已经体现了user特征和item特征之间的特征交叉,模型较排序使用的FM更为简化.
15.NCF
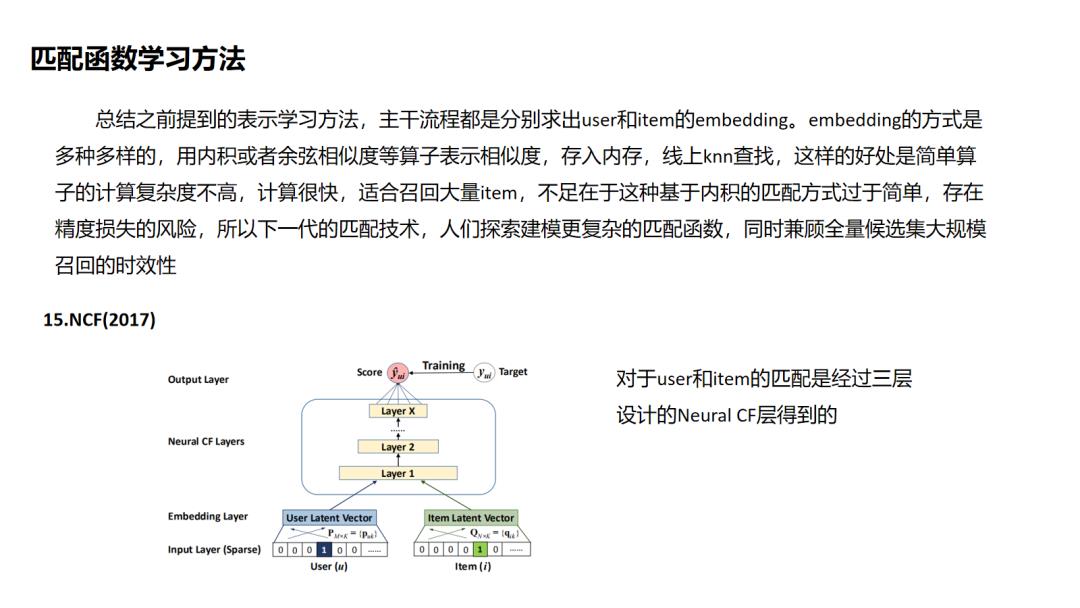
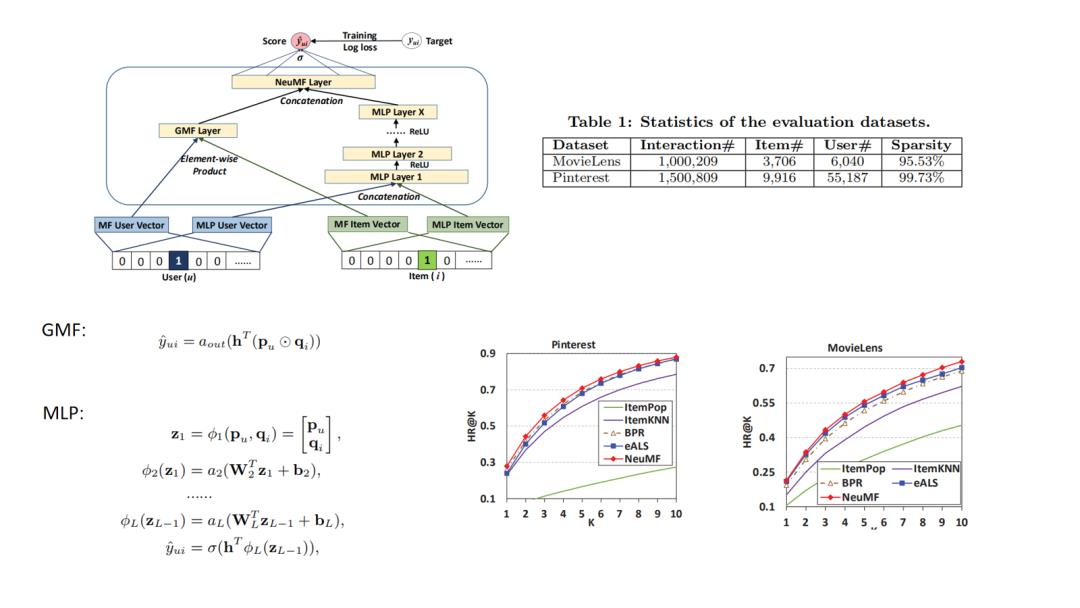 NCF是较早提出对于匹配函数进行学习的,它的技术难点是不能像基于向量内积召回方式的套路那样离线存储embedding然后线上最近邻召回,因此它的线上serving的时间复杂度成为一个痛点,这个问题在后面的阿里的TDM中提供了解决方案.
