数果智能助力企业快速构建精细化个性推荐系统,打造企业运营增长引擎
Posted 数果智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数果智能助力企业快速构建精细化个性推荐系统,打造企业运营增长引擎相关的知识,希望对你有一定的参考价值。
在移动互联网的下半场,随着数据量和流量的爆发式增长,用户想从大量的信息中找到自己感兴趣的、适合自己的信息会变得非常困难,而企业作为信息提供方,需要提供大量的信息才能获得少量收益,这样提供信息花费的成本与取得的回报根本不成比例。在当下复杂的运营场景下,如何精细、准确、高效、智能地将“人”、“货”、“场”三个核心元素联系起来,已成为各企业越来越关注的问题。
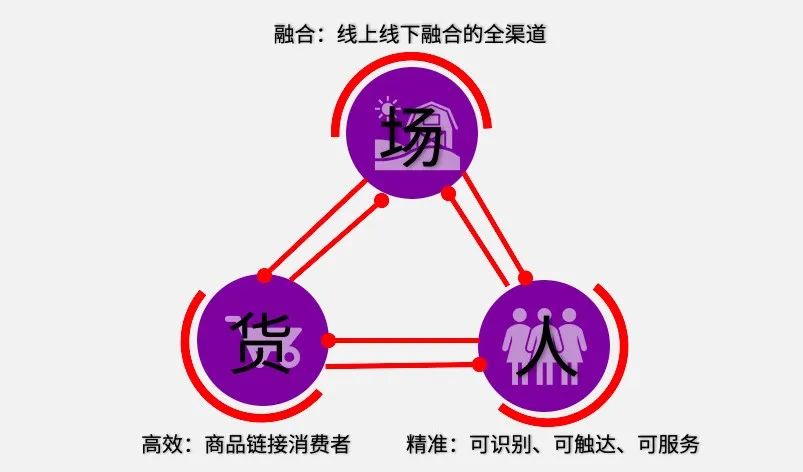
推荐系统作为一种信息过滤技术,通过从用户行为中挖掘用户兴趣偏好,为用户提供个性化的信息,减少用户的找寻时间,降低用户的决策成本,让用户更加被动地消费信息。推荐系统可以向用户推荐“量身定做”的内容,因而能极大的提高互联网上相关信息的利用率。
Y企业是一家集开发、设计、运营、销售于一体,通过网络展开主动式服务营销的综合型女性B2B2C电子商务公司,业务范围涵括护肤、彩妆、营养美容食品、私人定制服装、跨境电商等领域。Y企业拥有自研的小程序商城,线上线下累计客户一亿多,现有商城用户数三百多万,日活十万级。Y企业已经基于数果用户画像系统对一亿多的累计用户进行了360度的画像标记,分别从客户属性、消费情况、消费偏好、皮肤问题、用户价值等二十多个大类对用户进行了贴标,标签维度353个。
基于千人千面个性化的推荐系统是各个业务场景必不可少的一环,因此Y企业希望基于现有的海量数据,结合算法,分析计算用户的行为偏好,从而发掘或预测出用户的个人需求,给予用户相关推荐。
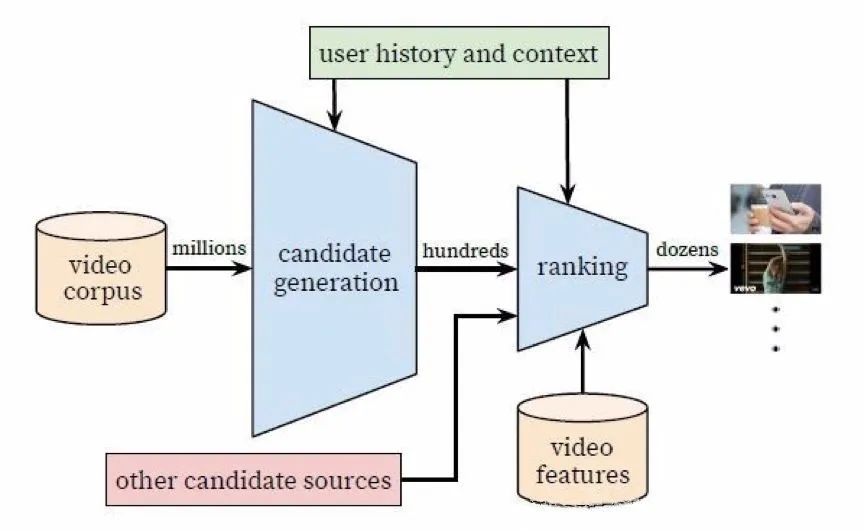
