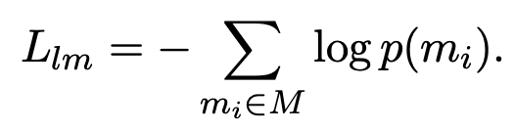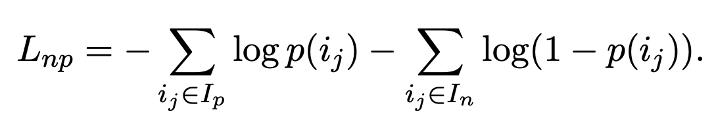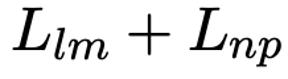供稿 | eBay Search & Ads Team
作者 | 傅余洋子 & 王添
推荐系统是电子商务平台的重要组成部分。然而许多传统的推荐系统存在冷启动、内容单一等缺陷。针对这类问题,eBay的研究员以BERT模型为基础,结合用户历史行为数据,提出了一种基于项目的协同过滤算法。该模型在大规模真实数据集上取得了显著效果,提供了冷启动场景推荐的解决方案。相关论文已被ACL2020的ECNLP Workshop收录。
作为电商网站的核心组成之一,传统的推荐系统算法分为两大类:
协同过滤推荐算法和基于内容的推荐算法。然而这两类算法在真实数据集上都存在一些局限性。
传统的协同过滤算法:
基于用户的协同过滤算法
[1]会根据种子用户评论过的项目来发现相似用户,然后选出这些相似用户给出较高评分的项目推荐给种子用户;
基于项目的协同过滤算法
[2]会以种子项目为基础,挑选那些有着相似用户评分的项目。
然而,在eBay这类活跃度较高的电商网站上,项目和用户每时每刻都在更新,传统的协同过滤算法会面临数据稀疏性的问题,难以在冷启动场景给出优质的推荐内容。
基于内容的推荐算法:
这类算法致力于计算种子项目与候选项目在内容方面的相似度(包括点击、评分、语义等),然后挑选出最相似的项目进行推荐。尽管这类算法避免了数据稀疏度的影响,但其对内容的依赖决定了它们难以提供新颖的推荐,不利于挖掘用户的潜在兴趣
[3]。
近年来,随着神经网络模型的崛起,推荐系统也开始在深度学习领域进行尝试。本研究以BERT模型为基础,结合用户历史行为数据,将Masked Language Model和Next Sentence Prediction这两个BERT模型的训练任务从自然语言领域迁移到电商领域,提出了一种新的基于项目的协同过滤算法。
本研究的优势在于:
(1)不同于以往用项目 ID来聚合历史信息的方式,我们以项目标题为输入内容,使得相似的项目获得相似的编码,有效解决传统推荐算法中的冷启动问题。
(2)以用户历史行为数据来训练模型,相较于挖掘项目相似度,本研究能更好地发掘用户的潜在兴趣。
在大规模真实数据集上的实验表明,本研究能显著解决冷启动、内容单一等问题,获得高质量的推荐内容。
如上所述,对于一个动态的电子商务平台,商品无时无刻不在更新,这导致用户-项目的交互矩阵极为稀疏。这一特性给传统的推荐系统带来了两点挑战:(1)长尾推荐,即那些非热门的项目难以有机会被推荐;(2)模型需要不断地重新训练和部署,以适应新上架的项目。
为了解决这些问题,我们选择使用标题的tokens来表示每个项目,而不是采用唯一的ID来表示,并将这些tokens进一步映射到连续的向量表示空间中。由此,两个具有相同标题的项目将被视为同一个项目,它们的用户行为数据可以被汇总共享。对于冷启动的项目,模型可以利用标题来发现与之前观察到的项目的相似性,从而发掘相关的推荐。
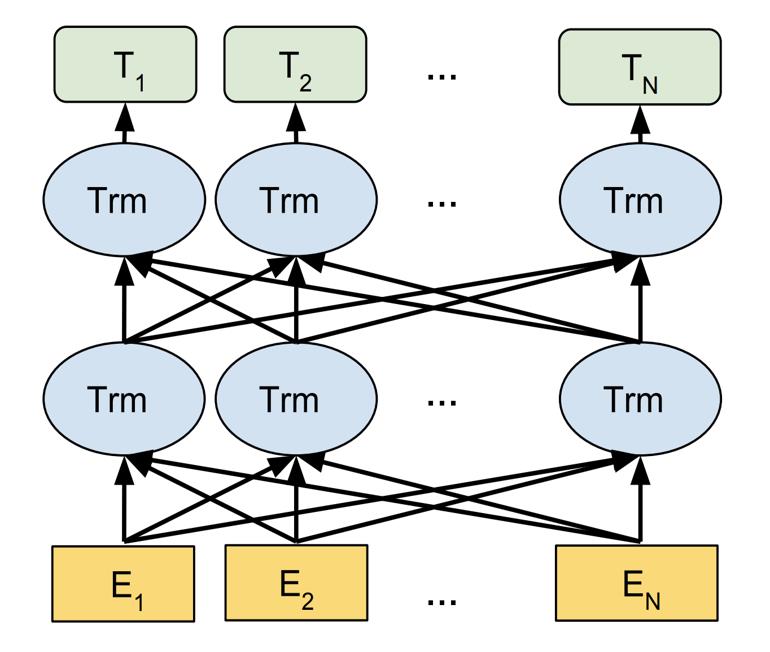
