推荐系统 | 基于联合学习的会话推荐
Posted MINS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统 | 基于联合学习的会话推荐相关的知识,希望对你有一定的参考价值。
论文题目:Learning sequential and general interests via a joint neural model for session-based recommendation
发表期刊:Neurocomputing (Elsevier), vol.415, pp.165-173, November 2020
DOI:10.1016/j.neucom.2020.07.039
1. 背景
在这个信息爆炸的时代,我们每天被大量的信息包裹着,但如何从缤纷错杂的信息中真正捕获自己的关注点,这已经成为目前大部分用户所面临的问题,因此,推荐系统(Recommendation System)因运而生,通过分析用户的属性、历史数据、物品属性等信息,为用户寻找到自己的兴趣点,具有较大的商业价值。而会话推荐系统(Session-based Recommendation System, SBRS)作为近年来新兴的推荐系统之一,其任务是通过分析匿名用户在一小段时间内的浏览进程,为其推荐下一个浏览对象。下图是一个基于会话推荐系统的例子:
图1 基于会话推荐示意图
从上图直观理解后,我们可以看出,在SBRS中,能够使用的信息仅仅只有用户的历史行为,而相比于个性化推荐系统中的用户属性、物品属性等信息是未知的,因此,这也是匿名SBRS所面临的一个较大挑战。本文介绍的这篇论文正是针对这个问题,提出从当前用户的序列兴趣和常规兴趣两个角度进行挖掘,来预测与用户发生下一次交互的物品。
2. 论文概要
论文提出了一种联合学习神经网络模型(SGINM),同时提取当前会话中用户的序列兴趣与常规兴趣,既考虑用户随时间转移的兴趣变化,又通过提取常规兴趣缓解序列特征带来的物品之间过于强烈的顺序关系。具体而言,我们首先将用户历史行为中交互过的物品按照交互时间进行排序后,得到一个当前会话的物品序列,然后采用带注意力机制的递归神经网络(RNNs with Attention Mechanism)提取当前会话中用户的序列兴趣特征。另一方面,我们采用平均池化层结合深度残差网络来提取当前会话中用户的深度常规兴趣特征,因为平均池化层会将所有物品一视同仁,因此其会缓解序列特征中过于强化的物品序列信息。两部分的模型示意图如下所示:
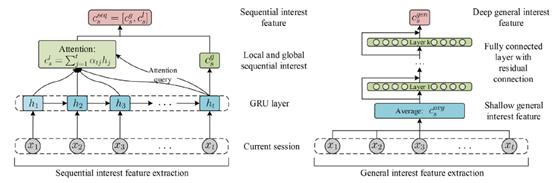
图2 模型序列兴趣和常规兴趣提取模块
整个模型都是端到端训练,实验结果显示,SGINM在两个数据集Yoochoose(Recsys Challenge 2015)和Diginetica(CIKM Cup 2016)上,都超过了当前state-of-the-art的方法。
3. 相关工作
基于会话的推荐系统SBRS已经成为推荐系统中的一个重要任务之一[1]。早期的做法大多都是简单的基于物品热度,或者通过马尔科夫链模型捕捉物品之间的潜在关系[2, 3, 4],基于物品热度的方法由于规则较为简单,推荐效果往往不尽如人意。而基于马尔科夫链的方法,受到马尔科夫模型中强烈的独立性限制。近年来,神经网络的崛起,神经网络特征的表征能力相比于传统方法提取到的特征往往要更加强大,针对序列问题,[5]采用递归神经网络GRU来提取每个会话序列的特征。[6]采用GRU结合注意力机制来表征会话序列。[7]采用注意力网络结合最后一个物品的特征来共同表征。[8]采用一个较新的神经网络技术,图神经网络(Graph Neural Network, GNN)来提取物品的特征,再采用注意力网络下一个物品的预测。
4. 算法详解
论文提出的神经网络模型是一种Encoder-Decoder结构,其结构概括如下图所示:
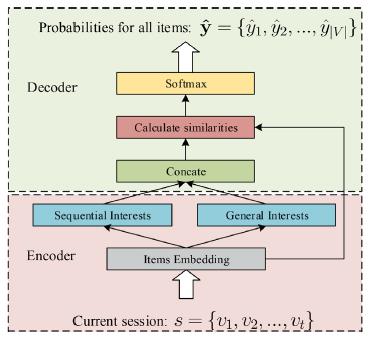
图3 SGINM模型图
如上图所示,SGINM模型主要包括3个部分:(1)序列兴趣提取;(2)普遍兴趣提取;(3)偏好概率分布计算,即解码预测下一次物品。SBRS问题可以数学定义为:设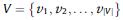 表示所有会话中出现过的物品集合,
表示所有会话中出现过的物品集合,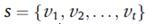 表示一个会话s,其中的物品按照时间先后顺序排列,SBRS的目标是预测下一次交互物品,即
表示一个会话s,其中的物品按照时间先后顺序排列,SBRS的目标是预测下一次交互物品,即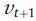 。
。
让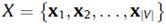 表示所有物品对应的嵌入向量(Embedding Vector),以会话s为例,我们将其映射到嵌入向量空间为