NCF是较早提出对于匹配函数进行学习的,它的技术难点是不能像基于向量内积召回方式的套路那样离线存储embedding然后线上最近邻召回,因此它的线上serving的时间复杂度成为一个痛点,这个问题在后面的阿里的TDM中提供了解决方案.
16.TDM
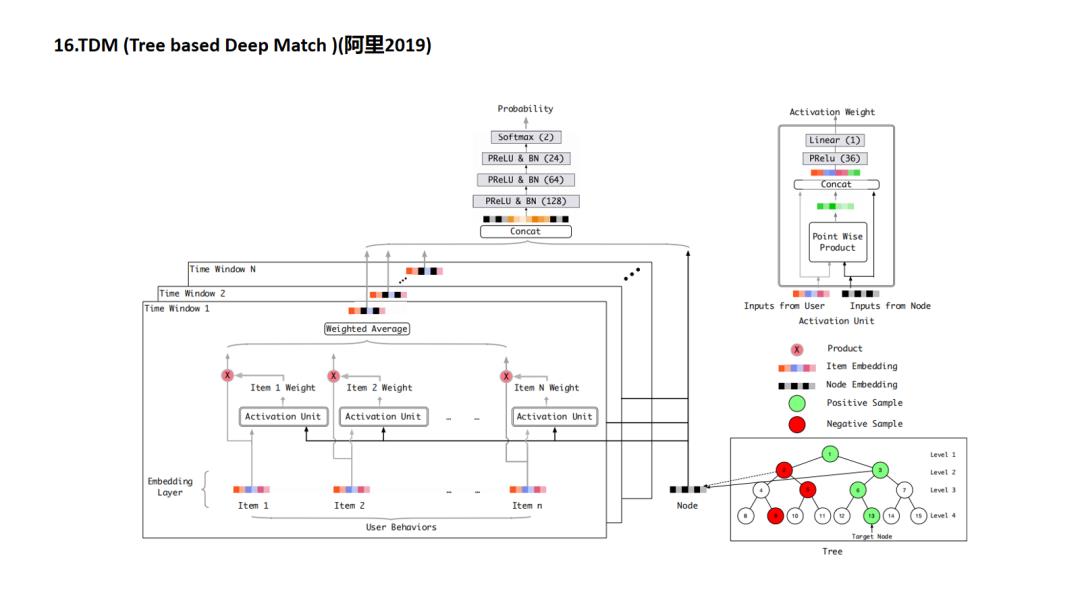

 TDM提出的是对原有向量内积召回的颠覆,耳目一新,但是应用起来会涉及到检索架构的调整,有很大的工程落地成本,这方面的细节笔者尚不清楚,请大家多多指教.
TDM提出的是对原有向量内积召回的颠覆,耳目一新,但是应用起来会涉及到检索架构的调整,有很大的工程落地成本,这方面的细节笔者尚不清楚,请大家多多指教.
结语:
感谢浅梦学长提供这样一个平台可以和大家分享自己的调研, 自己目前还是个行业新兵,希望能和大家多多交流学习,欢迎大家加入浅梦的deepctr和deepmatch社区,一起愉快地学习和玩耍.
推荐阅读
码字很辛苦,有收获的话就请分享、点赞、在看三连吧 以上是关于推荐系统主流召回方法综述的主要内容,如果未能解决你的问题,请参考以下文章