推荐系统介绍一
Posted 郭老师统计小课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统介绍一相关的知识,希望对你有一定的参考价值。
注:本文是史宏炜对推荐系统的介绍
作为个性化时代互联网的核心应用技术,推荐、搜索和广告一直是工业界技术研发与创新的主战场,也是巨头公司如谷歌、亚马逊、阿里巴巴等重兵投入打造的技术护城河。
这是一个生活处处被推荐系统影响的时代。想上网购物,推荐系统会帮你挑选满意的商品;想了解资讯,推荐系统会为你准备感兴趣的新闻;想学习充电,推荐系统会为你提供适合你的课程;想消遣放松,推荐系统会为你奉上让你欲罢不能的短视频;想闭目养神,推荐系统会给你播放应景的音乐,可以说,推荐系统从来没有像现在这样影响着人们的生活。
当我们打开手机app,会发现推荐无处不在:从淘宝、京东、拼多多等电商,到美团、大众、饿了么等本地生活。在抖音、快手、B站等泛娱乐化平台,推荐系统是其“中流砥柱”,是吸引用户、提升用户留存的关键。本次我们主要结合一些简单案例介绍推荐系统的主要架构和基本算法的原理,在具体数据上用Python进行算法的实现。
什么是推荐系统
-
维基百科的定义:推荐系统是一种 信息过滤系统,用于预测用户对物品的评分或偏好。
我们可以换个角度来理解:
它能做什么?
它可以把那些最终会在用户和物品之间产生的连接找出来。世间的万事万物都有连接,人与人之间的社会连接促进了社交产品的诞生,人与商品之间的消费连接造就了无数的电商产品,人和资讯越来越多的阅读连接促使了各类信息流产品的出现。
它需要什么?
推荐系统需要已经存在的连接,去预测未来的连接。比如电商平台会根据你买过什么,浏览过什么这些人和商品之间的连接来预测你还可能会买什么,又比如你在使用今日头条时每一次点击,每一次阅读都是连接,根据已有过去的点击、浏览行为来预测你感兴趣的内容。
它是怎么做的呢?
维基百科的定义已经解释了:预测用户评分和偏好,他们对应了推荐系统背后相关算法和技术的两大类别,还有更抽象的分类:机器推荐和人工推荐,也是我们常说的个性化推荐和编辑推荐。
它解决的是什么问题?
信息过载和长尾问题(长尾理论)。随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代走入了信息过载的时代。消费者想从大量信息(物品)中找到自己感兴趣的信息,信息生产者想让自己生产的信息脱颖而出从而得到关注都是一件很难的问题