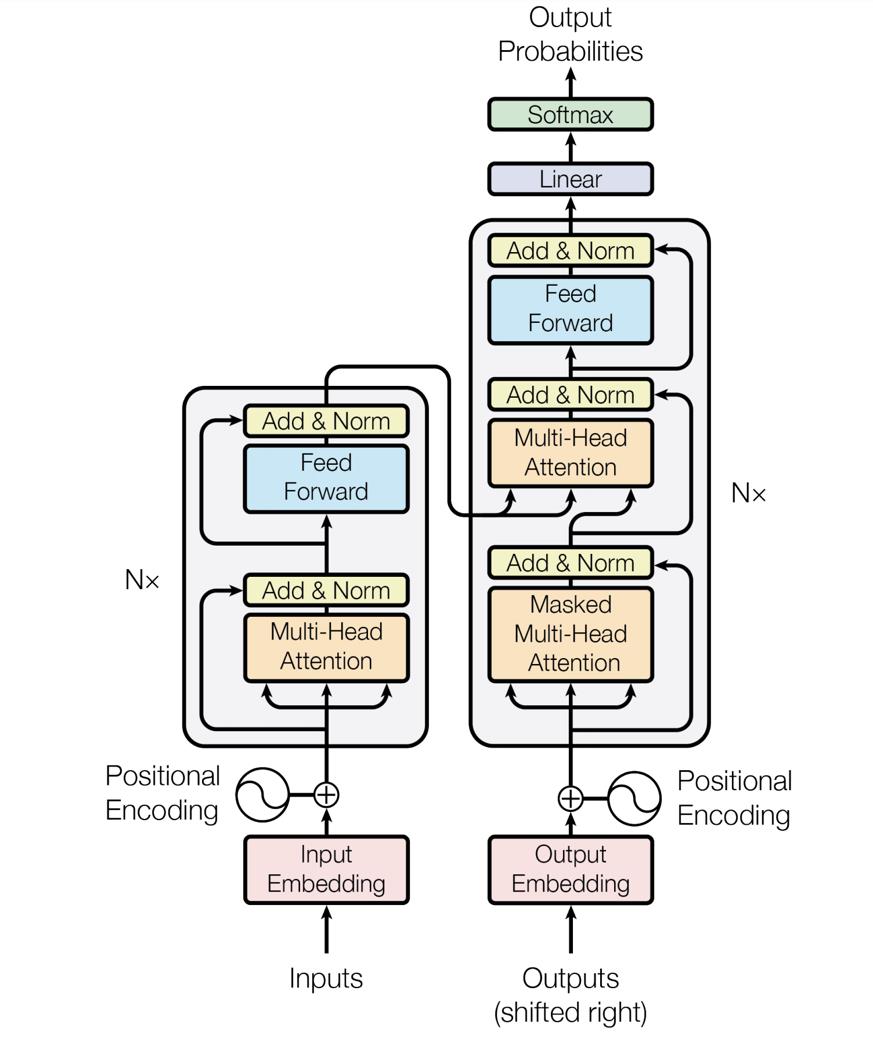
本文提出基于项目的协同过滤算法,其目标是对两个项目之间的相关性进行评分,对于任一种子项目,将得分最高的若干项目作为推荐结果。我们以BERT模型[4]为基础,实现了这一算法。不同于传统的RNN / CNN结构,BERT模型是以transformer encoder为结构的语言模型,采用注意力机制来计算输入和输出之间的关系。BERT和transformer的结构如图1所示[4][5]。
BERT模型的训练可分为两部分:Masked Language Model和Next Sentence Prediction。在本算法中,我们将这些任务迁移到电商推荐任务上:Masked Language Model on Item Titles和Next Purchase Prediction。
图1: BERT & Transformer 结构
Masked Language Model on Item Titles:电商平台上项目标题的tokens分布,与BERT模型预训练所用的自然语言语料中的tokens分布有着很大的不同,为了模型能够更好地理解电商推荐环境中的语义信息,我们将这一任务作为目标之一对模型进行再训练。在训练过程中,我们遵循Devlin等人的方案[4],对项目标题中随机15%的tokens做MASK处理,则该部分的损失函数为:
Next Purchase Prediction:在BERT模型中,Next Sentence Prediction用来预测一个句子A是否是另一个句子B的后一句。我们将其转换为推荐问题:给定一个种子项目A,预测另一个项目 B是否是用户要点击购买的下一个项目。以项目A的标题替换原模型中的句子A,以项目B的标题替换原模型中的句子B,将标题拼接起来作为模型的输入。我们从用户的历史行为数据中收集模型的训练数据,对于种子项目,以同一个用户会话中被购买的项目为正例,并从inventory中随机抽取负例。由此,给定正例集合和负例集合,该部分的损失函数为:
为了验证这一算法在电商推荐系统中的表现,我们收集了eBay的真实数据进行实验。共收集了大约8,000,000对项目作为训练集,其中约33%为正例(用户在同一会话中购买的项目)。可以看到,项目-项目的交互矩阵非常稀疏,传统的推荐算法难以取得好的效果。我们以同样的方法收集了大约250,000对项目作为验证集,用于防止模型过拟合。
对于测试集,则采用了基于冷启动数据的采样方案,以验证我们的算法在这类传统协同过滤算法无法处理的情景中的表现。共收集了10,000对正例,每一对中的种子项目未在训练集中出现过。针对每一对正例,我们随机采样999个项目作为负例。由此,每个种子项目会有1000个候选项目。在测试时,对这1000个候选项目进行排序,并计算Precision@K、Recall@K、NDCG@K等指标,据此对算法进行比较。
为了进行比较,我们需要构建一个baseline算法。由于测试集中的种子项目都是全新的项目,在训练集中均未观察到,没有历史数据,所以无法应用传统的协同过滤算法。我们构建了一个双向LSTM模型作为baseline,该模型的输入同样为两个项目标题的拼接,损失函数与我们算法中Next Purchase Prediction部分的损失函数一致。