由于平台中的 Item 总数量是非常庞大的,而且数量日益增长,数据量会越来越多。若直接在所有数据中计算推荐 confidence(置信度),计算量会非常庞大,而且效率极低。因此,推荐系统会分为Matching(召回)和 Ranking(排序)两部分。其中,Matching(召回)部分是为了快速地从所有 item 中挑选最符合的数百个 candidates ,而 Ranking(排序)部分使用更准确的算法,计算每个 item 的推荐置信度,并对结果进行排序,返回 topN 结果。
目前业界内普遍认同的是,基于用户行为序列的深度学习模型在相关性检索和召回性能上都有很好的表现,相比传统的召回方法有很大的提升。因此,数果科技的推荐系统也选择了目前流行的深度学习模型,我们选择了 Youtube 视频推荐算法作为主要算法思想,并且在该算法的基础上进行了修改,使推荐算法更符合客户的业务需求。
我们在 Youtube 视频推荐算法上进行了适当的调整与修改,加入了点积相关性模块(dot-product coefficient)和多任务对抗学习模块(GRL)。
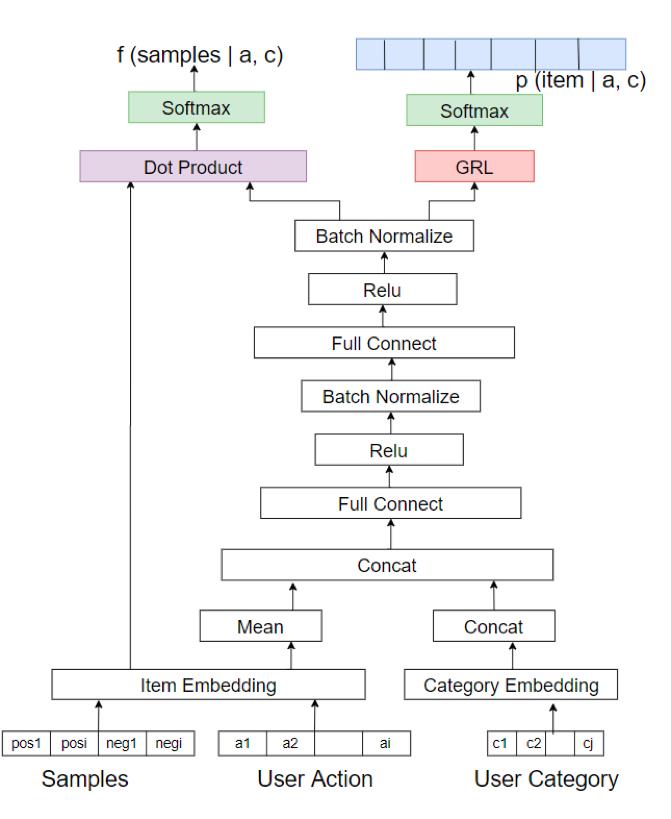
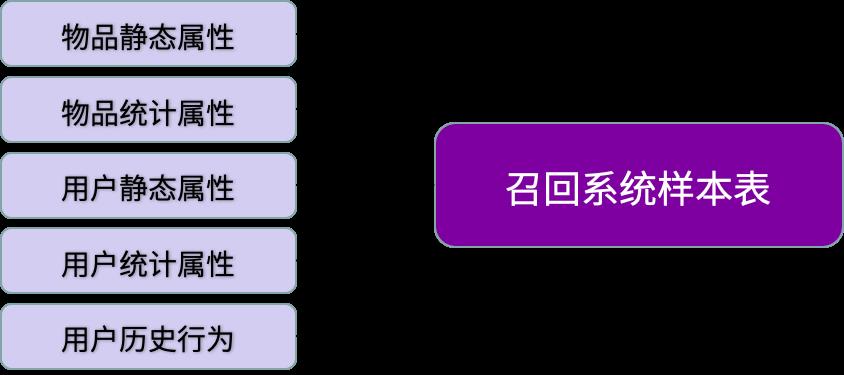
在模型训练过程中使用了用户信息和物品信息,其中用户信息包括静态属性、统计属性、用户交易记录、用户行为记录等,物品信息包括静态属性和统计属性等。这些数据分别来自于商城行为、订单数据、会员数据、商品数据、积分数据、直播带货数据等。
在权重方面,购买行为的权重要比浏览行为高。不同用户的历史行为序列长度是不一样的,但是模型需要定长的输入。这个长度的选择一般是根据用户行为序列分布决定,比如说中位数,或者平均数,具体选择根据数据实际情况。
为了让数据接口更加简洁,一般会把这些特征都转换成类别特征,对于像年龄这种连续特征,做标准化的实际效果并没有做离散化好,因为年龄分层更加符合用户的消费能力和对产品的倾向,不同年龄的人对化妆品保养品衣服等需求肯定是会有差别的,所以根据业务经验去对年龄分层,效果要比简单的标准化好。