推荐系统的任务就是连接用户和信息(物品)。同时推荐系统要解决的另一个问题是需要发掘用户的行为,找到用户的个性化需求,从而将长尾商品准确的推荐给需要它的用户,同时帮助用户发现那些他们感兴趣但是很难发现的商品。
-
常见的推荐栏位例如:淘宝的猜你喜欢、看了又看、推荐商品,美团的首页推荐、附近推荐等。
-
推荐系统是比较偏向于工程类的系统,要做得更加的精确,需要的不仅仅是推荐算法,还有用户意图识别、文本分析、行为分析等,是一个综合性很强的系统。
推荐系统的作用和意义
推荐系统的作用和意义可以从用户和公司两个角度来阐述:
-
用户角度:推荐系统解决在“信息过载”的情况下,用户如何高效获取感兴趣信息的问题。
互联网拥有海量的信息,因此互联网可以说是推荐系统的最佳应用场景,在用户的角度来看,推荐系统是在用户需求并不十分明确的情况下进行信息的过滤,与搜索系统(用户会输入明确的“搜索词”)相比,推荐系统更多的利用用户的各类历史信息“猜测”其可能喜欢的内容。
-
公司角度:推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户黏性、提高用户转化率的问题,从而达到公司商业目标连续增长的目的。
不同业务模式的公司定义的具体推荐系统优化目标不同。例如视频类公司更注重用户的观看时长;电商类公司更重视用户的购买转化率(CVR),新闻类公司更注重用户的点击率等。
推荐系统的架构
-
推荐系统要解决的“用户痛点”是用户如何在“信息过载”的情况下高效地获得感兴趣的信息,这就是推荐系统要解决的基础问题:即推荐系统要 解决“人”和“信息”的关系。
这里的“信息”,在商品推荐中指“商品信息”,视频推荐中指“视频信息”,新闻推荐中指“新闻信息”,等等这些可以统称为物品信息。
与人相关的信息,包括历史行为,人口属性,关系网络等,这些统称为用户信息。
在一些具体的推荐场景中,用户的最终选择受时间、地点、用户的状态等一系列环境信息的影响,成为场景信息或上下文信息。
推荐系统的逻辑框架
-
推荐系统要处理的问题可以较形式化地定义为:对于用户 (user),在特定场景 (context) 下,针对海量的物品信息,构建一个函数 ,预测用户对特定候选物品 (item) 的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。 -
可以得到抽象的推荐系统逻辑框架:
推荐系统的技术架构
-
