专栏1-推荐系统基于物品的协同过滤算法
Posted MomodelAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了专栏1-推荐系统基于物品的协同过滤算法相关的知识,希望对你有一定的参考价值。
基于物品的协同过滤算法给用户推荐那些和他们之前喜欢过物品相似的物品,比如用户购买过篮球那系统很有可能对其推荐球衣。
基于物品的协同过滤算法主要分为两步:
1.计算物品之间的相似度
2.根据物品的相似度和用户的历史行为给用户生成推荐列表
比如我们可以定义物品的相似度:
其中,分母是喜欢物品i的用户数,分子是同时喜欢物品i和物品j的用户数。
当然,如果物品j非常热门,那么Wij就接近于1,即任何物品都和热门的物品有很高的相似度,所以我们可以使用下面的公式
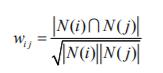
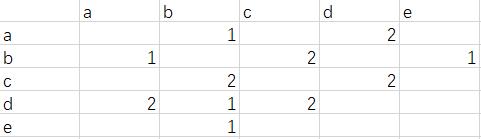
在设计算法的时候首先建立用户-物品字典,然后对于每个用户,将其物品列表中的物品在共现矩阵对应位置加1。
举一个简单的例子,
用户1:a,b,d
用户2:b,c,e
用户3:c,d
用户4:b,c,d
用户5:a,d
那么共线矩阵为
则ItemCF计算用户u对物品j的兴趣为:
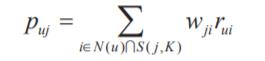
其中N(u)是用户喜欢的物品集合,S(j,k)是和物品j最相似的K个物品的集合,wji是物品j和i的相似度,rui是用户u对物品i的兴趣。
以下为具体代码,这里用movie-lens的数据集,链接如下
https://grouplens.org/datasets/movielens/ 中的ml-latest-small.zip
# coding = utf-8
# 基于项目的协同过滤推荐算法实现
import random
import math
from operator import itemgetter
class ItemBasedCF():
def __init__(self):
# 找到相似的20部电影,为目标用户推荐10部电影
self.n_sim_movie = 20
self.n_rec_movie = 10
# 将数据集划分为训练集和测试集
self.trainSet = {}
self.testSet = {}
# 用户相似度矩阵
self.movie_sim_matrix = {}
self.movie_popular = {}
self.movie_count = 0
# 读文件得到“用户-电影”数据
def get_dataset(self, filename, pivot=0.75):
trainSet_len = 0
testSet_len = 0
for line in self.load_file(filename):
user, movie, rating, timestamp = line.split(',')
if(random.random() << span=""> pivot):
self.trainSet.setdefault(user, {})
self.trainSet[user][movie] = rating
trainSet_len += 1
else:
self.testSet.setdefault(user, {})
self.testSet[user][movie] = rating
testSet_len += 1
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('\r\n')
# 计算电影之间的相似度
def calc_movie_sim(self):
for user, movies in self.trainSet.items():
for movie in movies:
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1
self.movie_count = len(self.movie_popular)
for user, movies in self.trainSet.items():
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
self.movie_sim_matrix.setdefault(m1, {})
self.movie_sim_matrix[m1].setdefault(m2, 0)
self.movie_sim_matrix[m1][m2] += 1
# 计算电影之间的相似性
print("Calculating movie similarity matrix ...")
for m1, related_movies in self.movie_sim_matrix.items():
for m2, count in related_movies.items():
# 注意0向量的处理,即某电影的用户数为0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
# 针对目标用户U,找到K部相似的电影,并推荐其N部电影
def recommend(self, user):
K = self.n_sim_movie
N = self.n_rec_movie
rank = {}
watched_movies = self.trainSet[user]
for movie, rating in watched_movies.items():
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
rank[related_movie] += w * float(rating)
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
N = self.n_rec_movie
hit = 0
rec_count = 0
test_count = 0
all_rec_movies = set()
for i, user in enumerate(self.trainSet):
test_moives = self.testSet.get(user, {})
rec_movies = self.recommend(user)
for movie, w in rec_movies:
if movie in test_moives:
hit += 1
all_rec_movies.add(movie)
rec_count += N
test_count += len(test_moives)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
print('precisioin=%.4f\trecall=%.4f\tcoverage=%.4f' % (precision, recall, coverage))
if __name__ == '__main__':
rating_file = '你的文件路径'
itemCF = ItemBasedCF()
itemCF.get_dataset(rating_file)
itemCF.calc_movie_sim()
itemCF.evaluate()
在计算用户活跃度时,活跃用户对物品相似度的贡献应该不高于不活跃的用户,这是因为一个用户可能是狂热电影爱好者,他观看了大量的电影,电影之间并无明显的相似程度。这里我们可以使用导数进行修正。
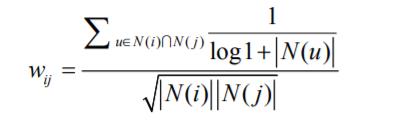
在计算用户相似度矩阵时,可以对其归一化:
一般来说物品总是属于某一类,如果存在一个热门的类,其中又有一个热门的物品,如果不进行归一化,则该物品很有可能有一个很大的权重,归一化可以提高推荐的多样性。
本文参考链接
https://github.com/xingzhexiaozhu/MovieRecommendation
本篇介绍了itemCF的算法原理,下篇会介绍其同门师兄弟userCF,以及师兄弟的比较。期待大家的持续关注!
以上是关于专栏1-推荐系统基于物品的协同过滤算法的主要内容,如果未能解决你的问题,请参考以下文章