在不影响效果的前提下,简化了模型输入,模型的输入全部是类别型的特征。在训练数据的处理上,时间窗口选择采用60天数据训练,T+15 评测。也就是说随机选取连续60天的数据作为输入X,未来15天数据为label数据,采样半年的数据作为训练集。
效果验证使用精确率、召回率和F1分数作为验证指标。由于推荐系统处于 Matching (召回)阶段,希望能把所有相关的物品都召回,召回率的重要程度远比精确率要高,因此将F1分数标准修改为F_β分数,并且设置β=3 。
同时对于精确率的计算,应该作出相应的修改,TopN指标中的 N 值应该修改为真实 Label 的数量,而不是固定的数值(300,500等)。
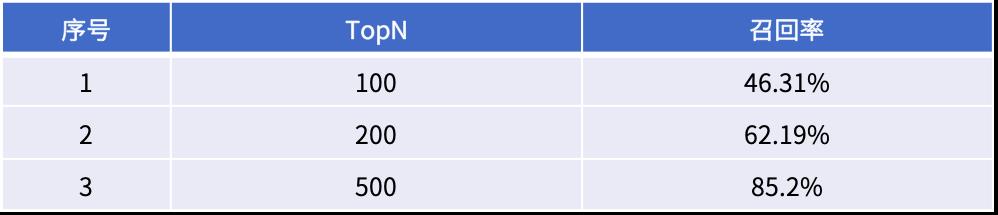
除了计算离线数据的准确率和召回率外,在实际的抽样返回推荐列表的验证中,我们对比了推荐结果的 item 和用户历史行为中的 item,能够很明显的看出有相当大的关联,从用户体验的角度来看效果非常明显。
总结
对于推荐系统的构建,数据处理占大部分时间,包括:数据清洗、缺失值填充、异常数据剔除等等。有较多细节的决策需要通过实验来快速地验证想法,比如年龄的离散化,实际上需要根据用户人群的年龄分布调整划分界限。行为序列的长度,窗口时间等,则需要经过效果验证来得到更加适合的数值。对于缺失值的处理,无论是在用户属性,上下文属性或者历史行为,其实都会涉及到,对于用户属性和上下文属性会使用标记填充。
同样对于模型的超参来说,仅仅参照理论分析是没有意义的,这样只能是纸上谈兵,更多的是需要结合实际数据,效果验证去做调优,经过多次调优得到更好的效果。
往期精彩
以上是关于数果智能助力企业快速构建精细化个性推荐系统,打造企业运营增长引擎的主要内容,如果未能解决你的问题,请参考以下文章