厉害了推荐系统—DSSM模型(上)
Posted 小马学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了厉害了推荐系统—DSSM模型(上)相关的知识,希望对你有一定的参考价值。
厉害了推荐系统
最近晚上睡前只要是打开了头条视频,打底就是一个小时时间,控制也是控制不足自己,已经影响到了我休息时间。自己也是感受到了推荐系统厉害。呵呵这里说的是今日头条结果我放一张抖音,大家都明白一回事。在开始之前我们先说一说降维这件事,其实如果大家想要深入了解降维可以看看流形学方面知识。

降维
在机器学习中也好、在数据挖掘中也好,我们喜欢将事物(文本、图像和音频等信息)抽象为向量。我们用于语言描述世界,传递信息。如何让计算机学会我们语言呢?这是一个看似简单问题,其实做起来很难的事情,我们语言是建立我们人类这个载体,我们见过高山大海、我们经历人间沧桑而机器对于语言的理解缺失了这些,这些除了语言以外却可以赋予语言生命力的东西。感觉这是应该是我们想要搞好自然语言处理的关键,仅是个人一点小见解。有时间我们拿出一系列来说一说一些降维算法。
DSSM 模型简介
DSSM (Deep Structured Semantic Model),有微软研究院提出,利用深度神经网络将文本表示为低维度的向量,应用于文本相似度匹配场景下的一个算法。不仅局限于文本,在其他可以计算相似性计算的场景,例如推荐系统中。
其实我们现在来说一件事就是推荐系统和搜索引擎之间的关系。他们两者之间很相似,都是根据满足用户需求,根据用户喜好给出答案,但又不是完全相同,只不过推荐系统更难,因为推荐系统需要挖掘用户潜在喜好来推荐内容和物品给用户。这是因为搜索引擎和推荐系统的关系之间相似性,所以适用于文本匹配的模型也可以应用到推荐系统中。
DSSM 模型结构
我们还是先看网络结果,网络结果比较简单,是一个由几层全连接组成网络,我们将要搜索文本(Query)和要匹配的文本(Document)的 embedding 输入到网络,网络输出为 128 维的向量,然后通过向量之间计算余弦相似度来计算向量之间距离,可以看作每一个 D 和 Q 之间相似分数,然后在做 softmax ,网络结构如下图
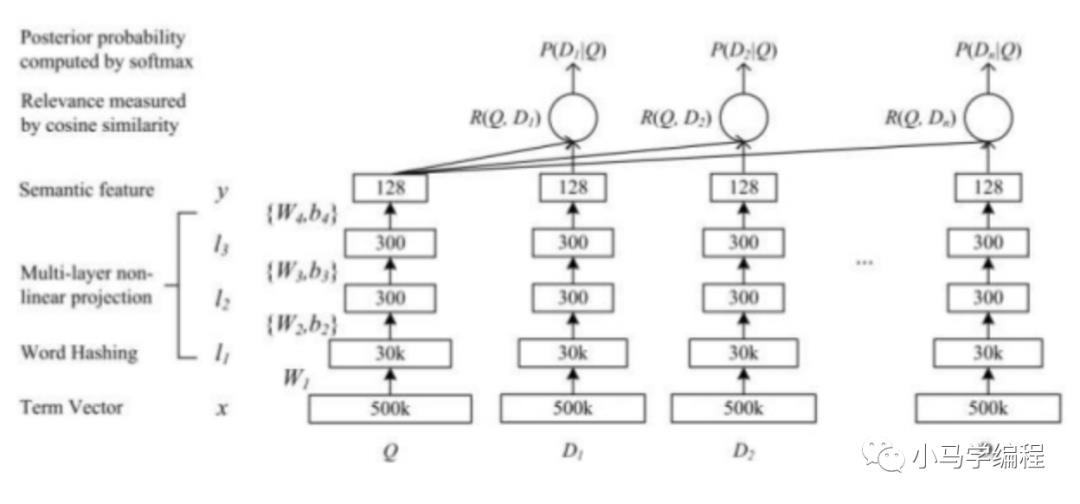
接下来我们结合图,和大家一起看一看网络结构中每一层具体做了那些事。
| 名称 | 说明 |
|---|---|
| Term Vector | 文本的向量 |
| Word Hashing | 文本的 embedding 向量 |
| Multi-layer nonlinear projection | 表示文本的 Embedding 向量 |
| Semantic feature | 文本的 embedding 向量 |
| Relevance measured by consine similarity | 表示计算 Query 与 Document 之间余弦相似度 |
| Posterior probability computed by softmax | 表示通过 softmax 函数把 Query 与正样本 Document 的语义相似性转换为一个后验概率 |
Multi-layer nonlinear projection

