让推荐系统更快——英伟达merlin架构
Posted AI加速
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让推荐系统更快——英伟达merlin架构相关的知识,希望对你有一定的参考价值。
什么是推荐系统?
不论你是网上购物,还是上网观看电影,或者查看新闻,推荐系统一直在帮助人们筛选过滤信息。它依据一定的算法,辨别出你的喜好,然后推荐你所感兴趣的内容。它的商业价值巨大,在一些应用平台甚至占据了30%的营收,因此推荐系统性能改善1%都能带来几十亿美金的收入。
一个推荐系统的基本结构(如下图所示)包括用户数据的收集系统,数据预处理,特征工程,模型建立和训练,推理。
推荐系统是依赖于大量的用户数据的,这些数据被用于训练一个精准的推荐模型。当用户在网络上点击,评论,评价一个物品的时候,这些信息会通过网络被收集到数据中心。这些数据非常巨大,达到TB甚至PT级别。由于数据来源不同,所以格式不够统一,不能够直接用于模型训练,必须进行数据的抽取,转化和加载,即ETL。通过ETL,这些非结构化或者半结构化,不同类型的数据被转化为结构化统一类型数据。
数据抽取针对不同类型的数据使用不同的算法进行收集,比如用户属性数据、物品属性数据一般是存放在关系型数据库中,通过数据快照进行抽取,如果要求较高实时性,可以采用binlog进行数据同步或者消息队列方式来抽取。
数据转换是ETL的核心,其主要是对数据进行清洗,得到格式统一的结构化数据。转换方式多种多样,不同数据有不同处理方式,包括剔除肮脏数据,缺失值填补,数据校验等。
数据加载完成数据到存储终端的输运,存储终端包含了不同类型的数据库,比如关系型数据库,key-value型NoSQL等。
特征工程可以看做一个信息过滤的过程,它从大量数据中寻找规律,提取出有价值的信息。这些信息反映了数据的独特性。通过特征工程可以提取出数据特征,这些特征进而用于模型训练。特征工程包含三个步骤:预处理,特征构建,特征选择。常用的特征预处理方法有:
1) 缺失值处理。我们收集到的数据有很多缺失的,因此可以通过均值,中位数等进行数据插值。
2) 归一化。不同特征之间由于量纲不一样,数值可能相差很大,直接将这些差别极大特征灌入模型,会导致数值小的特征根本不起作用,因此需要对数据进行归一化处理。
3) 非线性变换。为了让模型具备更多非线性能力,可以对数据进行非线性变换,比如对数,高斯,logistic等。
特征构建从数学上看是一个空间映射过程,将原始数据空间映射到新的特征向量空间,使得在新的特征空间中,模型可以更好的学习数据中规律。常用的特征构建手段有很多,针对不同类型数据有不同方法。比如对于离散数据,有one-hot编码,散列编码等。
特征选择是依据一定的度量手段,选择一些合适的特征进行模型训练。特征选择基于方法有方差,皮尔逊相关系数等。
模型训练就是利用梯度下降算法,通过大量数据灌入来优化神经网络中的参数。目前比较流行的模型有DLRM,Wide and Deep,Neural Collaborative Filetering等。
模型训练完成后,就可以将模型用于新的用户数据的预测,推荐用户偏好的项目。这就是模型推理。
推荐系统的设计需要解决如下的挑战:
1 巨量数据:巨量的数据来源于大量的使用用户,以及用户产生的各种各样信息。因此数据预处理和ETL通常比训练模型时间长的多。
2 复杂的预处理过程和特征工程:数据类型多样导致了预处理复杂,大量的数据通过特征工程后生成大量的特征数据,加载这些数据进行模型训练称为输入瓶颈。
3 巨大的查找表:因为数据种类太多了,导致查找表巨大,无法都加载到内存中,因此需要频繁读取磁盘内容,这会造成带宽瓶颈。
4 分布式训练:推荐系统的训练需要同时兼顾模型并行性和数据并行性,因此难度更大。
Merlin架构
英伟达推出的merlin工具是一个基于GPU芯片的,面向推荐系统的端到端解决方案。针对推荐系统中的几大难题,它主要包含三个部分:
1 Merlin ETL: 这部分主要加速数据预处理和特征工程。NVTabular基于RAPIDS cuDF库提供快速高效的数据处理和特征工程方法。它具有更简单易用的接口,ML工程师更容易用它进行特征工程,而不必考虑数据集超过CPU和GPU内存等细节,而只要关心这些数据可以用来做什么。NVTabular能够兼容Pytorch和Tensorflow的数据集类型。能够进行数据shuffle操作。通过官网的数据可以看看它的优势:

2 Merlin training:HugeCTR是一个基于C++的高效推荐系统训练框架。它支持多GPU和多节点训练,同时支持模型并行和数据并行。它涵盖了常用的推荐系统训练模型:DLRM,Wide and Deep,Neural Collaborative Filetering等。HugeCTR和PyTorch以及Tensorflow的不同在于,其专门面向推荐系统,解决了数据加载的瓶颈。这是和tensorflow,pytorch的对比:
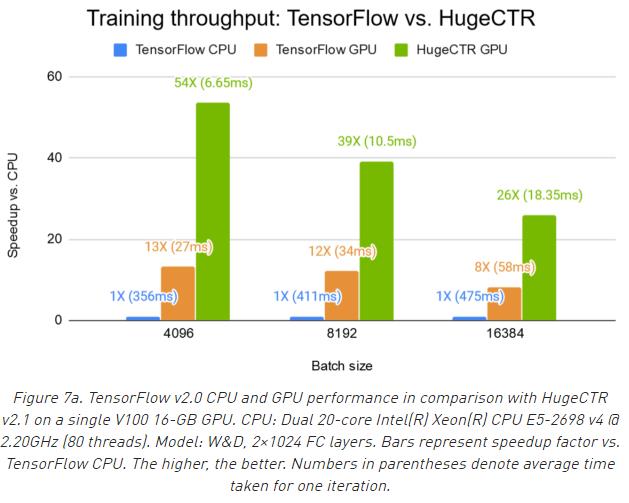
3 Merlin inference:TensorRT是一个用于推理加速的SDK,它能够实现推理模型的优化和自动部署。它可以和常用的训练框架(tensorflow,pytorch等)实现兼容。它的功能主要集中于已经训练好的模型的进一步优化和在GPU上的部署。它可以更好的改善模型在GPU上推理过程的吞吐率,延迟,精度和效率。
TensorRT采用了以下的优化方法:
1) 删除神经网络中输出没有用到的层。
2) 删除无用的op。
3) 卷积层,偏置,ReLU操作的融合。
4) 支持混合精度的量化,比如定点8bit或者16bit。
往期文章
以上是关于让推荐系统更快——英伟达merlin架构的主要内容,如果未能解决你的问题,请参考以下文章