在实际的推荐系统中,工程师需要将抽象的概念和模块具体化、工程化,在构建好逻辑框架的基础上,工程师们需要着重解决的问题有两类:
-
数据和信息相关的问题:即用户信息,物品信息和场景信息分别是什么?如何存储、更新和处理? -
推荐系统算法和模型相关的问题:推荐模型图和训练、如何预测、如何达成更好的推荐效果?
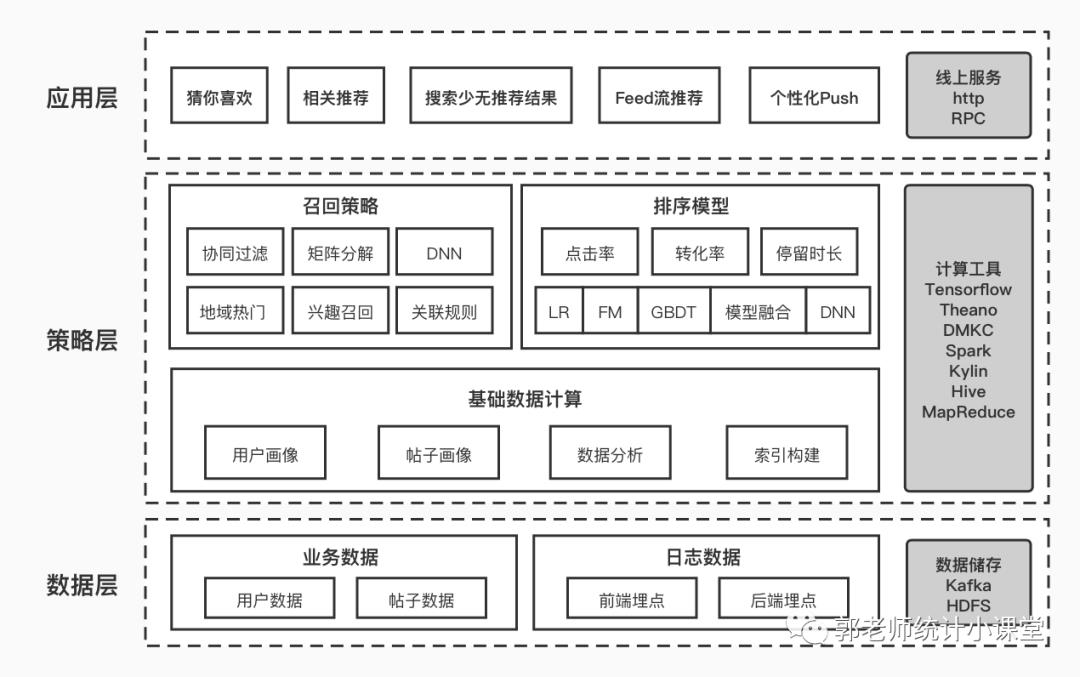
以下是推荐系统的技术架构示意图:
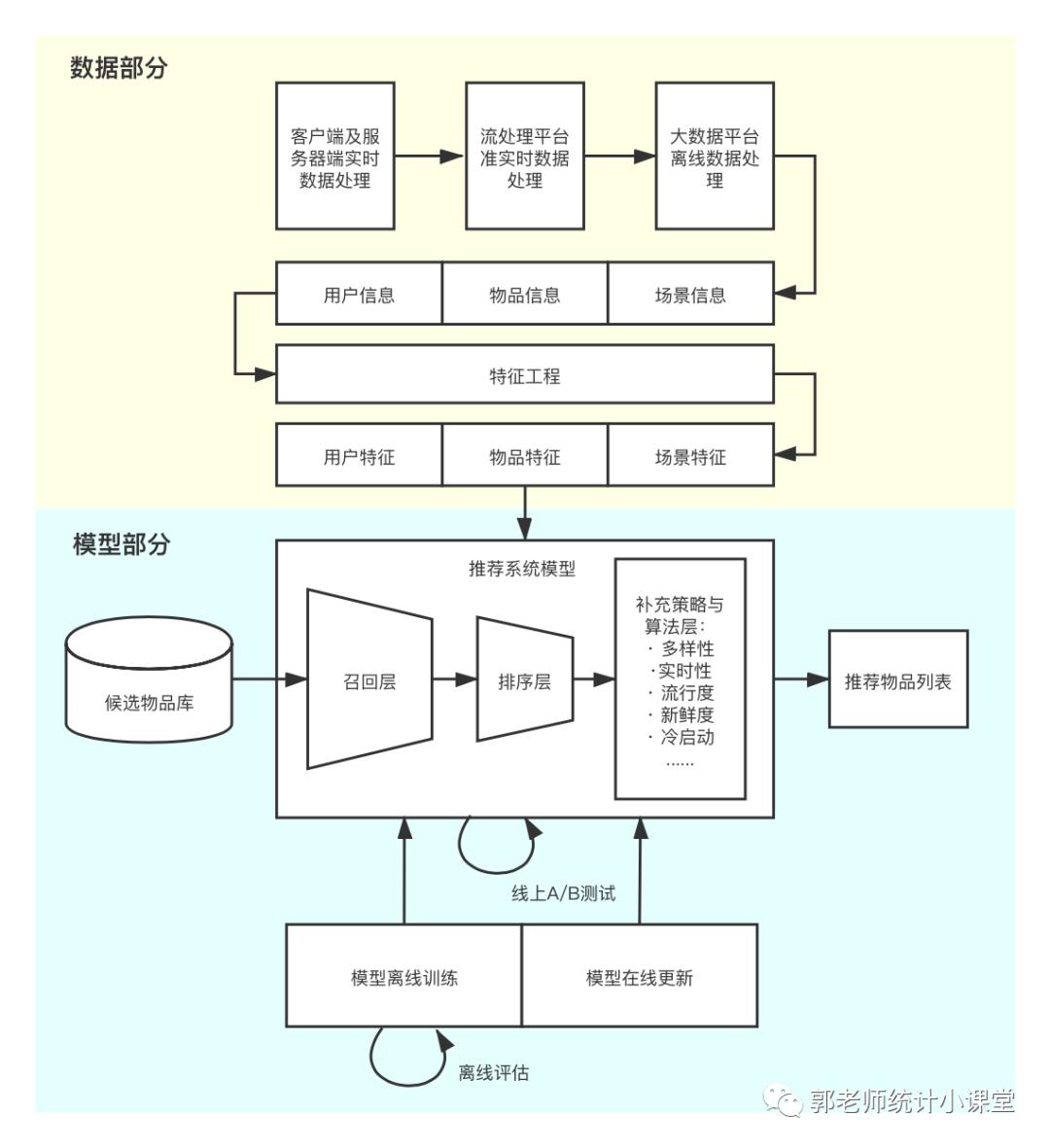
以下是推荐系统详细架构:
推荐系统的数据部分
-
推荐系统的数据部分主要负责 用户、 物品、 场景信息的收集和处理。 -
负责数据收集与处理的三种平台按照实时性的强弱顺序排序,依次是: -
客户端及服务器端实时数据处理 -
流处理平台准实时数据处理 -
大数据平台离线数据处理 -
实时性由强到弱递减的同时,三种平台的海量数据 处理能力由弱到强。
得到原始数据信息后,推荐系统的数据处理系统会将原始数据进一步加工,加工后的数据出口主要有三个:
生成推荐模型所需的样本数据,用于 算法模型的训练和评估; 生成推荐模型服务(model serving)所需的“特征”,用于 推荐系统的线上推断; 生成系统监控、商业智能(Business Intelligence,BI)系统所需的 统计型数据。
推荐系统的模型部分
-
模型部分是推荐系统的 主体,模型的结构一般是由 召回层、 排序层、 补充策略与算法层组成。
召回层:一般利用高效的召回规则、算法或者简单的模型,快速从海量的候选集中召回用户可能感兴趣的物品。
排序层:利用排序模型对初筛的候选集进行精排序。
补充策略与算法层:也称为再排序层,在推荐列表返回用户之前,为兼顾结果的多样性、流行度、新鲜度等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终推荐给用户。
-
在模型服务之前,需要通过 模型训练确定模型的结构、结构中不同参数权重的具体数值,以及模型相关算法和策略中的参数取值。
模型训练根据训练环境不同分为:离线训练和在线训练
离线训练: 特点是可以利用全量样本和特征,是模型逼近全局最优点
在线训练: 可以实时地“消化”新的数据样本,更快地反映新的数据变化趋势,满足模型实时性的需求。
-
为了 评估推荐模型的效果,方便模型的迭代优化,推荐系统的模型部分提供了 离线评估和 线上A/B测试等多种评估模块,得出 线下和线上评估指标,知道下一步模型的迭代优化。