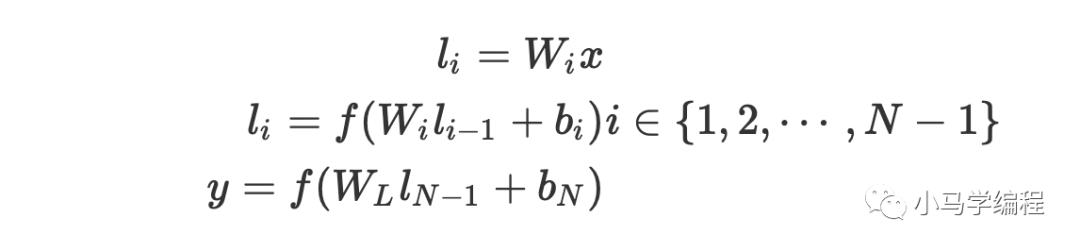
这里的隐藏层用 tanh 作为隐藏层和输出层的激活函数
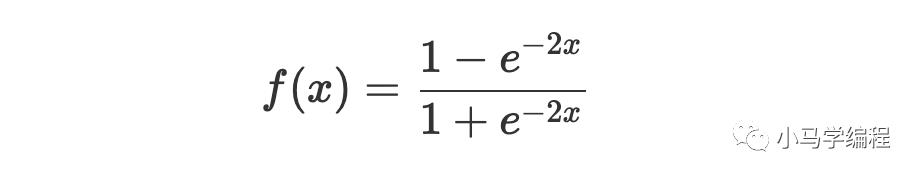
Posterior probability computed by softmax 层

代价函数
这里 Q 表示用户特征,在给定用户特征条件下,匹配到正样本 D 的极大似然,也就是说明在给定 Q 条件出现正样本 D 概率分布参数是什么样的,因为我们要求损失,所以前面加一个负号,最大值的问题转化为最小值的问题。
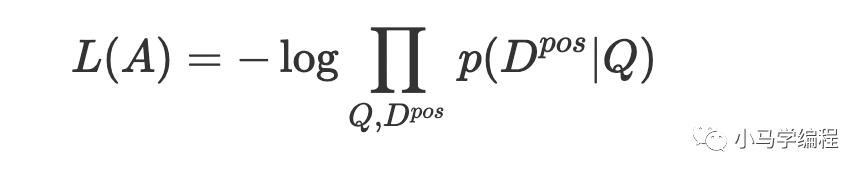
DSSM 模型在推荐系统
之前在协同过滤多少给大家介绍一些基于内容、用户或模型的协同过滤算法,在推荐中我们主要通过用户和物品之间关系,也是相似性来进行推荐,用户到物品可以看作一条路径,可以是用户到用户再到物品的路径,也可以是物品到物品再到用户路径,这有很多种玩法。

输入 Qury 例如是一个用户特征,然后我们将推荐给用户一系列物品,假设是一系列房源,然后用户点击的房源就是有可能用户想要看的,其实这个也不一定是用户真正意图。那么用户点击就是正样本,反之其他的就是样本。

DSSM 模型在推荐召回环节的结果
DSSM 模型的特点是由 Query 和 Document 两个相对独立子网络构成,在推荐系统召回环节,这两个子网分别为用户端(User)和物品短(Item)。这样做好处是利于产品化,可以分别对用户和物品端向量做单独的获取和存储。
X 表示用户特征,Y 表示物品的特征
经过神经网络分别得到各自 128 维的 Embedding 向量
计算 sim(u(X),v(Y)) 的余弦相似度
候选集合召回
当模型训练完成,物品的 Embedding 是可以保存成词表,线上应用的时候只要需要查找对应的 Embedding 即可。因此线上只需要计算一侧的 Embedding 这样节省了计算资源。
好了今天就说到这里,随后给大家代码实现,最近在研究预测和推荐,感觉这两领域还是传统机器学习和统计模型的领域,深度学习在逐渐接入。
以上是关于厉害了推荐系统—DSSM模型(上)的主要内容,如果未能解决你的问题,请参考以下文章