表示所有物品对应的嵌入向量(Embedding Vector),以会话s为例,我们将其映射到嵌入向量空间为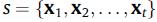 ,我们的模型SGINM输出为当前用户针对所有物品的偏好概率分布
,我们的模型SGINM输出为当前用户针对所有物品的偏好概率分布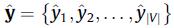 ,其中得分最高的Top-K个物品即被选择为推荐物品。
,其中得分最高的Top-K个物品即被选择为推荐物品。
4.1 序列兴趣提取
如图2所示,当前会话中用户的序列兴趣提取采用的是GRU结合注意力机制,首先采用GRU提取每个时刻的前缀子序列特征:
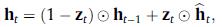
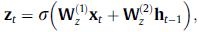
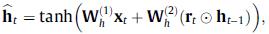
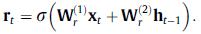
其中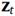 和
和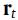 分别是更新门(Update gate)和重置门(Reset gate),
分别是更新门(Update gate)和重置门(Reset gate),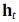 是得到的t时刻的隐藏特征。
是得到的t时刻的隐藏特征。
经过GRU提取特征后,我们将会话s编码为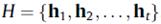 ,我们将最后时刻的特征作为序列的全局表示(GlobalRepresentation),记为
,我们将最后时刻的特征作为序列的全局表示(GlobalRepresentation),记为
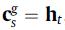
然后采用作为后续注意力网络的索引(Attention query),计算一个序列的局部表示(Local Representation),如下:
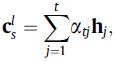
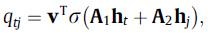
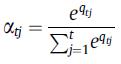
最终当前会话中的用户的序列兴趣被表征为:
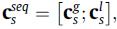
4.2 常规兴趣提取
如图2所示,会话中提取当前用户的常规兴趣首先采用一个评价池化层提取浅层常规兴趣特征:
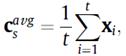
再通过带残差连接的全连接网络提取到深层常规兴趣特征,并且残差连接可以让其中依旧包括一些浅层特征的成分,每一层网络计算如下:
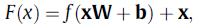
这里采用两层网络:
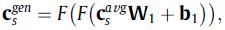
4.3 偏好概率分布预测(输出模块)
分别提取了当前会话的序列兴趣和常规兴趣表示后,我们将其拼接得到最终的会话特征表示:
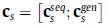
然后通过內积相似度和Softmax函数计算得到针对所有物品的概率偏好分布:
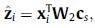
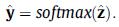
整个SGINM模型采用端到端学习,采用交叉熵作为损失函数进行训练:
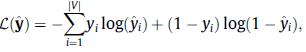
5. 实验分析
5.1 数据集
Yoochoose:Yoochoose数据集包括欧洲电商6个月的点击数据。我们使用最后一天的作为测试集,其余的作为训练集,常见的是构建Yoochoose 1/4和Yoochoose 1/64数据集。
Diginetica:Diginetica数据集包括用户名匿名的交易数据,我们使用最后一周的作为测试集,剩余的作为训练集。
以上两个数据集具体如下表所示:
表1 数据统计信息

5.2 评价指标
这里采用P@K和MRR@K作为评价指标。
5.3 对比算法
第一类是传统方法:包括基于热度推荐的,基于马尔科夫模型的,以及基于矩阵分解的;第二类是深度学习方法:GRU4Rec[5]、NARM[6]、STAMP[7]、SR-GNN[8]
5.4 对比实验结果
我们模型SGINM与对比算法的实验结果对比如下表所示:
表2 实验结果对比
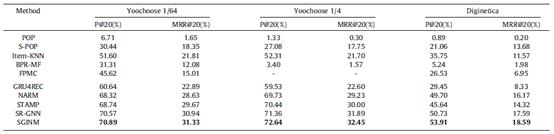
由上表可以看出,我们的SGINM在所有数据集上都取得了最好的实验结果,我们认为这是因为我们较为全面的考虑了每条会话的序列兴趣特征和普遍兴趣特征,它们能够互相弥补彼此的缺点,以取得更好的效果。