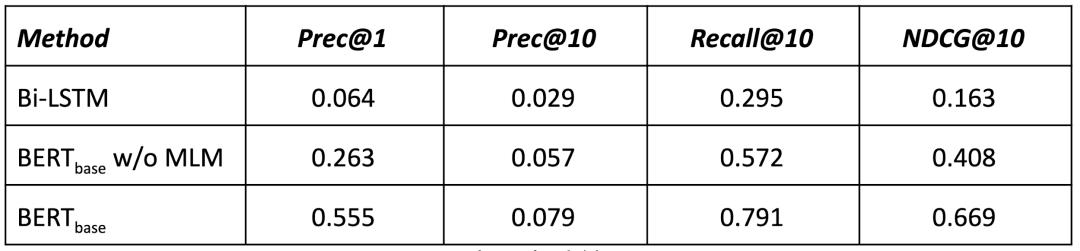
实验结果如表1所示。可以观察到,我们提出的算法大大优于baseline算法。当只针对Next Purchase Prediction这一任务对BERT模型进行再训练时,Precision@1、Precision@10、Recall@10、NDCG@10分别高出baseline算法310.9%、96.6%、93.9%和150.3%。当同时加入Masked Language Model on Item Titles这一任务时,各项指标进一步提高了111.0%、38.6%、38.3%和64.0%。由此可以看出,我们提出的以BERT模型为基础的基于项目的协同过滤算法具有明显的优越性。
为了直观地检查算法给出的推荐结果的质量,我们在表2中给出了一个例子。种子项目为蜘蛛侠主题的T恤,推荐的商品为T恤、配套服饰、餐具装饰等,且均为漫威主题。从这个例子可以看到,该算法可以自动地发掘推荐商品的选择标准而无需人工指定,并且可以在专注特定类别与挖掘广泛兴趣之间找到平衡点。
我们以BERT模型为基础,结合用户历史行为数据,提出了一种基于项目的协同过滤推荐算法。以标题的tokens的向量表征取代唯一ID来表示项目,能将相似项目的信息汇聚在一起,解决了传统协同过滤推荐算法中的长尾推荐、冷启动等问题。通过在大规模真实数据上进行实验,证明了该算法在理解项目语义信息和学习大量项目之间的关系方面具有显著优势。
[1] J Ben Schafer, Dan Frankowski, Jon Herlocker, and Shilad Sen. 2007. Collaborative filtering recommender systems. In The adaptive web, pages 291–324. Springer.
[2] Greg Linden, Brent Smith, and Jeremy York. 2003. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet computing, (1):76–80.
[3] P Castells, S Vargas, and J Wang. 2011. Novelty and diversity metrics for recommender systems: choice, discovery and relevance. In International Workshop on Diversity in Document Retrieval (DDR 2011) at the 33rd European Conference on Information Retrieval (ECIR 2011).
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[5] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).