推荐系统进化之路
-
推荐系统的发展可谓是一日千里,从2010年之前千篇一律的协同过滤 (Collaborative Filtering, CF)、逻辑回归 (Logistic Regression, LR),进化到因子分解机 (Factorization Machine, FM)、梯度提升树 (Gradient Boosting Decision Tree, GBDT),再到2015年之后深度学习推荐模型的百花齐放,各种模型框架层出不穷。 -
即使在深度学习空前流行的今天,协同过滤、逻辑回归、因子分解机等传统推荐模型仍凭借其 -
可解释性强、 硬件环境要求低、 易于快速训练和部署等不可替代的优势,拥有大量适用的应用场景; -
并且 传统推荐模型是深度学习推荐模型的基础;
因此我们这里主要介绍传统推荐系统的演化之路。
-
首先为大家展示传统推荐模型的演化关系图,作为我们整个介绍的索引:
推荐系统的发展脉络主要有以下几部分:
1. 协同过滤算法族
从物品相似度合用户相似度的角度出发,协同过滤衍生出 物品协同过滤 (ItemCF) 和 用户协同过滤 (UserCF) 为了使协同过滤能够更好地 处理稀疏共现矩阵问题、增强模型泛化能力,从协同过滤衍生出矩阵分解模型 (Matrix Factorization, MF)以及各种分支模型。
2. 逻辑回归模型族
与协同过滤仅利用用户和物品之间的显式或隐式反馈信息相比,逻辑回归能够利用和 融合更多用户、物品和上下文特征。
3. 因子分解机模型族
在传统逻辑回归的基础上,加入了二阶的部分,使模型具备了进行 特征组合的能力。 在因子分解机的基础上发展了 域感知因子分解机 (Field-aware Factorization Machine, FFM),通过加入 特征域的概念,进一步 加强因子分解机特征交叉的能力。
4. 组合模型
为了 融合多个模型的优点,将不同模型组合使用是构建推荐模型常用的方法。 Facebook提出 GBDT+LR组合模型是在工业界影响力较大的组合方式。 组合模型体现出的 特征工程模型化的思想,也成为深度学习推荐模型的引子和核心思想之一。
参考资料
-
项亮《推荐系统实践》 -
王喆《深度学习推荐系统》 -
https://zhuanlan.zhihu.com/p/76531750
以上是关于推荐系统介绍一的主要内容,如果未能解决你的问题,请参考以下文章