我们还进行了序列长度的分析实验,以5作为阈值将序列分为长序列和短序列,下表是不同模型在长/短序列上的实验结果对比:
表3 长/短序列实验结果对比

虽然SGINM不是所有情况都是最优的,但是至少都是第二优的,并且我们也可以清楚的看出,所有模型在短序列上的效果都要好于长序列,这也揭示了现有的模型在序列较长后,提取特征的表征能力还有所欠缺。
除此之外,我们还将训练数据不断减少,以此来测试模型的鲁棒性和稳定性,我们将训练数据集依次减半后,数据集如下表所示:
表4 训练数据集减少
在以上数据集上依次进行实验,对比实验结果如下图所示:
虽然所有模型的性能指标都在下降,但是我们可以看到,SGINM的曲线几乎都在其他几个对比模型的上方,这也反映了SGINM在受到训练数据集减少时,能够更加稳定一些,受到的影响稍小。
6. 结论
在这篇论文中,我们针对基于会话推荐问题,提出一个同时提取会话的序列兴趣和常规兴趣的联合学习模型SGINM,在SGINM中,序列兴趣和常规兴趣能够互相补足,来增强最后特征的表征能力。实验结果也显示,SGINM取得了更佳的性能指标,这也与我们的分析是相符的。
主要参考文献
[1] S. Wang, L. Cao, Y. Wang, A survey onsession-based recommender systems, arXiv preprint arXiv:1902.04864 (2019).
[2] S. Rendle, C. Freudenthaler, L.Schmidt-Thieme, Factorizing personalized markov chains for next-basketrecommendation, in, in: Proceedings of the 19th international conference onWorld wide web, WWW ’10, ACM, 2010, pp. 811–820
[3] A. Zimdars, D.M. Chickering, C. Meek,Using temporal data for making recommendations, in: Proceedings of theSeventeenth conference on Uncertainty in artificial intelligence, UAI’01,Morgan Kaufmann Publishers Inc., 2001, pp. 580–588.
[4] G. Shani, D. Heckerman, R.I. Brafman,An mdp-based recommender system, J. Mach. Learn. Res. 6 (Sep) (2005) 1265–1295.
[5] B. Hidasi, A. Karatzoglou, L.Baltrunas, D. Tikk, Session-based recommendations with recurrent neuralnetworks, in: Proceedings of the 4th International Conference on LearningRepresentations, ICLR ’16, 2016.
[6] J. Li, P. Ren, Z. Chen, Z. Ren, T.Lian, J. Ma, Neural attentive session-based recommendation, in: Proceedings ofthe 2017 ACM on Conference on Information and Knowledge Management, CIKM ’17,ACM, 2017, pp. 1419–1428.
[7] Q. Liu, Y. Zeng, R. Mokhosi, H. Zhang,Stamp: Short-term attention/memory priority model for session-basedrecommendation, in: Proceedings of the 24th ACM SIGKDD InternationalConference on Knowledge Discovery & Data Mining, KDD ’18, ACM, New York,NY, USA, 2018, pp. 1831–1839. doi:10.1145/3219819.3219950.
[8] S. Wu, Y. Tang, Y. Zhu, L. Wang, X.Xie, T. Tan, Session-based recommendation with graph neural networks, in:Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33 of AAAI’19, 2019, pp. 346–353.
以上是关于推荐系统 | 基于联合学习的会话推荐的主要内容,如果未能解决你的问题,请参考以下文章